Introducing Strong Stochastic Flow Maps
TLDR: Stochastic Flow Maps where we learn the stochastic solution path.
Work led by Sam McCallum, @zwblasingame, with Timothy Herschelll, @AlexanderTong7, and @JamesFosterBath
Arxiv: https://t.co/Hy8WWZOnjE
Code: https://t.co/PMe6RoqyZA
Reimagining Science for the AI Era. Listen to @beckypferdehirt CEO of Radial @AsteraInstitute discuss the $500M nonprofit seeking to create better conditions for AI in biology. Sponsors: @AlphaSenseInc Dash Bio. https://t.co/FBraq3no2Z
Binder design has come of age thanks to generative models—but how can we access the wider array of dynamic, multistate protein functions, so elegantly employed by nature?
@mihirbafna14 and I are excited to share SwitchCraft, a framework for designing such functions. (1/7)
The Magnetobiology Episode:
A company in San Francisco, called @NonfictionBio, is building proteins (like antibodies and enzymes) that can be controlled using small magnets.
In this episode, co-founder Maria Ingaramo and scientific advisor Andrew York explain how they engineered a protein, MagLOV, that responds strongly to magnetic fields, why most prior attempts have failed to replicate, and how the mechanism of magnetically-controlled proteins actually works. They also get into the “dream” use cases, like cancer drugs that activate only at the tumor, which might have a lower toxicity inside the body. This podcast is made possible by @AsteraInstitute.
I'm happy with how this episode came out. I think my interviewing skills are improving, and I'm getting better at building up context throughout the episode. Enjoy!
Search for "The New Biology" on YouTube, Spotify, and Apple Podcasts.
Timestamps:
00:00 - Opening
00:54 — Introduction
01:35 — The dream
05:38 — Why magnets vs. light or ultrasound
10:05 — The physics
17:48 — On the name "magnetogenetics"
21:25 — Birds and cryptochromes
27:09 — Why is the field filled with so much junk?
29:51 — Adam Cohen's molecule
33:24 — Markus Meister’s debunking
38:06 — The experiment
46:22 — Finding the LOV domain
54:11 — Singlets, triplets, and cysteine
56:54 — What the magnet is actually doing
1:05:13 — The conformational-change red herring
1:12:46 — The Quantum Biology Institute
1:19:31 — Founding Nonfiction Labs
1:24:38 — How to convince skeptical investors
1:29:39 — What a magnetogenetic medicine might look like
1:38:50 — First clinical indications
1:45:12 — The regulatory path
1:48:01 — What the field needs
1:54:30 — Appendix: Whiteboard lecture
The DiffUSE Project wants examples where structural heterogeneity matters but cannot be encoded in PDBx/mmCIF. X-ray, cryo-EM, time-resolved, multi-map, or fragment screening data welcome. Submit yours: https://t.co/YNxYAzz23F
Every non-biotech person I describe Verve to is floored. They can't believe this is a future we get to live in - permanent solution for high cholesterol and strokes - even after I tell them it means editing their genes.
At the same time more than 90% of the biotech VCs I've talked to are bearish on exactly this direction.
"Why cure a disease if you can do monthly injections"
"Insurance would never cover cures"
I am excited for those people to not make any money when they are proven wrong. Its striking that no one sees that cures have been out of vogue for very silly reasons - we equated one-and-done to viral vectors, rare disease TAMs, and rare disease prices. None of those are relevant assumptions, and Lilly has multiple bets in this space to prove everyone wrong.
AlphaFold-like models such as Boltz-2 and AlphaFold3 learn powerful priors over structures from PDB. But how can we make them aware of new X-ray crystallography data?
Introducing CrystalBoltz: end-to-end X-ray structure determination via experiment-guided diffusion.
1/4 🧵
My biggest hot take for today is that everyone who works at the intersection of AI + protein structure should fit an atomic model to density in Coot at least once
Gives you a totally different perspective once you see where the data actually comes from
My first blog post in over a year is a deep dive on flow maps🗺️, or how to learn the integral of a diffusion model to enable faster sampling and several other cool tricks.
It's the longest one yet👀 Let me know what you think!
https://t.co/O8bBGZ9qjC
Statistical crystallography as a route to understanding protein dynamics! 1,146 crystal structures of SARS-CoV-2 Mpro reveal correlated motions connecting the dimer interface to the active site. Great to see this work out by the DESY team.
Link: https://t.co/6lClrhfzW8
Generative design of sequence specific DNA binding proteins.
