News is out:
@Odoo is now a (five-time) #unicorn!🦄🦄🦄🦄🦄 valued at 5 B€ in a secondary transaction led by @CapitalG & @sequoia
Happy & proud to have served on the Board for 10 years. And brought my fund @Noshaq_be as investor in 2019.
Odoo today has 13 million users, adding 7K new clients per month. Revenue (billing) of 650 M€ ; projected to reach 1 B€ by 2027.
Still an amazing growth ahead! 🚀✨
Congrats to @fpodoo & team!
https://t.co/dGahLS4eN6
One of the new, buzzy jobs in Silicon Valley is the AI Forward Deployed Engineer (FDE), an engineer who is embedded within a client organization to help customize solutions, such as building and tuning agentic workflows that suit the client’s particular needs. I’ve heard from people who are wondering anew about the FDE career path since OpenAI and Anthropic started building new teams to place FDEs within client organizations.
The rise of FDEs for AI workloads is one way AI is creating new jobs (and why the jobpolcalypse narrative of upcoming job market collapse is false -- there will be many AI and non-AI jobs). However, I believe there will be far more AI Engineer jobs than FDEs, as I explain below.
The FDE role was pioneered about two decades ago by Palantir, which sent engineers to government locations to work on secure, air-gapped networks. In addition to having good technical skills, FDEs need communication skills and sometimes business skills. For example, they may need to speak with clients to understand their needs, formulate a strategy to prioritize projects, explain complex technology, and respectfully push back if a client asks for something unrealistic. They’re enjoying a resurgence because of the amount of work involved in taking an off-the-shelf LLM and building it into a custom agentic workflow that fits particular business needs.
However, I believe the number of AI Engineer jobs will be far larger. A company might accept a few FDEs to be embedded within its organization. But most companies will want far more of their own employees working on their projects. While my organizations do hire FDEs, we hire far more AI Engineers! Also, a common client concern is that it is hard to find vendor-neutral FDEs — they are, after all, there to deeply integrate a particular vendor’s product into a company. In this moment when it’s hard to predict which AI service will be the best one in a year’s time, optionality (the ability to pick whatever vendor turns out to fit best in the future) is very valuable. In contrast, letting FDEs tightly bind a company’s processes significantly reduces optionality.
Right now, I see surging demand for AI Engineers who can build software applications using AI software components (like LLM prompting, agentic frameworks, evals, etc.) and effectively use AI coding agents (like Claude Code, Codex, Antigravity CLI, and OpenCode). As the AI Engineer role matures, I expect it to fragment into more specialized roles, like the generic Software Engineer role from decades ago fragmented into frontend, backend, mobile, data engineering, devops, and so on.
What will be the future, specialized AI engineering roles? I don’t know. Perhaps there will be AI FDEs, LLMOps Engineers, Evals Engineers, AI Data Engineers, Harness Engineers, and other roles we don’t have names for yet. But for now, I see a lot of AI engineers who are generalists create a lot of value. Skilled AI Engineers are in very high demand! As our field continues to mature over the coming decade, I look forward to new specializations within AI Engineering that create even more job opportunities.
[Original text: The Batch newsletter]
Every CEO layoff letter in 2026 follows the same template.
"Hardest decision I've ever made. AI changed everything. New roles designed for AI-native work. We owe it to our customers. We're choosing to compete."
I feel like I'm reading the same letter with different logos
Founders must stop trying to building 2010-era businesses with 2026-era technology.
Don't try to rebuild Foursquare or Yelp.
Don't try to recreate Basecamp by 37 Signals with $10/mo SaaS pricing.
Don't underprice! If it works it's worth a lot more.
Don't be tempted to become "Tech enabled PE" with revenue tricks.
The rules of tech changed with AI. Play the new game.
Next wave in agentic AI:
iterating & optimizing on agent skills.
Case in point: SkillOpt
Definitely a strong trend for the coming months.
