Two frontiers in production AI:
🧠 capability (which model) and
⚡ inference performance (throughput × latency).
Picking the model is easy compared with finding your operating point on the second.
📘 Friendli Guide to Inference Performance Optimization — out now. ⤵️
More GPUs won't fix your latency.
But methodology will — and that's why the Friendli Guide to Inference Performance Optimization is out now. 📘
Most teams over-provision by 30–40%, miss SLA anyway, and conclude they need a bigger cluster. The bottleneck isn't capacity — it's the lack of a framework tying sizing, benchmarking, and SLA targets together.
The 4 steps inside:
• 📐 Size capacity correctly — model weights, KV cache, and headroom
• 📊 Benchmark against realistic concurrency, not synthetic prompts
• 🔍 Diagnose the real bottleneck — TTFT vs TPOT, compute-bound vs memory-bandwidth-bound
• 🎯 Pick an operating point on the Pareto frontier that hits your SLA at the lowest $/M tokens
Free, no gate beyond an email. Link in comment. 👇
I've been bullish on open source aka open-weight models for years.
And I think @OpenRouter's explosive growth is proof that open models were always destined to become economical reasonable alternative to closed APIs.
It's just taken a bit longer than I thought to get there.
🏒 @OpenRouter's $113M raise — alongside growth from 5T to 25T weekly tokens in just 6 months — validates a major shift happening in AI infrastructure.
Open-weight models are rapidly becoming a credible, economical alternative to closed-model APIs, especially as AI agents begin generating massive volumes of inference traffic.
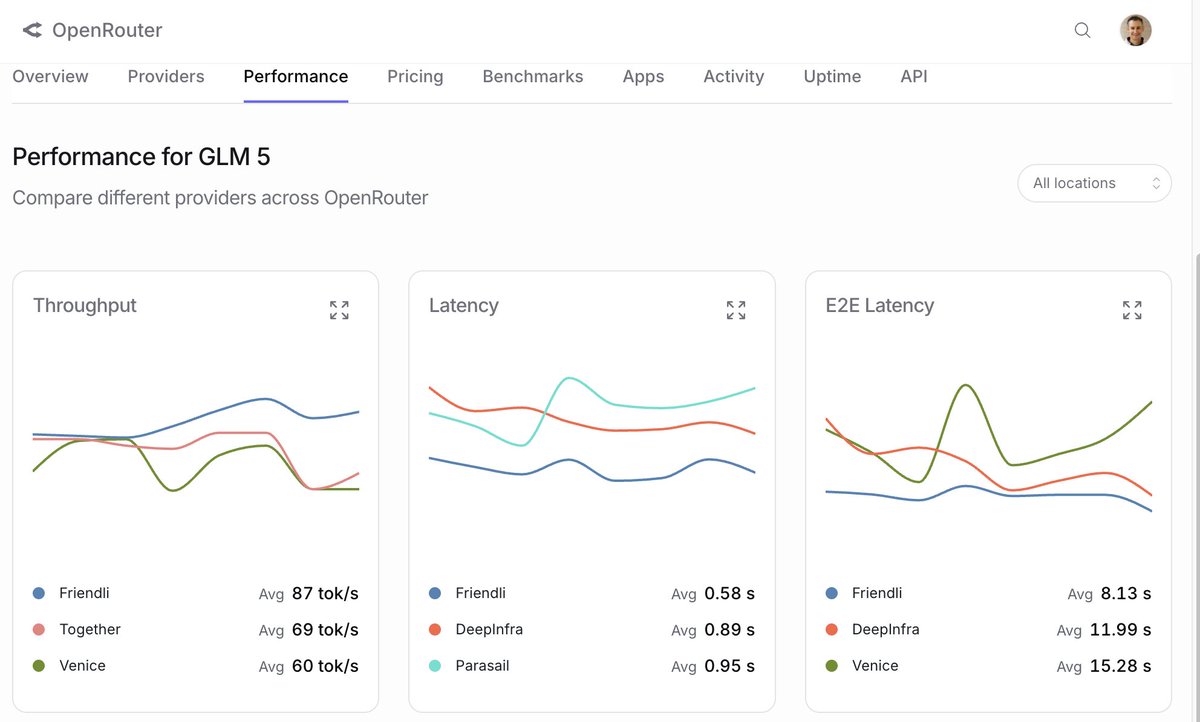
As part of the OpenRouter ecosystem, FriendliAI has consistently ranked among the top-performing providers for models like GLM‑5.1 and DeepSeek V3.2 across:
⚡ Throughput
⏱️ Latency / TTFT
🛡️ Reliability
🧠 Tool-calling performance
Models are increasingly portable.
Inference quality is becoming the differentiator.
Congrats to the OpenRouter team 🥳
And see the link in the comments to try Friendli Model APIs on OpenRouter.
