Combining discrete and continuous data is an important capability for generative models. To address this for protein design, we introduce Multiflow, a generative model for structure and sequence generation.
Preprint: https://t.co/wuj9l5sTLc
Code: https://t.co/IwIoC74Odm
1/8
Agree with the oversimplification of AI in DD. "Vertically integrated target-discovery company" is basically @Xaira_Thera . Super hard but the only way for flywheel value generation in this space. Need more bets like Xaira.
AI for Bio is hot again. Given that, I wrote a primer on why this field is so hard. tl;dr it's because the APIs are fuzzier than you might think.
https://t.co/jsfbWBt1cd
New paper! Presenting Discrete Flow Maps:
paper: https://t.co/f1RmZry2by
blog: https://t.co/Cnwgf4moY0
A laughable problem for me these days is that @nmboffi and I share a research brain, and we have had, time and again, a conversation that ends with “ha so I guess we’re writing the same paper.” Soon we will return to just doing it together :). Here we are doing it again with discrete flow maps and flow language models! A complete and thorough paper led by @PPotaptchik@json_yim@adhisarav@peholderrieth. We took a bit of time to post it to ensure we understood a few more things about the stability of the loss functions.
Like @osclsd , @FEijkelboom, and @nmboffi , we think this could be a very helpful paradigm for thinking about fast inference and even better alignment!
