🎄☃️ Merry Christmas and Happy Holidays everyone ! 🎅🎁
A small gift from my team - an open source framework for building enterprise Gen AI applications ✨
⭐https://t.co/VAAT3qOFG1
👍https://t.co/yHYrkigfbd
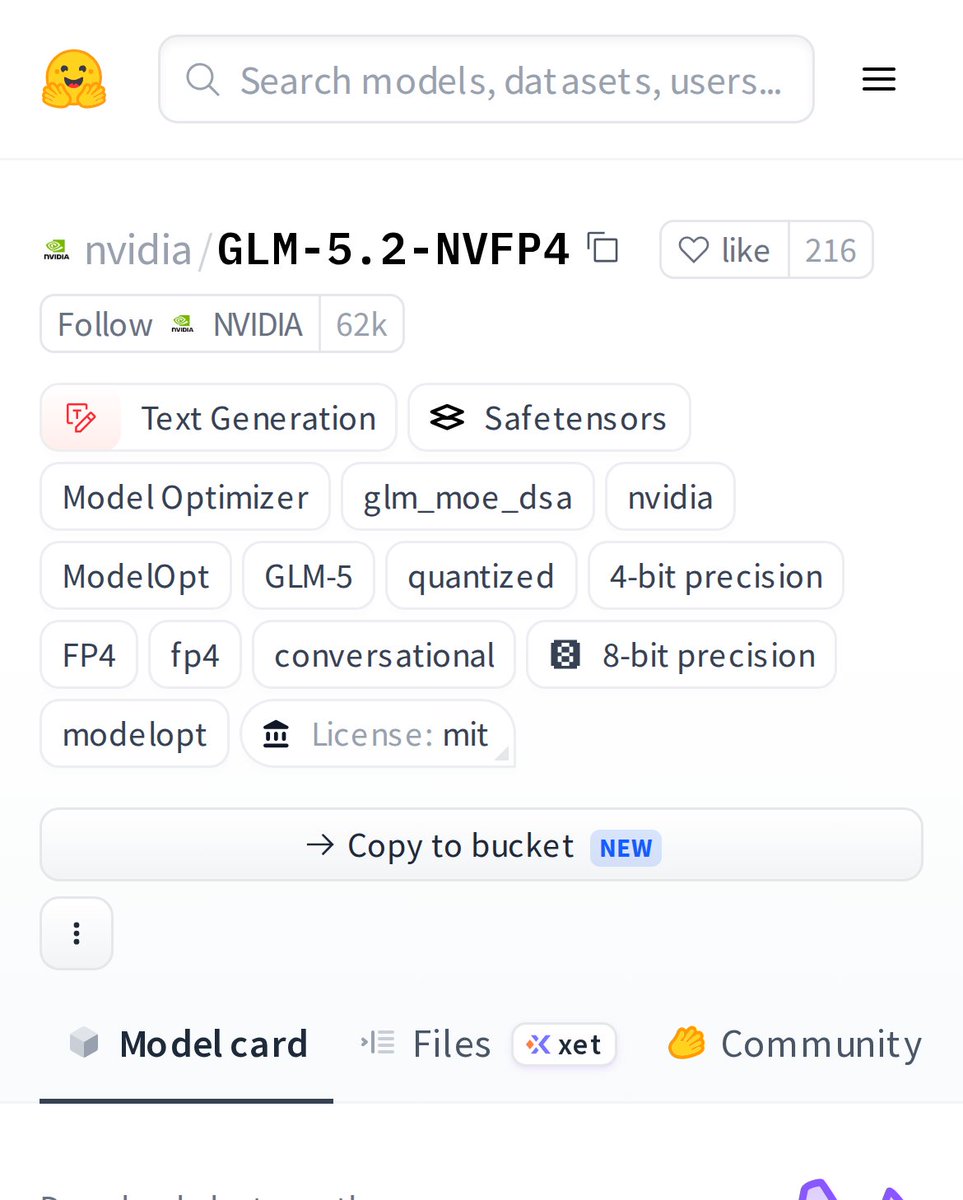
Imagine running a massive GLM-5 model on consumer hardware. That's what nvidia's GLM-5.2-NVFP4 delivers with 4-bit FP4 quantization. It's a game changer for local AI, making high-end text generation accessible to more builders. #AI#MachineLearning
Super excited to announce seven new world-class MAI models today. They represent what we consider a new era in AI designed to keep you in control and on the frontier.
First is our text foundation model, MAI-Thinking-1, exceptionally strong on reasoning and SWE tasks.
