🔉 Introducing SAM Audio, the first unified model that isolates any sound from complex audio mixtures using text, visual, or span prompts.
We’re sharing SAM Audio with the community, along with a perception encoder model, benchmarks and research papers, to empower others to explore new forms of expression and build applications that were previously out of reach.
🔗 Learn more: https://t.co/FPnfv66UCP
Introducing Nested Learning: A new ML paradigm for continual learning that views models as nested optimization problems to enhance long context processing. Our proof-of-concept model, Hope, shows improved performance in language modeling. Learn more: https://t.co/8wvV9vyA5V
@GoogleAI
Today, we’re announcing a major breakthrough that marks a significant step forward in the world of quantum computing. For the first time in history, our teams at @GoogleQuantumAI demonstrated that a quantum computer can successfully run a verifiable algorithm, 13,000x faster than leading classical supercomputers.
This continues to build momentum on past quantum computing discoveries. Back in 2019, we proved a quantum computer could solve a problem that would take a classical computer thousands of years. Then in 2024, our new Willow chip solved a major issue in quantum error correction that challenged the field for nearly 30 years. Today’s breakthrough moves us closer to quantum computers that can drive discoveries in areas like medicine and materials science.
AI efficiency is important. Today, Google is sharing a technical paper detailing our comprehensive methodology for measuring the environmental impact of Gemini inference. We estimate that the median Gemini Apps text prompt uses 0.24 watt-hours of energy (equivalent to watching an average TV for ~nine seconds), and consumes 0.26 milliliters of water (about five drops) — figures that are substantially lower than many public estimates.
At the same time, our AI systems are becoming more efficient through research innovations and software and hardware efficiency improvements. From May 2024 to May 2025, the energy footprint of the median Gemini Apps text prompt dropped by 33x, and the total carbon footprint dropped by 44x, through a combination of model efficiency improvements, machine utilization improvements and additional clean energy procurement, all while delivering higher quality responses.
See the blog or technical paper for more about our methodology and ongoing efforts.
Blog:
https://t.co/CoMm5gV9SR
Link to detailed paper: https://t.co/UBi9rd6gEC
What if you could not only watch a generated video, but explore it too? 🌐
Genie 3 is our groundbreaking world model that creates interactive, playable environments from a single text prompt.
From photorealistic landscapes to fantasy realms, the possibilities are endless. 🧵
Excited to share two advances that bring us closer to real-world impact in healthcare AI:
SDBench introduces a new benchmark that transforms 304 NEJM cases into interactive diagnostic simulations. AI must ask questions, order tests, and weigh costs, mirroring the complexity of real clinical decision-making.
MAI-DxO is a model-agnostic orchestrator that simulates a panel of virtual physicians. It achieves 85.5% diagnostic accuracy—four times that of experienced doctors—while cutting diagnostic costs.
Together, these advances offer a blueprint for how AI can help deliver precision and efficiency in healthcare, and we're looking forward to working with healthcare partners and the entire ecosystem on these advances making a difference.
https://t.co/XHpb1gWYxN
New on the Anthropic Engineering blog: how we built Claude’s research capabilities using multiple agents working in parallel.
We share what worked, what didn't, and the engineering challenges along the way.
https://t.co/k3Gzd4HkLg
Shocker! Claude 4 system prompt was leaked, and it's a goldmine!
The Claude system prompt incorporates several identifiable agentic AI patterns as described in "A Pattern Language For Agentic AI." Here's an analysis of the key patterns used:
Run-Loop Prompting: Claude operates within an execution loop until a clear stopping condition is met, such as answering a user's question or performing a tool action. This is evident in directives like "Claude responds normally and then..." which show turn-based continuation guided by internal conditions.
Input Classification & Dispatch: Claude routes queries based on their semantic class—such as support, API queries, emotional support, or safety concerns—ensuring they are handled by different policies or subroutines. This pattern helps manage heterogeneous inputs efficiently.
Structured Response Pattern: Claude uses a rigid structure in output formatting—e.g., avoiding lists in casual conversation, using markdown only when specified—which supports clarity, reuse, and system predictability.