Introducing Friendli InferenceSense™: the "AdSense for GPUs." 🏭💸
InferenceSense helps GPU cloud operators automatically fill idle compute cycles with paid AI inference workloads, just as AdSense helps digital publishers fill empty website space with ads to generate revenue. 🪙💰
Modern data centers are often portrayed as AI factories. Yet, most GPU clouds are still missing the crucial inference "assembly line" that produces intelligence—turning raw compute into generated tokens and revenue. When bursty training jobs finish, expensive hardware simply goes dark—but the massive costs of power, cooling, and depreciation never stop.
Today, we are thrilled to officially launch the industry’s first inference monetization platform purpose-built to fix this: Friendli InferenceSense™.
Powered by the highly optimized engine built by the inventors of continuous batching, InferenceSense automatically detects idle GPU capacity in your fleet and instantly fills it with paid inference requests for popular open-weight models. We bring the global demand; you simply plug in and earn.
"Most GPU operators still act like traditional landlords, watching revenue evaporate every time a workload finishes or a contract ends," says FriendliAI CEO, @bgchun. "InferenceSense provides the missing assembly line. Every idle GPU-hour becomes a chance to serve real AI demand and capture token revenue. The AI factory build-out only makes sense when it actually makes cents."
Why GPU clouds choose InferenceSense:
📈 Monetize Underutilized Infrastructure: Stop losing margin on dark hardware and transform idle compute cycles into an active, revenue-generating asset that can even surpass traditional rental revenue.
🔒 Zero Disruption: Your jobs ALWAYS come first. Immediate preemption guarantees zero downtime for your core workloads.
⚙️ Frictionless Integration: You retain full control over participating nodes and schedules, with no upfront costs or minimum commitments.
Heading to NVIDIA GTC? We are currently accepting applications from qualified GPU cloud operators.
📰 Read the full blog here https://t.co/iuv4i80GHS
📩 Contact [email protected] to schedule an executive briefing with us at GTC
#InferenceSense #NVIDIAGTC
🚀 Together AI Achieves 90% Faster BF16 Training with NVIDIA Blackwell Platform and Together Kernel Collection
Today we are announcing immediate access to Together GPU Clusters accelerated by the NVIDIA Blackwell platform, with an AI acceleration stack optimized for the latest GPU architecture.
Together GPU Clusters featuring NVIDIA HGX B200 deliver 90% faster training than NVIDIA HGX H100, powered by Together Kernel Collection to optimize performance at scale.
🏎 Test Drive NVIDIA Blackwell Platform – Apply by February 26. Work with NVIDIA and Together AI researchers to optimize performance.
📢 Apply for a free test drive today → https://t.co/at132RN5zD
📖 Read more in the full blog → https://t.co/GQqOkrJSFk
🚀 DeepSeek-R1 now available on Together AI!
DeepSeek-R1 sets a new standard for open-source reasoning models, rivaling OpenAI-o1. It’s faster than closed-source alternatives, delivers the same top-tier performance across math, code, and reasoning tasks, and operates at a fraction of the cost.
Now available on Together AI with:
🔒 Opt-out privacy controls
📃 Full 160K context
⚡ Deploy seamlessly on serverless, dedicated endpoints, or enterprise environments
🌊 Big kudos to @deepseek_ai for continuing to make waves in the open-source community 🙌
I've been reading @tldrnewsletter 📰 for years to keep up with tech
And what's the top story in today's TLDR AI? 🤖
🦙 @togethercompute AI has partnered with @AIatMeta to offer a FREE API for the new Llama 3.2 vision model 😲
Try it for free 👇
https://t.co/8X9HCiG03j
Together API now provides _free_ access to Llama 3.2 11B Vision model.
Since we founded Together AI, I've wanted to offer to a great foundation model for free, so creative developers everywhere can build AI enabled apps without cost. We are able to do this now. Thank you to @AIatMeta for a great open model capable of language and vision.
🚀 Big news! We’re thrilled to announce the launch of Llama 3.2 Vision Models & Llama Stack on Together AI.
🎉 Free access to Llama 3.2 Vision Model for developers to build and innovate with open source AI. https://t.co/FVlp2euqrC
➡️ Learn more in the blog https://t.co/kUxdw5VUC3
How do you stay ahead when Gen AI is
changing the way we approach marketing every day?
@ryanpollock shares key insights in the latest episode
of The Entail AI Podcast: https://t.co/oP5gMnDjnE
#GenerativeAI#MarketingInsights#AIinMarketing
Great #generativeai meetup @awscloud featuring @jeffboudier from 🤗
@HuggingFace and @OpenAI remind me very much of Android and iOS, respectively.
And now is the time for both platforms to suit up and start selling...while holding on to what made them great 😉
Big moment @OpenAI
In addition to these new APIs - their home page and website structure now reflect a company that is actually trying to market and sell their platform.
Well done @sama
https://t.co/btTdyQVWj5
Automated summarization of what’s going on within a business in Slack, JIRA, Git etc is about to be super useful new product area that anyone in an exec or product role will want. Slack in particular needs summaries badly. https://t.co/nYgwaDjbey