📢 Our BannerGen open-source library incorporates LayoutDETR, LayoutInstructPix2Pix, and RetrieveAdapter in parallel for diversified experience of banner designs. Great work from the team: Chia-Chih Chen*, @realNingYu*, Zeyuan Chen, @shugerdou, @stanleyran
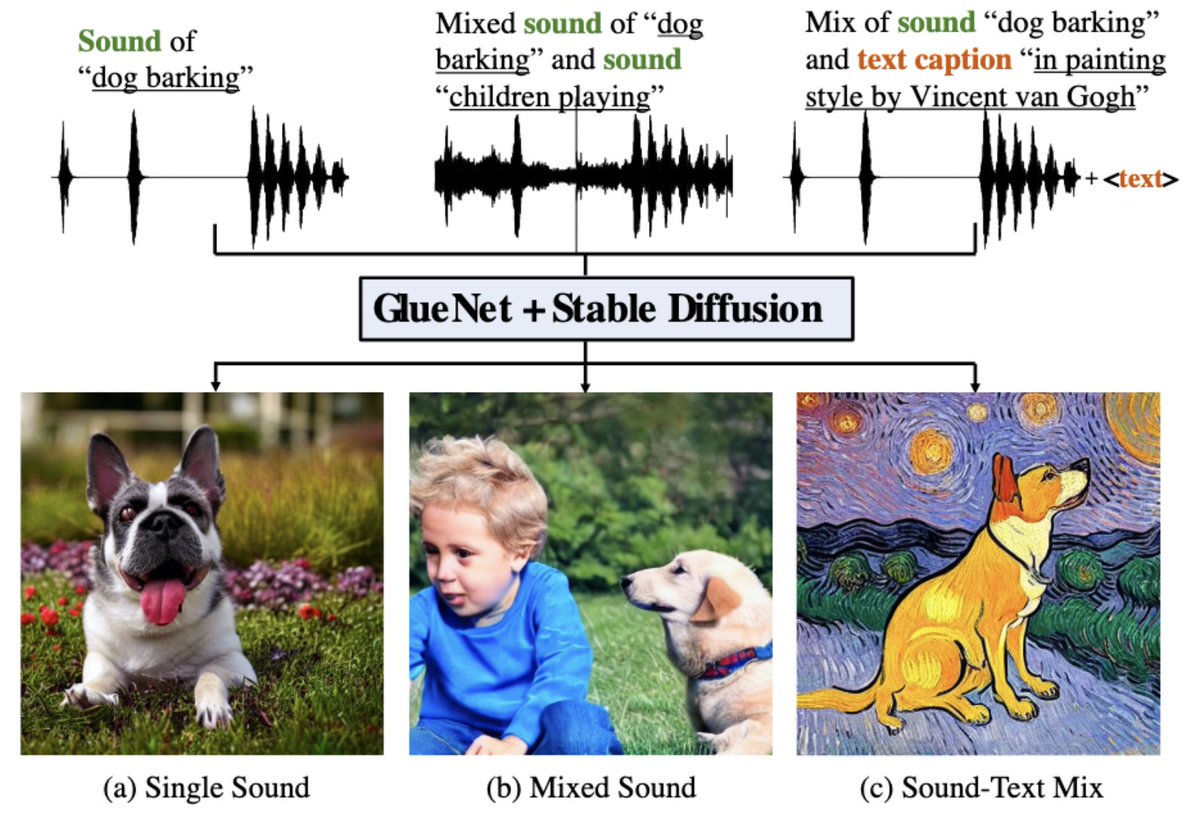
We present ✍️GlueGen✍️, efficient adapters for diffusion models, that achieves X-to-image generation by multimodal controls: multilingual texts, sounds, and their mixes.
arXiv: https://t.co/35wCxQwlSw
Web: https://t.co/MEOdb1m9Sa
Code: https://t.co/eFrwK1XFFc
(1/n)
We present ✍️GlueGen✍️, efficient adapters for diffusion models, that achieves X-to-image generation by multimodal controls: multilingual texts, sounds, and their mixes.
arXiv: https://t.co/35wCxQwlSw
Web: https://t.co/MEOdb1m9Sa
Code: https://t.co/eFrwK1XFFc
(1/n)
Amazing @silviocinguetta Salesforce AI new generative large multi-modal for image generation & editing w/ NLP! Great collaboration @SFResearch & @Stanford.
Web: https://t.co/9n29XD7ICB
ArXiv: https://t.co/Xu37zq7lrw
Code: https://t.co/3sdOWyL2Lz https://t.co/3sdOWyL2Lz
Excited to introduce a new generative large multi-modal model for image generation and editing using natural language! Great collaboration Salesforce AI Research @SFResearch and Stanford U!
Web: https://t.co/cCR2eVbwux
ArXiv: https://t.co/arwvJhw1B8
Code: https://t.co/cA2Jbkurhl
Introducing ULIP-2, our latest work scaling multimodal pre-training for 3D understanding without the need for any manual annotations. Check out our code & released large-scale tri-modal datasets!
https://t.co/Ez5jmIYYsZ
Arxiv:
https://t.co/R8DRklTXBK
Blog:
https://t.co/AxRNOhnsiR
New blog post on our #AAAI2018 FlowGAN paper by @adityagrover_ and Manik Dhar: surprising results comparing GAN vs. mixture of Gaussians!
https://t.co/q3EXzrRzHh
(btw Manik is applying to PhD programs - check out his folder if you are hiring)
I'll be in New Orleans for the annual AAAI conference this week! Visit our page to learn more about Amazon Research and our publications at #AAAI2018 https://t.co/2IhlSrfHaI