Declarative Intent: Claude often starts segments with clear intent, such as noting what it can and cannot do, or pre-declaring response constraints. This mitigates ambiguity and guides downstream interpretation.
Boundary Signaling: The system prompt distinctly marks different operational contexts—e.g., distinguishing between system limitations, tool usage, and safety constraints. This maintains separation between internal logic and user-facing messaging.
Hallucination Mitigation: Many safety and refusal clauses reflect an awareness of LLM failure modes and adopt pattern-based countermeasures—like structured refusals, source-based fallback (e.g., directing users to Anthropic’s site), and explicit response shaping.
Protocol-Based Tool Composition: The use of tools like web_search or web_fetch with strict constraints follows this pattern. Claude is trained to use standardized, declarative tool protocols which align with patterns around schema consistency and safe execution.
Positional Reinforcement: Critical behaviors (e.g., "Claude must not..." or "Claude should...") are often repeated at both the start and end of instructions, aligning with patterns designed to mitigate behavioral drift in long prompts.
I was given early access to Grok 3 earlier today, making me I think one of the first few who could run a quick vibe check.
Thinking
✅ First, Grok 3 clearly has an around state of the art thinking model ("Think" button) and did great out of the box on my Settler's of Catan question:
"Create a board game webpage showing a hex grid, just like in the game Settlers of Catan. Each hex grid is numbered from 1..N, where N is the total number of hex tiles. Make it generic, so one can change the number of "rings" using a slider. For example in Catan the radius is 3 hexes. Single html page please."
Few models get this right reliably. The top OpenAI thinking models (e.g. o1-pro, at $200/month) get it too, but all of DeepSeek-R1, Gemini 2.0 Flash Thinking, and Claude do not.
❌ It did not solve my "Emoji mystery" question where I give a smiling face with an attached message hidden inside Unicode variation selectors, even when I give a strong hint on how to decode it in the form of Rust code. The most progress I've seen is from DeepSeek-R1 which once partially decoded the message.
❓ It solved a few tic tac toe boards I gave it with a pretty nice/clean chain of thought (many SOTA models often fail these!). So I upped the difficulty and asked it to generate 3 "tricky" tic tac toe boards, which it failed on (generating nonsense boards / text), but then so did o1 pro.
✅ I uploaded GPT-2 paper. I asked a bunch of simple lookup questions, all worked great. Then asked to estimate the number of training flops it took to train GPT-2, with no searching. This is tricky because the number of tokens is not spelled out so it has to be partially estimated and partially calculated, stressing all of lookup, knowledge, and math. One example is 40GB of text ~= 40B characters ~= 40B bytes (assume ASCII) ~= 10B tokens (assume ~4 bytes/tok), at ~10 epochs ~= 100B token training run, at 1.5B params and with 2+4=6 flops/param/token, this is 100e9 X 1.5e9 X 6 ~= 1e21 FLOPs. Both Grok 3 and 4o fail this task, but Grok 3 with Thinking solves it great, while o1 pro (GPT thinking model) fails.
I like that the model *will* attempt to solve the Riemann hypothesis when asked to, similar to DeepSeek-R1 but unlike many other models that give up instantly (o1-pro, Claude, Gemini 2.0 Flash Thinking) and simply say that it is a great unsolved problem. I had to stop it eventually because I felt a bit bad for it, but it showed courage and who knows, maybe one day...
The impression overall I got here is that this is somewhere around o1-pro capability, and ahead of DeepSeek-R1, though of course we need actual, real evaluations to look at.
DeepSearch
Very neat offering that seems to combine something along the lines of what OpenAI / Perplexity call "Deep Research", together with thinking. Except instead of "Deep Research" it is "Deep Search" (sigh). Can produce high quality responses to various researchy / lookupy questions you could imagine have answers in article on the internet, e.g. a few I tried, which I stole from my recent search history on Perplexity, along with how it went:
- ✅ "What's up with the upcoming Apple Launch? Any rumors?"
- ✅ "Why is Palantir stock surging recently?"