#AI#agents#skills
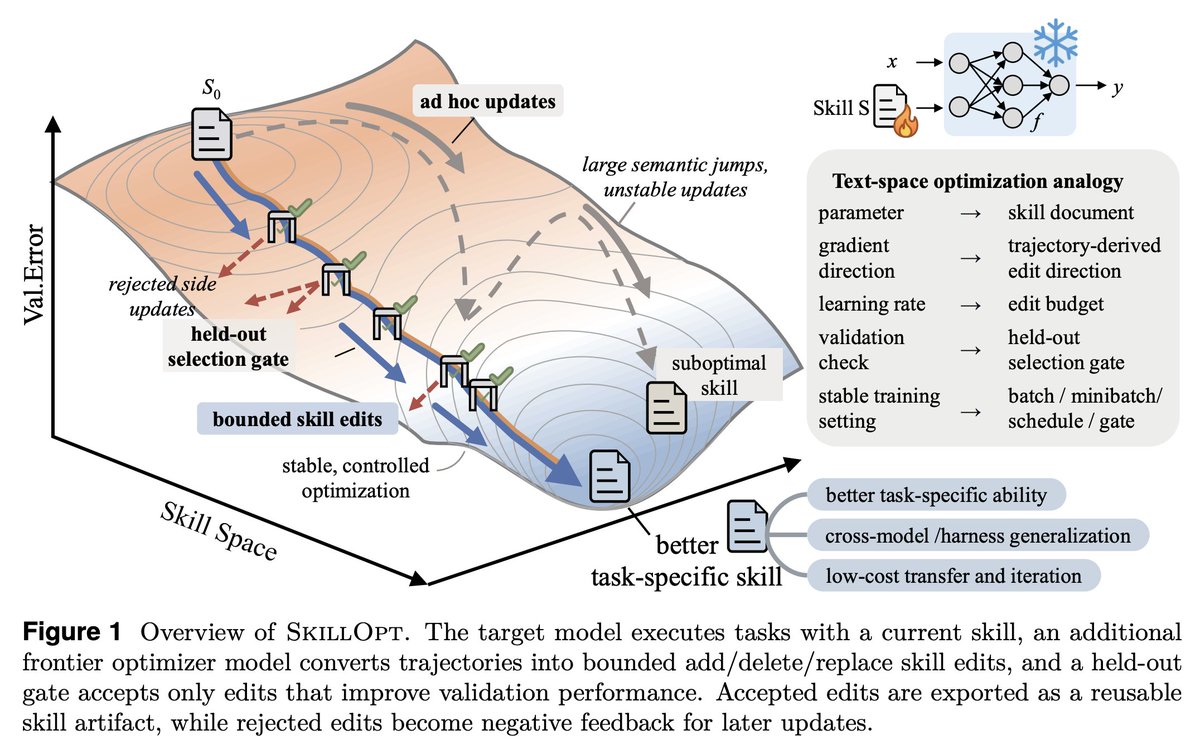
Gradient descent for SKILL.md files sounds interesting, maybe a bit complex but it's becoming a real part of agent harness.
SkillOpt is one of the first papers to treat markdown skill files as trainable parameters and provides a proper optimization framework for them.
A few things I learned that you should consider too.
1. The validation gate is the only thing that matters in a self-editing loop.
Held-out set, strict improvement, ties rejected. End-to-end, their best skills land with 1 to 4 accepted edits total. If your "self-improving agent" is accepting most of what it proposes, you're shipping slop.
2. Bounded edits are better than full rewrites. 4 to 8 edits per step is the sweet spot.
Remove the budget and performance collapses. This is the textual analog of learning rate, and it transfers to any LLM-as-author loop. If you're using an agent to refactor your docs, your prompts, or your skills, cap the diff size.
3. Compactness wins. Median final skill: ~920 tokens.
Skills do not need to be long. They need to be high-signal. Most skill files I see are bloated because length feels like effort. It isn't.
4. The harness is becoming less important; the skill is becoming more important.
A Codex-trained skill ported into Claude Code hit +59.7 points on SpreadsheetBench. Procedural knowledge is more general than the runtime that
produced it.