- It’s a 35B active parameter MoE with a 256K context window. Independent human raters on Surge prefer it for overall quality in blind side-by-sides versus Sonnet 4.6, and it’s achieved 97% on AIME 2025, the key measure of its general-purpose reasoning abilities.
- It's at 53% on SWE Bench Pro, placing it right alongside Opus 4.6 on one of the toughest coding benchmarks.
- And since we co-designed our models with our own silicon, MAI-Thinking-1 is optimized on our MAIA 200 chip. Benchmarking head-to-head against the GB200, we see 30% better performance per dollar as well as a 1.4x performance-per-watt gain when running our MAI models on the MAIA 200 end-to-end.
Next is MAI-Image-2.5 and its Flash variant. Two super strong models now at #2 on the leaderboards, surpassing the score of Nano Banana 2 on image editing.
Last for now is MAI-Code-1-Flash, our new inference efficient coding model, especially tuned for VS Code and GitHub Copilot CLI.
- Code-1-Flash achieves 51% on SWE Bench Pro, despite having just 5B parameters, putting it closer to Haiku in size but cheaper in cost.
All of this is the foundation for Microsoft Frontier Tuning. It lets you customize our models to create custom, company-specific agents that only you control. You can make our model, your model. Your data. Your agents. Your moat.
Early adopters are already seeing a difference. When we tuned our models for McKinsey’s tasks, MAI delivered the highest win rate, outperforming GPT-5.5 on quality, while being 10x lower on cost.
Also really excited to be collaborating with the amazing team at Mayo Clinic to jointly train a new frontier AI model for healthcare.
Our announcements today mark another milestone on the road to humanist superintelligence. You can learn more and about our other new models in our latest blog: https://t.co/v65eop5Ixq
Hi friends at #CVPR2026! 👋
Please come check out our research today!
@YaoChihLee will showcase a super-fun video motion editing work - Edit-by-Track (#378)!
https://t.co/CPXkjHbEkY
I just spent months handwriting a 200 page guide on the entirety of ML foundations and math from scratch.
The guide features:
- Neural Nets (Backprop, Adam, SGD, Batch Norm)
- ML Algorithms (SVM, Grad Boosting, K-means, PCA)
- Hardware (Tensor Cores, Systolic Arrays, CUDA)
- Transformers (Multi-Head Attn, KV Cache, LoRA)
- Vision (ViT, Convolutions, MAE, IoU, NMS, VLM)
- Agents (OpenClaw, ReAct, Memory, Orchestration)
Everything I wish I had years ago, for free.
@zhaisf@geoffreyhinton We have a modern version of the experiment (mnist is tricky: almost everything looks good on it), and i believe a better explanation than "dark knowledge" in our paper: https://t.co/3SlkXVZcG3
Personal update: I've joined Anthropic. I think the next few years at the frontier of LLMs will be especially formative. I am very excited to join the team here and get back to R&D. I remain deeply passionate about education and plan to resume my work on it in time.
Zhilin at GTC: Introducing Attention Residuals
Learning selective memory, rather than mechanically accumulating everything, is the beauty of attention.
Many of you have probably read Attention Is All You Need, the 2017 Transformer paper that brought “human-like” attention into the model’s field of view. From that point on, models no longer simply read everything in a mechanical way. Instead, they began to develop a sense of what matters more and what matters less across the text, choosing to retain the more important information.
Recently, Kimi applied this idea of attention to the temporal dimension, then rotated it 90 degrees into the model’s depth dimension. This allows the model to have attention not only over time, but also throughout the process of information transmission across layers—giving it a more intelligent way to understand and process information.
You can now train Qwen3.5 with RL in our free notebook!
You just need 8GB VRAM to RL Qwen3.5-2B locally!
Qwen3.5 will learn to solve math problems autonomously via vision GRPO.
RL Guide: https://t.co/iR9AF3BIFu
GitHub: https://t.co/aZWYAtakBP
Qwen3-4B: https://t.co/OzzCLFkSoW
Today, startups aren't winning by hiring faster, but by automating as many internal functions as possible.
In this episode of Main Function, @garrytan breaks down how tiny teams are beating companies 20x their size by building automations into every workflow, from engineering to ops to customer support.
If AI scientists are writing millions of papers, many of which are slop, and some of which are incremental progress, how would we identify the one or two which come up with an extremely productive new idea?
In 1948, Shannon was one of hundreds of engineers at Bell Labs working on how to cleanly send voice signals over noisy copper wires. His paper sat in the same technical journal as reports on reducing static and building better filters.