- ✅ "White Lotus 3 where was it filmed and is it the same team as Seasons 1 and 2?"
- ✅ "What toothpaste does Bryan Johnson use?"
- ❌ "Singles Inferno Season 4 cast where are they now?"
- ❌ "What speech to text program has Simon Willison mentioned he's using?"
❌ I did find some sharp edges here. E.g. the model doesn't seem to like to reference X as a source by default, though you can explicitly ask it to. A few times I caught it hallucinating URLs that don't exist. A few times it said factual things that I think are incorrect and it didn't provide a citation for it (it probably doesn't exist). E.g. it told me that "Kim Jeong-su is still dating Kim Min-seol" of Singles Inferno Season 4, which surely is totally off, right? And when I asked it to create a report on the major LLM labs and their amount of total funding and estimate of employee count, it listed 12 major labs but not itself (xAI).
The impression I get of DeepSearch is that it's approximately around Perplexity DeepResearch offering (which is great!), but not yet at the level of OpenAI's recently released "Deep Research", which still feels more thorough and reliable (though still nowhere perfect, e.g. it, too, quite incorrectly excludes xAI as a "major LLM labs" when I tried with it...).
Random LLM "gotcha"s
I tried a few more fun / random LLM gotcha queries I like to try now and then. Gotchas are queries that specifically on the easy side for humans but on the hard side for LLMs, so I was curious which of them Grok 3 makes progress on.
✅ Grok 3 knows there are 3 "r" in "strawberry", but then it also told me there are only 3 "L" in LOLLAPALOOZA. Turning on Thinking solves this.
✅ Grok 3 told me 9.11 > 9.9. (common with other LLMs too), but again, turning on Thinking solves it.
✅ Few simple puzzles worked ok even without thinking, e.g. *"Sally (a girl) has 3 brothers. Each brother has 2 sisters. How many sisters does Sally have?"*. E.g. GPT4o says 2 (incorrectly).
❌ Sadly the model's sense of humor does not appear to be obviously improved. This is a common LLM issue with humor capability and general mode collapse, famously, e.g. 90% of 1,008 outputs asking ChatGPT for joke were repetitions of the same 25 jokes. Even when prompted in more detail away from simple pun territory (e.g. give me a standup), I'm not sure that it is state of the art humor. Example generated joke: "*Why did the chicken join a band? Because it had the drumsticks and wanted to be a cluck-star!*". In quick testing, thinking did not help, possibly it made it a bit worse.
❌ Model still appears to be just a bit too overly sensitive to "complex ethical issues", e.g. generated a 1 page essay basically refusing to answer whether it might be ethically justifiable to misgender someone if it meant saving 1 million people from dying.
❌ Simon Willison's "*Generate an SVG of a pelican riding a bicycle*". It stresses the LLMs ability to lay out many elements on a 2D grid, which is very difficult because the LLMs can't "see" like people do, so it's arranging things in the dark, in text. Marking as fail because these pelicans are qutie good but, but still a bit broken (see image and comparisons). Claude's are best, but imo I suspect they specifically targeted SVG capability during training.
Summary. As far as a quick vibe check over ~2 hours this morning, Grok 3 + Thinking feels somewhere around the state of the art territory of OpenAI's strongest models (o1-pro, $200/month), and slightly better than DeepSeek-R1 and Gemini 2.0 Flash Thinking. Which is quite incredible considering that the team started from scratch ~1 year ago, this timescale to state of the art territory is unprecedented. Do also keep in mind the caveats - the models are stochastic and may give slightly different answers each time, and it is very early, so we'll have to wait for a lot more evaluations over a period of the next few days/weeks. The early LM arena results look quite encouraging indeed. For now, big congrats to the xAI team, they clearly have huge velocity and momentum and I am excited to add Grok 3 to my "LLM council" and hear what it thinks going forward.