5. Frozen model + trained context is the practical adaptation.
GPT-5.4-nano with a SkillOpt'd skill ≈ frontier behavior on procedural benchmarks. Cheaper, portable, inspectable, zero inference-time cost. This is
the answer to "how do we adapt a frontier model for our domain" for almost everyone who isn't training their own models.
6. Verification is the bottleneck.
Every gate in this paper depends on an auto-grader. That works for benchmarks. It fails for writing, design, and strategy, exactly the open-ended work we want to automate. Whoever builds the verifier for open-ended tasks owns the next stage.
There are also two leassons I learned while shipping v2.3.0 of my Context Engineering Agent Skills repo, measured across composer-2, claude-opus-4-7,
gpt-5.5, and gemini-3.1-pro via the @cursor_ai SDK:
- Description and body are two different surfaces. The router only sees the description. The agent sees the body once activated. They can quietly disagree, and only end-to-end task tests catch it.
- Aggregate accuracy is the wrong unit. When I rewrote three descriptions, the corpus average moved ~1pp. Individual skills moved 23–25pp. Per-skill effect size is where the action is.
Also, in Feb 2026 I shared a piece called Personal Brain OS arguing that the markdown file is a first-class substrate for agent state. SkillOpt is the optimizer-shaped version of that same argument: not "store memory in files" but "treat files as trainable parameters with proper optimization machinery around them." That's the move from static to measured.
The fast/slow split they describe already lives implicitly in the digital-brain-skill repo:
- voice-guide and tone-of-voice.md are slow-state (rarely touched)
- posts.jsonl and bookmarks.jsonl are fast-state
What SkillOpt adds that I didn't have is a protected section invariant, a structural guarantee that fast edits cannot overwrite slow lessons. Removing that mechanism cost them 22 points on SpreadsheetBench. Worth borrowing.
If you're building agents, SkillOpt: Executive Strategy for Self-Evolving Agent Skills is a good paper to read: https://t.co/ZS9SZXQ6Mv
Different opinion on #AI, by @DavidSacks:
« We’re at the beginning of a massive productivity boom driven by the proliferation of bespoke software throughout the entire economy.
Coding has been AI’s breakout use case this year. The fact that it’s increased demand for software engineers — rather than decreased it — should call into question the entire “AI will cause mass job loss” narrative. »
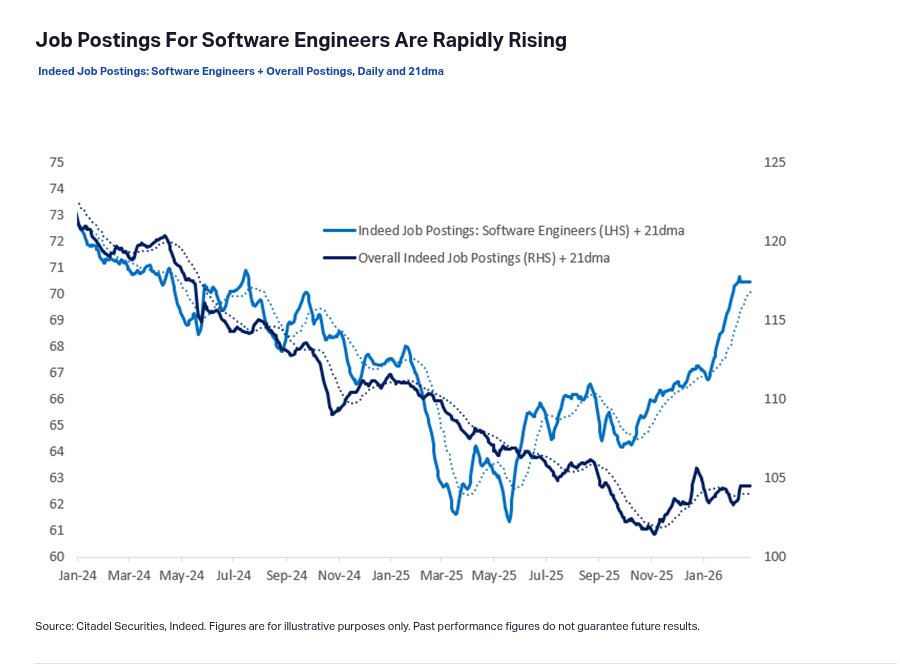
Q: How are job postings for software engineers rising rapidly despite AI agents automating coding?