Here’s our version of the story, and I hope it makes clear how green field this research direction is — we provide a comprehensive picture of the KL losses you can write from the properties of the flow map, some nice geometric proofs about the mean denoiser and the simplex, and find that at this time, the ESD can actually be the most performant, with some caveats. Excited for everyone to work together and push this class of models to their limit!
We release Diamond Maps💎 unlocking accurate and efficient guidance for diffusion models. Our experiments show that our methods scale incredibly well. Excited to see what people will build with this!
Accurate guidance has been a notoriously hard problem, but in this work, we’re bringing TWO (!) solutions to the table. The recipe for success:
1️⃣ Speed: Use distilled models (flow maps, mean flows, consistency models).
2️⃣ Exploration: Inject stochasticity to properly explore your search space.
Because this fundamentally improves anything using flow matching and diffusion, we see a lot of potential for applications across audio, robotics, molecules, and beyond.
Paper: https://t.co/wxtWWRrnw7
Code: https://t.co/WocPtT6orn
Huge thanks to an amazing team: Douglas Chen, @LucaEyring, @ishin_shah, Giri Anantharaman, @electronickale, @zeynepakata, Tommi Jaakkola, @nmboffi, and @max_simchowitz. It was awesome bringing this to life together!
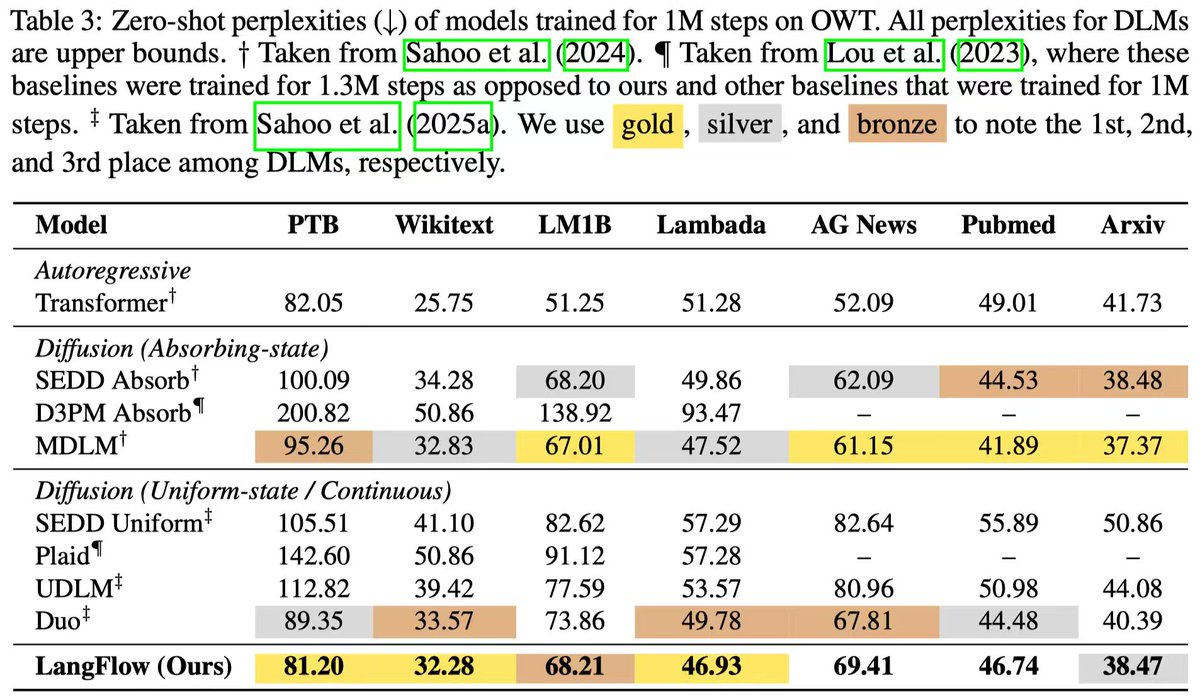
Love seeing the recent parade of breakthroughs in Diffusion LMs! 🎉 Here is what our lab is bringing to the party: Meet LangFlow 🌊: The first continuous diffusion language model that rivals discrete DLM. LangFlow achieves strong PPL and Gen PPL on LM1B and OpenWebText. It also outperforms the best discrete diffusion models on 3 out of 7 zero-shot transfer benchmarks, and beats autoregressive baselines on 4 out of 7!