How would you recognize that he has come up with this very general framework for thinking about information and communication channels, which over the coming decades would have enormous use from domains as far apart as cryptography to genetics to quantum mechanics?
It seems like it can take fields multiple decades to recognize the significance of unifying new concepts. Because it is on that time scale that the fruits of such general concepts lead to new discoveries across many different fields.
We’ve managed to solve this peer review problem for human scientists (at least somewhat). Now we’ll need to do it at a much greater scale for the mass of AI science that will be thrown at us.
I'm Boris and I created Claude Code. Lots of people have asked how I use Claude Code, so I wanted to show off my setup a bit.
My setup might be surprisingly vanilla! Claude Code works great out of the box, so I personally don't customize it much. There is no one correct way to use Claude Code: we intentionally build it in a way that you can use it, customize it, and hack it however you like. Each person on the Claude Code team uses it very differently.
So, here goes.
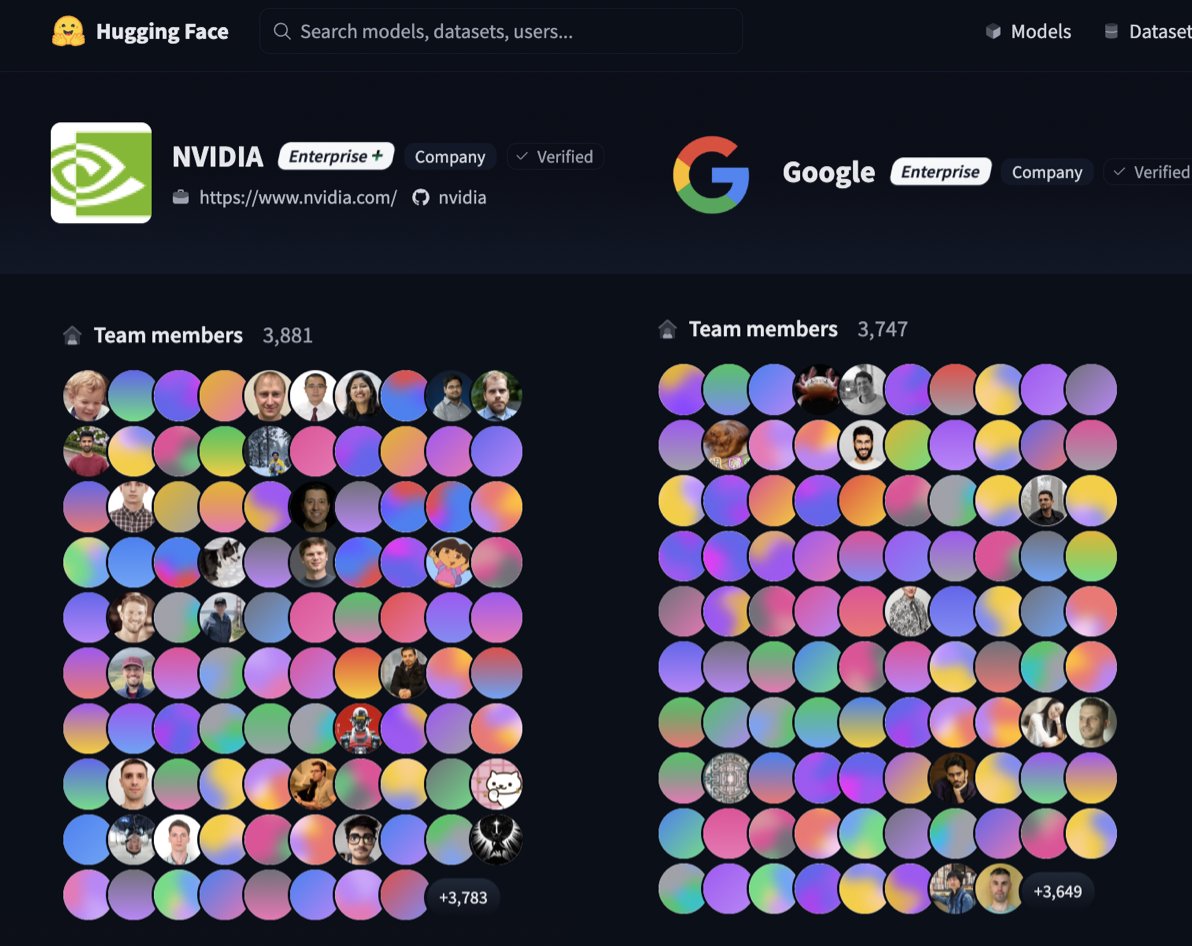
Nvidia just crossed Google as the biggest org on @huggingface with 3,881 team members on the hub.