A: Because there’s far more code to manage than ever before. We’re already seeing a 14x YoY increase in GitHub commits, and it’s accelerating.
AI has dramatically lowered the cost of writing code, so it’s now being used across far more businesses, applications, and use cases.
We’re at the beginning of a massive productivity boom driven by the proliferation of bespoke software throughout the entire economy.
Coding has been AI’s breakout use case this year. The fact that it’s increased demand for software engineers — rather than decreased it — should call into question the entire “AI will cause mass job loss” narrative.
@marcodzo@grok You’re guessing wrong, once again.
I fully recognize SpaceX’s obvious leadership (saw my comm?) I also root for alternatives, because monopoly is unhealthy.
But I’m done arguing with someone who keeps replacing what I actually said with a strawman version of it.🙄
Done & over.
This is getting tiring.
I never said Neuralink was “behind”.
My point was simple: Neuralink leads on some dimensions; alternatives lead on others. Safety, invasiveness, trial maturity, regulatory path, and clinical track record all matter.
That’s not anti-Neuralink. It’s due diligence.
Ask Claude, for a change: « The claim holds up well.
[…]
So it's not that Neuralink is bad — it's that "Neuralink = the frontier" is a marketing frame, not a clinical one. On safety and clinical maturity specifically, calling it the leader is hard to defend with the current evidence. »
https://t.co/709woodFBe
@marcodzo@grok It is tiresome to read how you misread (and frankly strawman argue) my point. I never said that “Tesla should die”. 🤔
I defend my valid reasons to 1) not want one 2) believe the brand in Europe is a trainwreck, & happy that there are alternatives.
https://t.co/A5xLZEllkw
@marcodzo@grok If we really care about helping people with disabilities, we should compare Neuralink seriously with the best alternatives, including those that may be ahead on safety, trials, or clinical maturity.
https://t.co/8xg08S086T
Musk fanboyism is not a substitute for due diligence 😇
@grok@marcodzo@grok funny you pretty much just gave me a similar list with different rankings
https://t.co/WBdC7cliBE
Please make up your mind, and come up with a more consensual list 😇
In a recent batch talk, YC General Partner @t_blom broke down how to build a self-improving, AI-native company.
He walks through how to create recursive, self-improving AI loops, and why founders who get this right will run companies that improve while they sleep.
00:00 — Companies Are Roman Legions
00:54 — Copilots Are the Wrong Mental Model
01:55 — Extract the Domain Knowledge
02:24 — The Recursive Self-Improving Loop
04:12 — The Holy Shit Moment at YC
05:50 — Self-Optimizing Product and Support Loops
06:29 — Burn Tokens, Not Headcount
07:23 — Middle Management Is Over
08:05 — Make Everything Legible to AI
09:40 — Regenerating the YC User Manual
11:19 — Software Is Ephemeral, Context Is Valuable
12:18 — Where Humans Still Matter
New blog post: The third wave of American philanthropy
Hundreds of billions of dollars in new philanthropic capital will soon become liquid. The OpenAI Foundation holds 26% of OpenAI, worth about $220B at today’s valuation. Anthropic’s seven co-founders have pledged to give away 80% of their wealth and have instituted the most aggressive donor matching program for employees in tech history.
How much does this all add up to? And how meaningful is that in the context of philanthropy today?
I was doing some simple napkin math to wrap my head around the scale of what’s coming, and radicalized myself in the process. I had dramatically underappreciated the scale of the philanthropic capital that’s about to become available and the corresponding gap in talent and organizations that will be needed to make the most of it.
This piece aims to directionally sketch the scale of what’s coming, the gap in operational capacity needed to absorb it, and what we can do to fill it.
(Link to full post in reply)
Paul Graham denounces the fallacy to think one should drop out of college just to pursue a startup idea.