Check out our paper below:
📄 Arxiv: https://t.co/sR5rSqPyrQ📝 Blog: https://t.co/4OYLOvTkyz💻 GitHub: https://t.co/hkE1Ak5rFA
What if AI could invent enzymes that nature hasn’t seen? 👩🔬🧑🔬
Introducing 🪩 DISCO: Diffusion for Sequence-structure CO-design
14 rounds of directed evolution and over a year of wet lab work. That's what it took to engineer an enzyme for selective C(sp³)–H insertion, one of the most challenging transformations in organic chemistry.
DISCO surpasses this with a single plate. No pre-specified catalytic residues, no template, no theozyme, no inverse folding, just joint diffusion over protein sequence and structure.
📝 Blog: https://t.co/j9Za0JigfO
📄 Paper: https://t.co/ficrYNBBrM
💻 Code: https://t.co/p81sSwoaPH
Protenix-v2: A Biomolecular Modeling System for Structure Prediction and Zero-Shot Antibody Design @ai4s_protenix
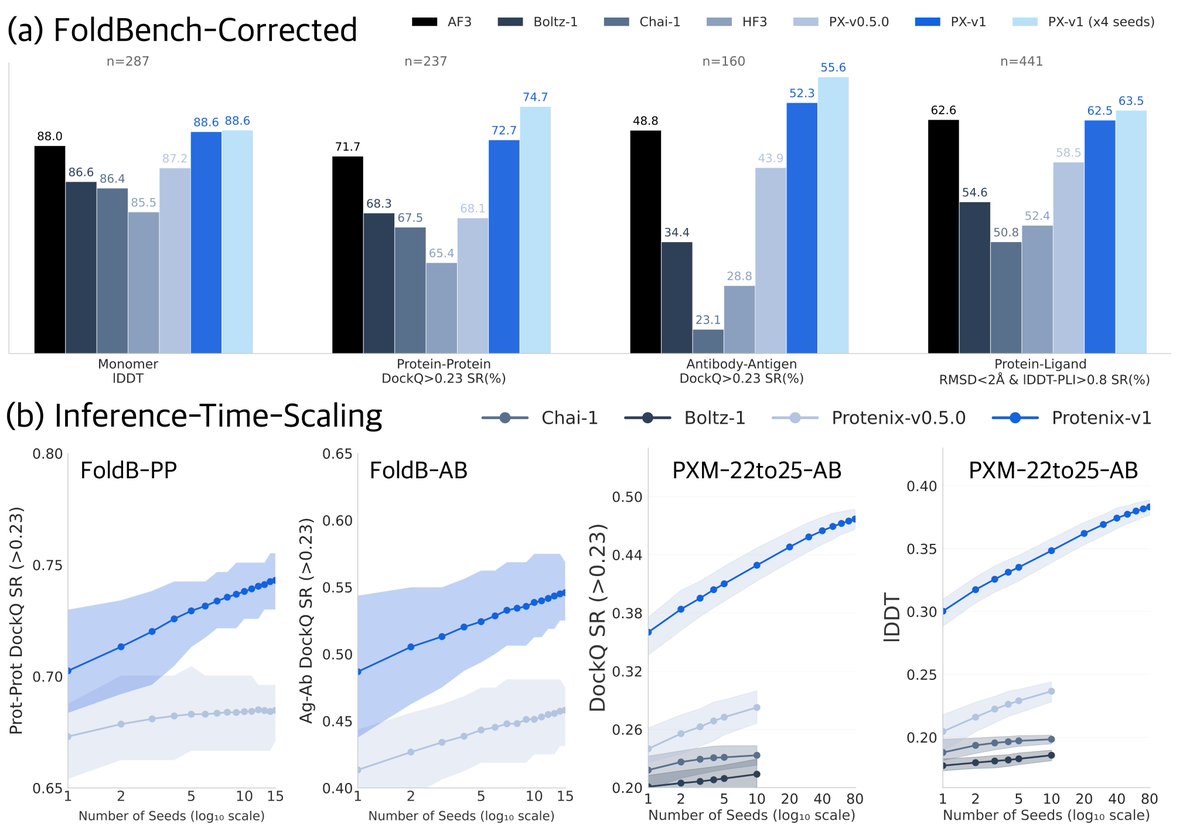
1. Protenix-v2 achieves massive gains in antibody-antigen structure prediction, with up to 13-point improvements over Protenix-v1 at DockQ >0.23 and comparable gains at the stricter DockQ >0.8 threshold. Most remarkably, its 5-seed performance surpasses previous 1000-seed results, representing a dramatic leap in sampling efficiency.
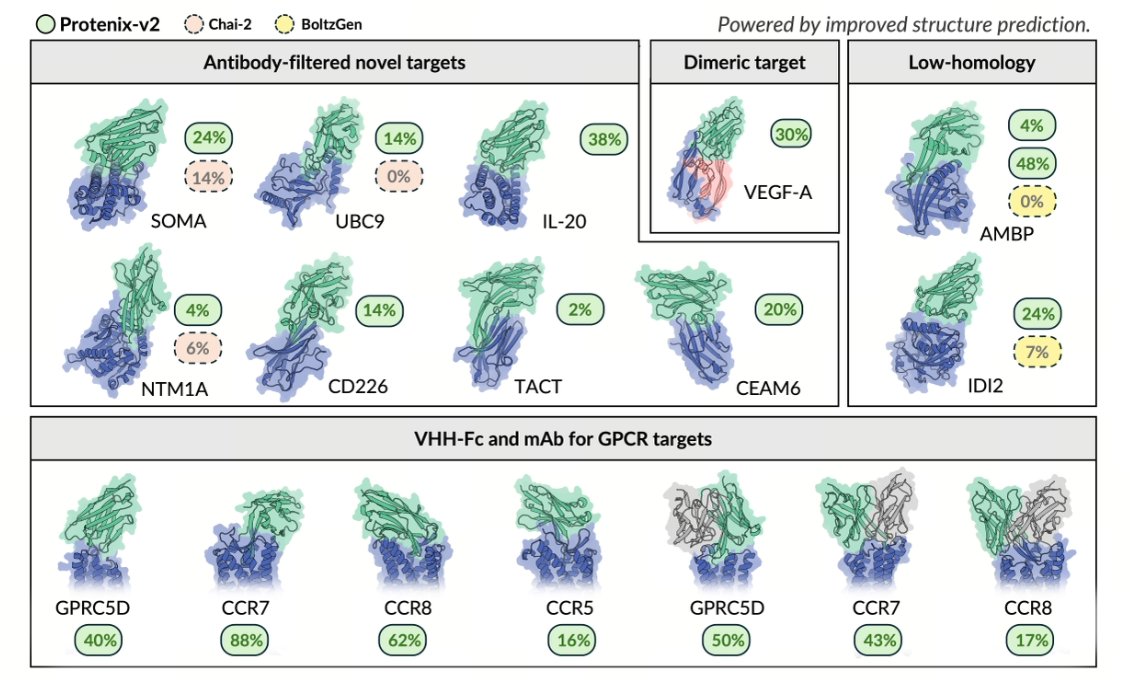
2. The system demonstrates 100% target-level success rate in zero-shot VHH antibody design across novelty-controlled targets, with BLI-confirmed hit rates ranging from 2% to 48%. The resulting hits show exceptional developability with 100% thermostability pass rate, 98% self-interaction pass rate, and 93% polyreactivity pass rate.