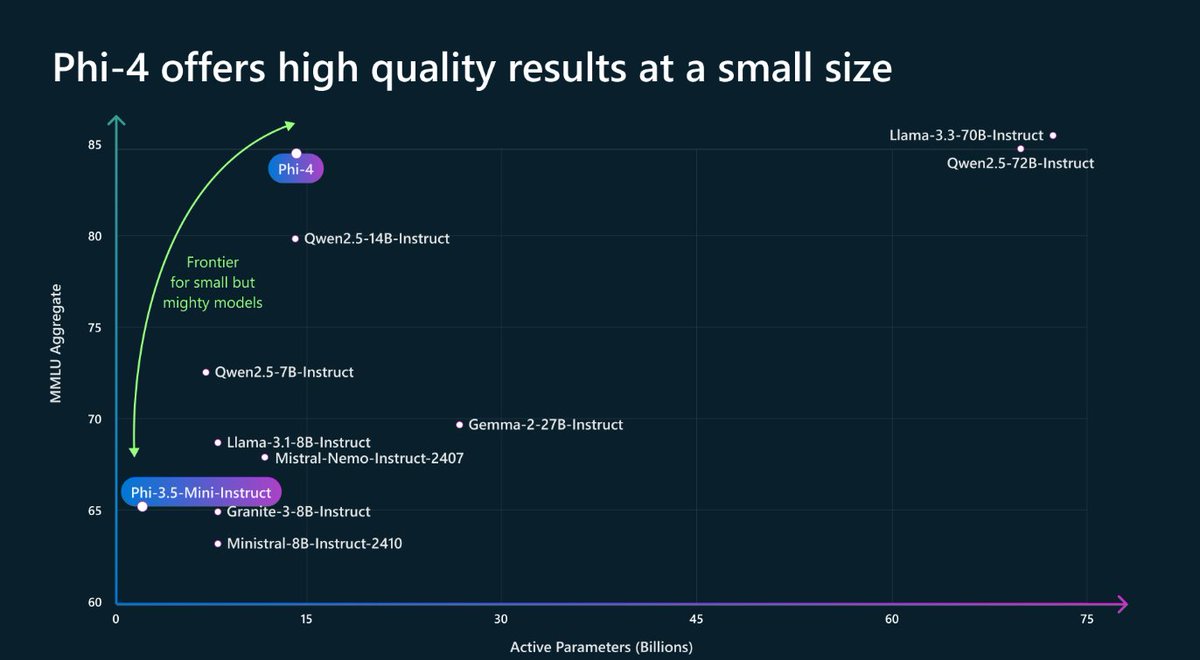
🚀 Phi-4 is here! A small language model that performs as well as (and often better than) large models on certain types of complex reasoning tasks such as math. Useful for us in @MSFTResearch, and available now for all researcher on the Azure AI Foundry! https://t.co/83yoZZXn6D
Introducing Willow, our new state-of-the-art quantum computing chip with a breakthrough that can reduce errors exponentially as we scale up using more qubits, cracking a 30-year challenge in the field. In benchmark tests, Willow solved a standard computation in <5 mins that would take a leading supercomputer over 10^25 years, far beyond the age of the universe(!).
Introducing, Act-One. A new way to generate expressive character performances inside Gen-3 Alpha using a single driving video and character image. No motion capture or rigging required.
Learn more about Act-One below.
(1/7)
Alex Rodriguez asked a question. Reggie Jackson answered it.
(Shouts to the producer and rest of the desk for staying out of Reggie’s way and just letting him talk. I doubt they expected this answer. But it’s a great few minutes of television.)
Graph RAG makes sense if you think about it as a superset of "standard" vector RAG:
1. Find an initial set of nodes via vector/keyword search
2. Augment context by traversing relationships
3. Augment context by also running other graph retrieval algorithms like text-to-cypher
4. Rerank all the context as a final pass
In this sense it's basically vector search with more context. The graph doesn't have to be complicated - just 1-2 levels deep from any text chunk. The end result is better retrieval and synthesis quality.
Building this yourself is easy in @llama_index, check out our guide here! https://t.co/ymeRo1AJx8
This chart is a great rebuttal of the view that RAG will solve hallucination. In the legal domain, it turns out that it does improve precision somewhat, but at the expense of recall. Really great paper by Stanford & Yale researchers assessing legal AI. https://t.co/jMYtAXDSiP