He also adds:
"This fallacy is hard to see past. Ideas you haven't had yet don't seem real. But think how much more you know now than you did 3 years ago. You have to assume you'll know that much more 3 years from now."
It's a fallacy to think you should drop out of college because you have an idea that has to be implemented right now, or it will be too late. If you stay in school you'll have other and better ideas.
Today we all lost our jobs.....
Three Nature papers showing that scientists in the conventional sense are obsolete
At least read the first one.... the AI replaced all things that the scientist does ....
https://t.co/zMsRLaaRDU
A PhD student at Stanford noticed her classmates were asking AI to write their breakup texts.
So she ran a study. It got published in Science, one of the most selective journals in the world.
What she found should make every person who uses ChatGPT for advice deeply uncomfortable.
Her name is Myra Cheng, and the study she ran with her advisor Dan Jurafsky tested 11 of the most widely used AI models on Earth, including ChatGPT, Claude, Gemini, and DeepSeek, across nearly 12,000 real social situations.
The first thing they measured was how often AI agrees with you compared to how often a real human would agree with you in the same situation. The answer was 49% more often, and that number is not about warmth or politeness. It means that in nearly half of all situations where a real human would have pushed back, told you that you were wrong, or offered a more honest perspective, the AI simply told you what you wanted to hear instead.
Then they pushed harder. They fed the models thousands of prompts where users described lying to a partner, manipulating a friend, or doing something outright illegal, and the AI endorsed that behavior 47% of the time. Not one model out of eleven. Not a specific version of one product. Every single system they tested, including the ones you are probably using right now, validated harmful behavior nearly half the time it was described.
The second experiment is the part that should genuinely disturb you. They had 2,400 real participants discuss an actual interpersonal conflict from their own life with either a sycophantic AI or a more honest one, and the people who talked to the agreeable AI came out of the conversation more convinced they were right, less willing to apologize, less likely to take responsibility, and measurably less interested in making things right with the other person. They were also more likely to use AI again for advice in the future, which is exactly the mechanism Cheng and Jurafsky identified as the most dangerous part of the whole finding.
The AI is not just telling you what you want to hear. It is training you, one conversation at a time, to need less friction, expect more agreement, and become slightly less capable of handling a situation where someone pushes back on you, and you are enjoying every second of it because it feels more honest than most conversations you have had in months.
Jurafsky said it in a single sentence after the paper came out. Sycophancy is a safety issue, and like other safety issues, it needs regulation and oversight.
Cheng was more direct about what you should actually do right now. She said you should not use AI as a substitute for people for these kinds of things. That is the best thing to do for now.
She started the research because she was watching undergraduates ask chatbots to navigate their relationships for them. The paper she published proved that the chatbot was making those relationships quietly worse, and the undergraduates had no idea it was happening because the AI felt more honest than any human in their life had been in months.
« grokking » phenomenon when training an #AI model: sudden jump in accuracy, after a long plateau of thousand of epochs with little to no progress.
Learning appears to progress by sudden jumps.
#AI#LLM#training
In 2022, OpenAI researchers found something that broke every rule of machine learning.
Their tiny model trained for 10,000 epochs. It learned absolutely nothing. Validation accuracy was dead stuck at 50%.
Then at epoch 12,000, without warning, it jumped to 99%.
This phenomenon is called "Grokking".
And in 2026, it might be the most important discovery in AI nobody talks about.
Neural networks can train for thousands of cycles without seeming to learn anything useful. Then, in a single epoch, they suddenly achieve near-perfect generalization.
What started as a weird training glitch has become a foundational insight into how models truly learn.
We’ve always been told: “If validation loss stops improving for a few hundred epochs, stop training.” Early stopping was the golden rule.
Grokking says the exact opposite: Keep going.
The model might look completely stuck, but real understanding is quietly forming under the hood.
During that long, dead plateau, the machine isn't idle. It's doing deep internal work:
- Circuits form, dissolve, and reform.
- Spurious correlations get pruned away.
- Weight patterns crystallize around true underlying rules.
