@cognition Just like DeepSWE, FrontierCode does not evaluate Anysphere's Composer. I understand evaluation is hard without an API, but it would be very interesting to see the results.
@andreaskweber@mattpocockuk@thomasdijkstra@MirzaHerdic I am unsure whether checking dependencies as edits happen makes sense. Does it burn too many tokens?
Also, do AI agents really need projects to be structured with dependencies, or will they easily cope with spaghetti architecture? I hope they need structure, as I deeply want it!
@andreaskweber@mattpocockuk@thomasdijkstra@MirzaHerdic I have hooks in Claude Code to verify my Dependency Cruiser configuration. In addition to having architectural layers—UI, domain—I have functional layers in the application. The Contact module should not refer to the Accounting module. You get a matrix of controlled dependencies.
@luongnv89@warpdotdev I agree. It is really good. I only use the free version, as I have a Claude subscription. They should make a tiny subscription at $5 for the autocomplete to raise some money.
@warpdotdev
@ToivoMattila@dxouix I had the same question. So far Opus has handled conflicts ok. But I intend to also look into Caleiderscope later for manual merge.
@jakehiggins89@nlw I notice that Gemini 3.1 Pro nearly maxed out the Convex LLM leaderboard https://t.co/ztKJ32ce25
But when evals are maxed out, it usually means they are useless.
Do you think – just like previous Gemini models – this model will be forgotten for coding in a couple of weeks?
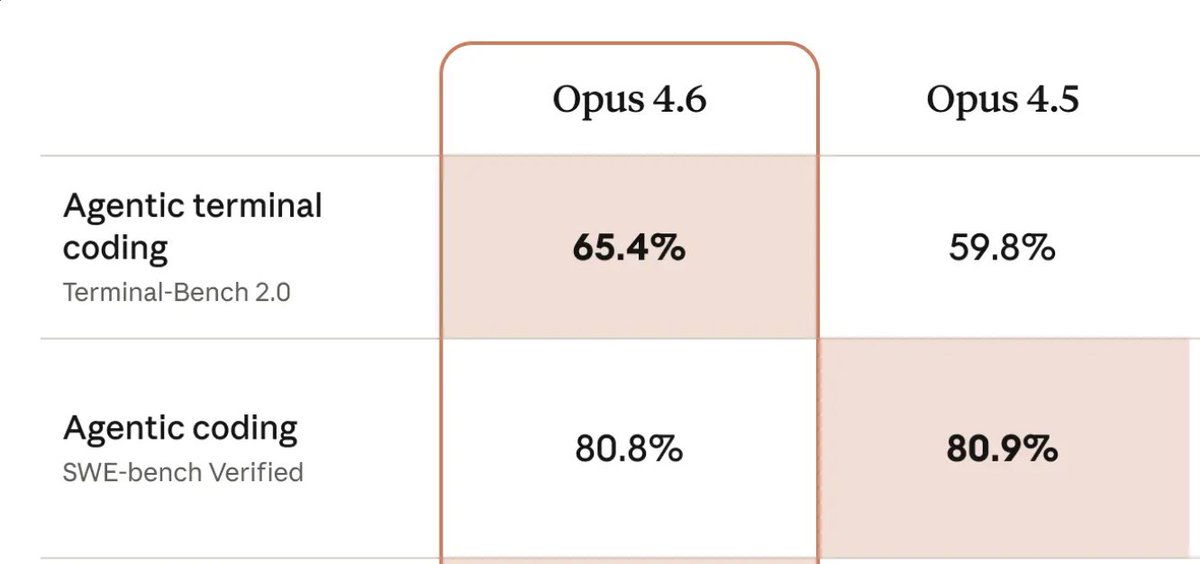
@ScatteraAI@alexalbert__ We get a drop in coding skills when upgrading to Opus 4.6. At least if you belive this. My guess is that 4.6 will be an improvement.