Most fun paper I have ever written, with @enishasehgal and @YPolitansk15183 and the team, on a project which is a testament to the power of RFdiffusion3.
https://t.co/iYmdXRDBhQ
We, @hlws_bot@PilarCossio2@JiequnH, are sharing the official code release for EmbedOpt for seamless inference-time steering of protein diffusion models at https://t.co/iw12evQHeu,
featuring:
✨ Tutorial on a real CryoEM map (EMDB-63136) (check out the animation below!).
📦 Environment locked with pixi for zero-headache reproducibility.
🛠️ Fully compatible with the new Protenix 2.0 codebase.
📊 All scripts to reproduce the paper's benchmark results are included out-of-the-box.
We are also proud to host this under the Reciprocal Space Station (RSS, @open_rss)—our growing hub for open-source structural biology software! 🌌
Paper: https://t.co/ftdr0hA5Wx
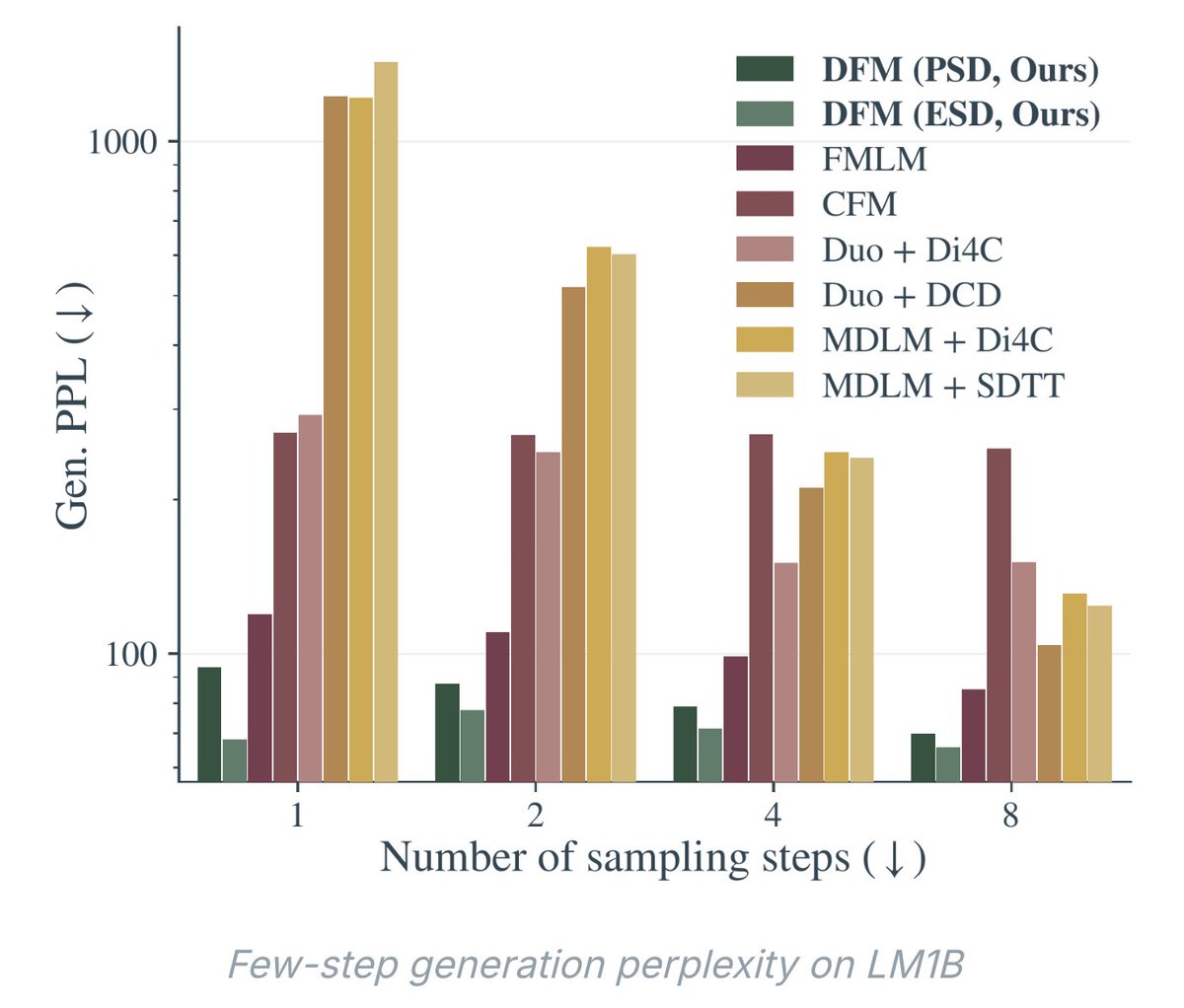
New paper! Presenting Discrete Flow Maps:
paper: https://t.co/f1RmZry2by
blog: https://t.co/Cnwgf4moY0
A laughable problem for me these days is that @nmboffi and I share a research brain, and we have had, time and again, a conversation that ends with “ha so I guess we’re writing the same paper.” Soon we will return to just doing it together :). Here we are doing it again with discrete flow maps and flow language models! A complete and thorough paper led by @PPotaptchik@json_yim@adhisarav@peholderrieth. We took a bit of time to post it to ensure we understood a few more things about the stability of the loss functions.