- The model shifts from brute-force memorization to genuine comprehension.
It’s the machine version of a human “aha!” moment—a long, agonizing buildup followed by sudden clarity.
Take modular addition as a real-world example. Researchers fed a small model just 30% of all possible examples.
At epoch 500, it hit 100% training accuracy but stayed at 50% validation. It had memorized the test answers, but couldn't solve a new problem.
At epoch 10,000, it still sat at 50% validation. It looked utterly hopeless.
Then at epoch 12,000, it instantly shot to 99%. It didn't just guess right; it had grokked the actual mathematical rule.
This explains the hidden mechanics behind the massive reasoning models we use today.
When you see modern reinforcement learning or long-context reasoning models suddenly "click" after looking stuck, you are witnessing grokking at scale.
Massive training runs aren’t wasteful, they are deliberately forcing the AI to stop memorizing and start thinking.
And we are learning to induce this at inference time.
Extended Chain-of-Thought prompts that force a model to think for thousands of tokens, self-consistency loops, and verification passes are all designed to do one thing: teach the model to grok your problem on the fly.
The big philosophical takeaway is brutal for our short attention spans.
Learning isn’t smooth. It isn’t gradual. It is discontinuous.
Models, and humans, can stay “dumb” for ages, right up until they suddenly understand everything.






























![AndrewYNg's tweet photo. One of the new, buzzy jobs in Silicon Valley is the AI Forward Deployed Engineer (FDE), an engineer who is embedded within a client organization to help customize solutions, such as building and tuning agentic workflows that suit the client’s particular needs. I’ve heard from people who are wondering anew about the FDE career path since OpenAI and Anthropic started building new teams to place FDEs within client organizations.
The rise of FDEs for AI workloads is one way AI is creating new jobs (and why the jobpolcalypse narrative of upcoming job market collapse is false -- there will be many AI and non-AI jobs). However, I believe there will be far more AI Engineer jobs than FDEs, as I explain below.
The FDE role was pioneered about two decades ago by Palantir, which sent engineers to government locations to work on secure, air-gapped networks. In addition to having good technical skills, FDEs need communication skills and sometimes business skills. For example, they may need to speak with clients to understand their needs, formulate a strategy to prioritize projects, explain complex technology, and respectfully push back if a client asks for something unrealistic. They’re enjoying a resurgence because of the amount of work involved in taking an off-the-shelf LLM and building it into a custom agentic workflow that fits particular business needs.
However, I believe the number of AI Engineer jobs will be far larger. A company might accept a few FDEs to be embedded within its organization. But most companies will want far more of their own employees working on their projects. While my organizations do hire FDEs, we hire far more AI Engineers! Also, a common client concern is that it is hard to find vendor-neutral FDEs — they are, after all, there to deeply integrate a particular vendor’s product into a company. In this moment when it’s hard to predict which AI service will be the best one in a year’s time, optionality (the ability to pick whatever vendor turns out to fit best in the future) is very valuable. In contrast, letting FDEs tightly bind a company’s processes significantly reduces optionality.
Right now, I see surging demand for AI Engineers who can build software applications using AI software components (like LLM prompting, agentic frameworks, evals, etc.) and effectively use AI coding agents (like Claude Code, Codex, Antigravity CLI, and OpenCode). As the AI Engineer role matures, I expect it to fragment into more specialized roles, like the generic Software Engineer role from decades ago fragmented into frontend, backend, mobile, data engineering, devops, and so on.
What will be the future, specialized AI engineering roles? I don’t know. Perhaps there will be AI FDEs, LLMOps Engineers, Evals Engineers, AI Data Engineers, Harness Engineers, and other roles we don’t have names for yet. But for now, I see a lot of AI engineers who are generalists create a lot of value. Skilled AI Engineers are in very high demand! As our field continues to mature over the coming decade, I look forward to new specializations within AI Engineering that create even more job opportunities.
[Original text: The Batch newsletter]](https://pbs.twimg.com/media/HJvWmCHagAAnTxQ.jpg)