I'm officially calling it:
Nvidia is the new American king of open-source AI!
Jensen name-dropped me in the keynote and posed with our belt.
He has a physical belt too but they just showed the pic
Intially I made fun of the 35X perf improvement being bogus, I thought it was an exaggeration of performance
Turns out he was sandbagging, and perf is 50x
Two new Stealth Models are live now!
- Hunter Alpha: 1T-parameter model with 1M context built for agentic workflows, long-horizon tasks, and serious tool use.
- Healer Alpha: multimodal model combining strong image, video, and audio understanding with real agentic execution.
Thank you Jensen and NVIDIA! She’s a real beauty! I was told I’d be getting a secret gift, with a hint that it requires 20 amps. (So I knew it had to be good). She’ll make for a beautiful, spacious home for my Dobby the House Elf claw, among lots of other tinkering, thank you!!
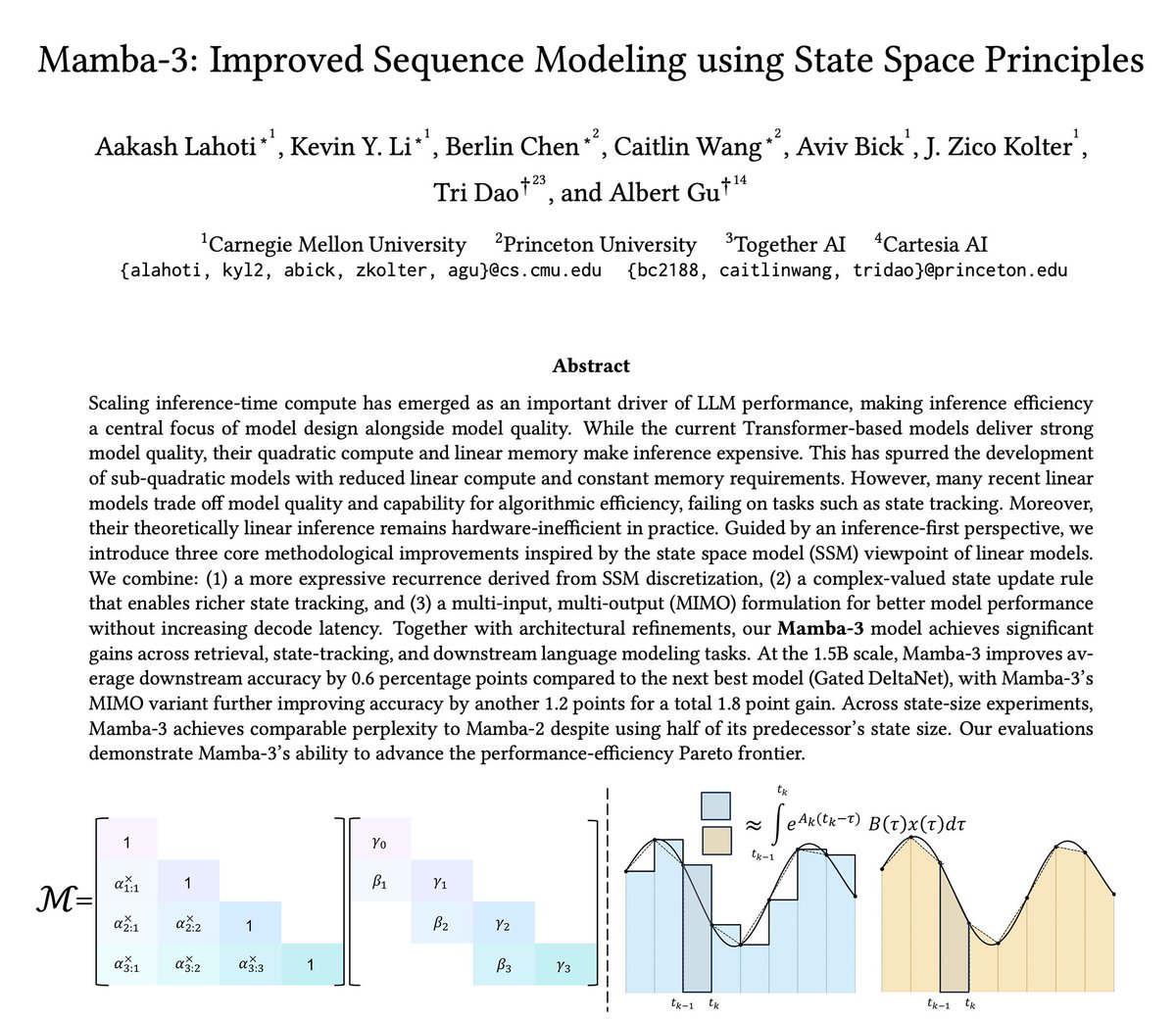
The newest model in the Mamba series is finally here 🐍
Hybrid models have become increasingly popular, raising the importance of designing the next generation of linear models.