3. On challenging GPCR targets with small and flexible exposed epitopes, Protenix-v2 achieves hit rates of 16%-88% in VHH-Fc format and up to 50% in mAb format, despite testing only 16-30 designs per target. This demonstrates effective sample efficiency on difficult membrane proteins.
4. The model introduces training-free guidance (TFG) variants that significantly improve ligand-related plausibility, reaching 60.46% success rate on recent protein-ligand benchmarks under a revised stricter validity criterion that checks planarity around sp2 centers and non-planarity at sp3 centers.
5. Protenix-v2 successfully designs dual-specific binders against both prototype and Omicron SARS-CoV-2 RBD variants with nanomolar-scale KD, showing potential compensatory mechanisms at the structural level to accommodate sequence differences.
6. The system supports flexible, target-conditioned generation with granular control over CDR loop lengths and integration of predefined frameworks, spanning diverse formats from miniproteins to VHH and full-length antibodies.
💻Code: https://t.co/FuCrGAgYF6
📜Paper: https://t.co/nd2DHyDj4q
#ProtenixV2 #AntibodyDesign #StructurePrediction #AlphaFold3 #BiomolecularModeling #DrugDiscovery #GPCR #MachineLearning #ComputationalBiology #ZeroShotDesign
🤯 big update to our flow map language models paper!
we believe this is the future of non-autoregressive text generation.
read about it in the blog: https://t.co/DfBXrYmJc8
full details in the paper: https://t.co/coiNXj4ucC
we introduce a new class of continuous flow-based language models and distill them into their corresponding flow map for one-step text generation.
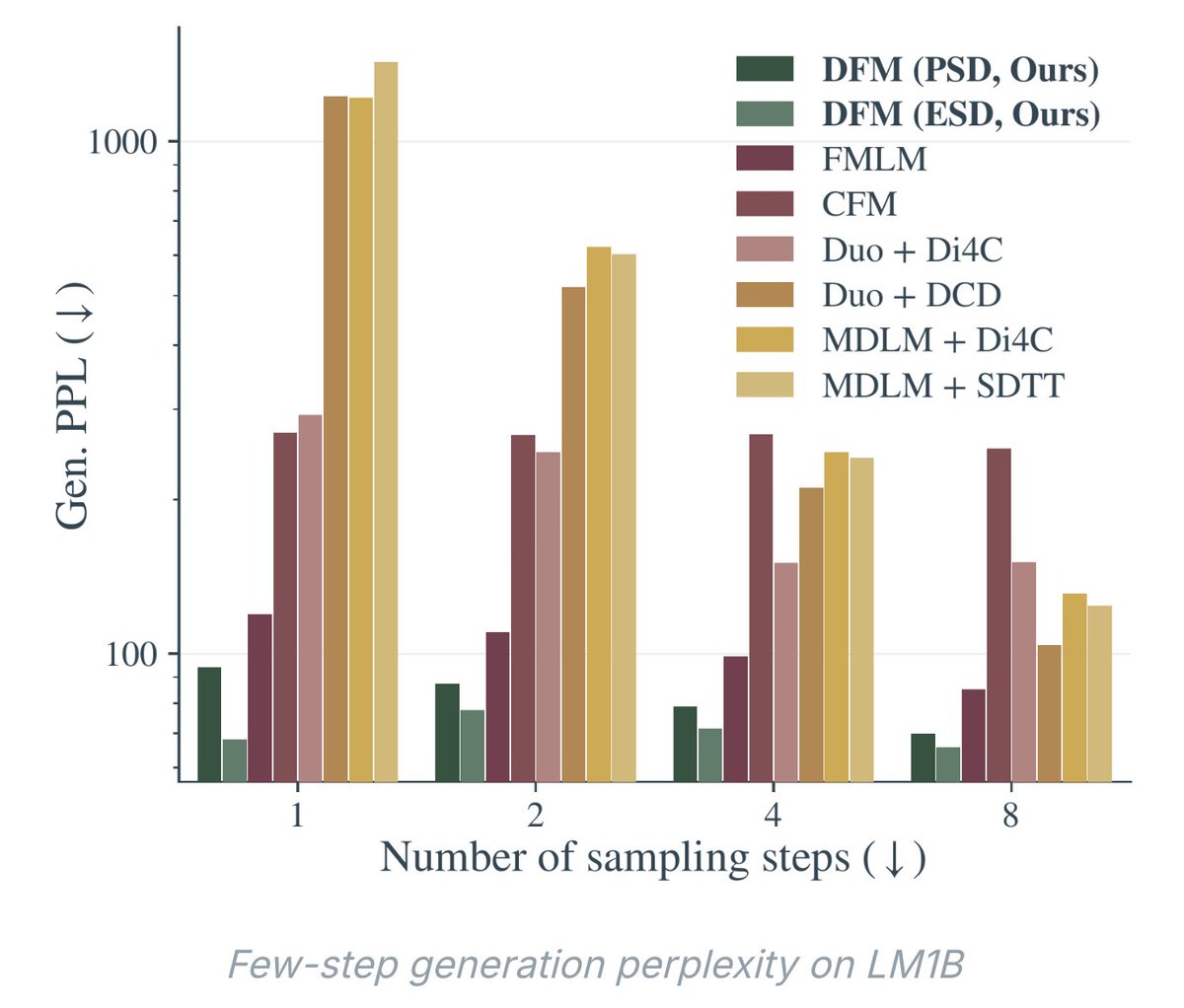
we beat all discrete diffusion baselines at ~8x speed!