Like @osclsd , @FEijkelboom, and @nmboffi , we think this could be a very helpful paradigm for thinking about fast inference and even better alignment!
Here’s our version of the story, and I hope it makes clear how green field this research direction is — we provide a comprehensive picture of the KL losses you can write from the properties of the flow map, some nice geometric proofs about the mean denoiser and the simplex, and find that at this time, the ESD can actually be the most performant, with some caveats. Excited for everyone to work together and push this class of models to their limit!
🧵1/9 Flow maps have sped up sampling 100x, but can we speed up likelihoods too? 🚀
For scientific applications like Boltzmann Generators, fast samples aren't enough—you need exact likelihoods. That has been the major bottleneck.
Introducing FALCON 🦅: A solution for fast AND accurate likelihoods. 🧵👇
🔗: https://t.co/ru4NsEFwWR
👥: @tara_aksa @ag27182 @AlexanderTong7@Yoshua_Bengio@Mila_Quebec
Flow matching is emerging as a unifying framework for generative biology
Biology is full of mappings between states: a healthy cell turning diseased, amino acids folding into a functional protein, a ligand docking into its target. Deriving such transformations analytically is intractable—which is where generative AI steps in, and flow matching is quickly becoming its backbone.
Morehead and coauthors review how flow matching (FM) is reshaping generative modeling in bioinformatics. Unlike diffusion models, FM doesn't force the source distribution to be Gaussian: it learns a time-dependent vector field that transports samples between any two distributions along straight-line, optimal-transport paths. The payoff: fewer inference steps, simulation-free training, and built-in support for geometric priors like SE(3) equivariance—essential for 3D biomolecules.
What's striking is how fast FM has spread across biological scales. For molecules, FoldFlow, FrameFlow, and Multiflow generate protein backbones on SE(3)ᴺ manifolds, SemlaFlow produces valid small molecules up to 100× faster than diffusion, and Dirichlet FM handles discrete DNA/RNA sequences. FlowDock and NeuralPLexer3 predict protein–ligand complexes that match or exceed AlphaFold 3 on key benchmarks, while AlphaFlow and MDGen generate conformational ensembles and MD trajectories. At the cellular scale, CellFlow and Meta FM map unperturbed populations to perturbed states, and CryoFM and FlowSDF extend FM to cryo-EM and microscopy.
The deeper point: FM subsumes diffusion models, continuous normalizing flows, and optimal transport as special cases, providing scaffolding for an AI-based virtual cell—simulating molecular, structural, and phenotypic effects of perturbations across scales.
Overall, this signals a shift in what's computationally tractable. Instead of narrow, stage-specific models, FM points to unified conditional generators that design sequences, predict complexes, and model perturbation responses in one framework—shortening wet-lab cycles and making closed-loop, active-learning workflows practical.
Paper: Morehead and coauthors, Nature Machine Intelligence (2026) — Journal license | https://t.co/7UyfTWXKmS
We release Diamond Maps💎 unlocking accurate and efficient guidance for diffusion models. Our experiments show that our methods scale incredibly well. Excited to see what people will build with this!
Accurate guidance has been a notoriously hard problem, but in this work, we’re bringing TWO (!) solutions to the table. The recipe for success:
1️⃣ Speed: Use distilled models (flow maps, mean flows, consistency models).
2️⃣ Exploration: Inject stochasticity to properly explore your search space.
Because this fundamentally improves anything using flow matching and diffusion, we see a lot of potential for applications across audio, robotics, molecules, and beyond.
Paper: https://t.co/wxtWWRrnw7
Code: https://t.co/WocPtT6orn
Huge thanks to an amazing team: Douglas Chen, @LucaEyring, @ishin_shah, Giri Anantharaman, @electronickale, @zeynepakata, Tommi Jaakkola, @nmboffi, and @max_simchowitz. It was awesome bringing this to life together!
We’re still looking for a lot of folks for Open Science at Radial (within the @AsteraInstitute ecosystem) including a data steward, operations associate, as well as an engineer and product manager for the Stacks (https://t.co/5DNdQoe4DA) to work on our publishing platform. If you think any of these roles are a good fit for you, apply now!
https://t.co/ylu3NBsMGs