We've introduced several SSM-centric ideas to significantly increase Mamba-2's modeling capabilities without compromising on speed. The resulting Mamba-3 model has noticeable performance gains over the most popular previous linear models (such as Mamba-2 and Gated DeltaNet) at all sizes.
This is the first Mamba that was student led: all credit to @aakash_lahoti@kevinyli_@_berlinchen@caitWW9, and of course @tri_dao!
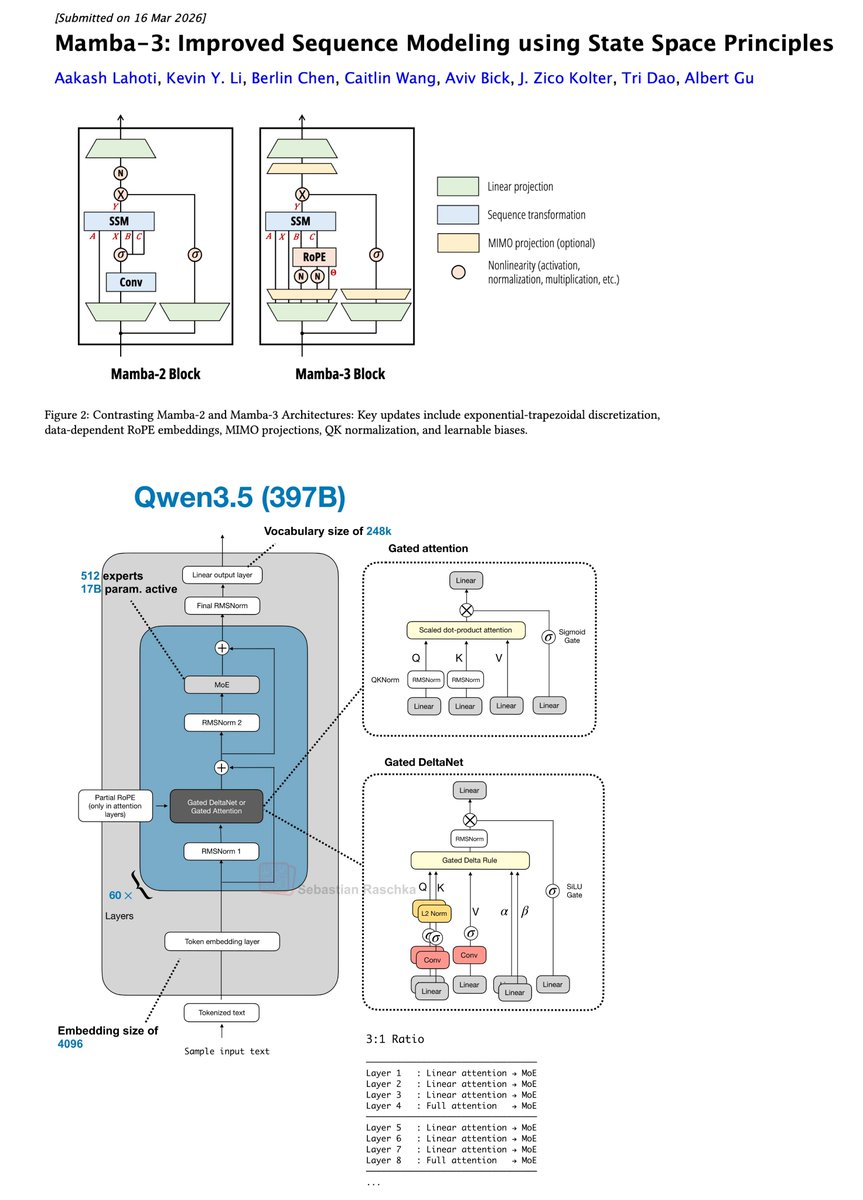
Oh wow, Mamba-3 is here!
For me, the most interesting use case of Mamba and Mamba-likes are the recent transformer attention hybrid architectures (Qwen3.5, Kimi Linear, etc.)
Would be interesting to swap Gated DeltaNet with Mamba-3 (which now also has RoPE) in next gen hybrids.