v2 gives a complete theory of the flow map over discrete data, with three equivalent ways to learn it (semigroup, lagrangian, eulerian). it turns out you can train these with cross-entropy objectives that look very similar to standard discrete diffusion — but without the factorization error that kills discrete methods at few steps.
beyond improving results across the board, we showcase properties that are unique to continuous flows. in particular, inference-time steering and guidance become straightforward. autoguidance brings generative perplexity down to 51.6 on LM1B, while discrete baselines completely collapse at the same guidance scale.
we also show reward-guided generation for steering topic, sentiment, grammaticality, and safety at inference time — and it works even at 1-2 steps with our flow map model. simple, well-understood techniques from continuous flows just work incredibly well in practice for language.
we’re extremely excited about the future of this class of models.
stay tuned for results on scaling, reasoning, and reinforcement learning-based fine-tuning. 🚀
BREAKING: Anthropic Acquires 9-Person Biotech Startup For $400 Million
>be coefficient bio
>founded the startup 6 months ago
>build AI platform for biotech
>less than 10 employees
>acquired by anthropic for ~$400 million
> = $40+ million per head
Coefficient Bio was building an AI platform for biotech tasks: planning drug R&D, managing clinical regulatory strategy, identifying new drug opportunities
Team is joining Anthropic’s healthcare life sciences group led by Eric Kauderer-Abrams.
Anthropic is building specialized tools for industries that actually pay enterprise rates:
>software engineering
>cybersecurity
>life sciences
>healthcare
>finance
Meanwhile OpenAI is buying media companies to control narratives LMAO
We are also releasing self-contained lecture notes that explain flow matching and diffusion models from scratch. This goes from "zero" to the state-of-the-art in modern Generative AI.
📖 Read the notes here: https://t.co/RULWDgn9pm
Joint work with @EErives40101.
Today we’re announcing X-Cell — Xaira’s first step toward a virtual cell. 🧬
A foundation model that predicts how gene expression changes under causal perturbations — across cell types, conditions, and even unseen biology.
This is not trained on observational atlases.
It is trained on interventions.
🧵👇
@MartinPacesa The competition should be comparing different filters rather than different generation methods. Generation is a search for binders that pass a filter. It's the filter that's the bottleneck in protein binder design.
Today, we report a method for design of active enzymes, RFdiffusion2, in @naturemethods. For the first time, we are able to design enzymes with native-range catalytic activity.
We also are releasing our next frontier model, RFdiffusion3, code 👇
I will be attending NeurIPS @NeurIPSConf in San Diego next week, presenting our new diffusion language model HDLM https://t.co/CwGqnUptzX, and systematic representation guidance for diffusion models REED https://t.co/PSYFFy4BMe. I'm also actively looking for research collaborations -- welcome chat if you are interested in discussion ideas or just some casual talks!
Also, please share 🤓: I'll be at NeurIPS Dec 4-8. I am hiring PhD students and postdocs this year to start at @Harvard@KempnerInst. We work across problems in ML, applied math, probability, and biology, with the goal of all learning from each other. Find me at @NeurIPSConf, DM me, or shoot me an email!
For a flavor of recent topics, see: https://t.co/LvFQsO3M44 https://t.co/oc2Ax7DhF4