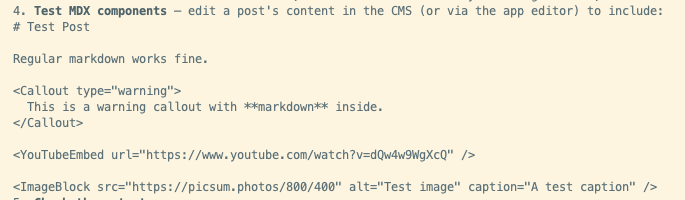
Using @claudeai desktop, is there a way to directly reference chats from the claude code tab? I'm finding that chat is better for some high level planning even before using claude code's plan mode.
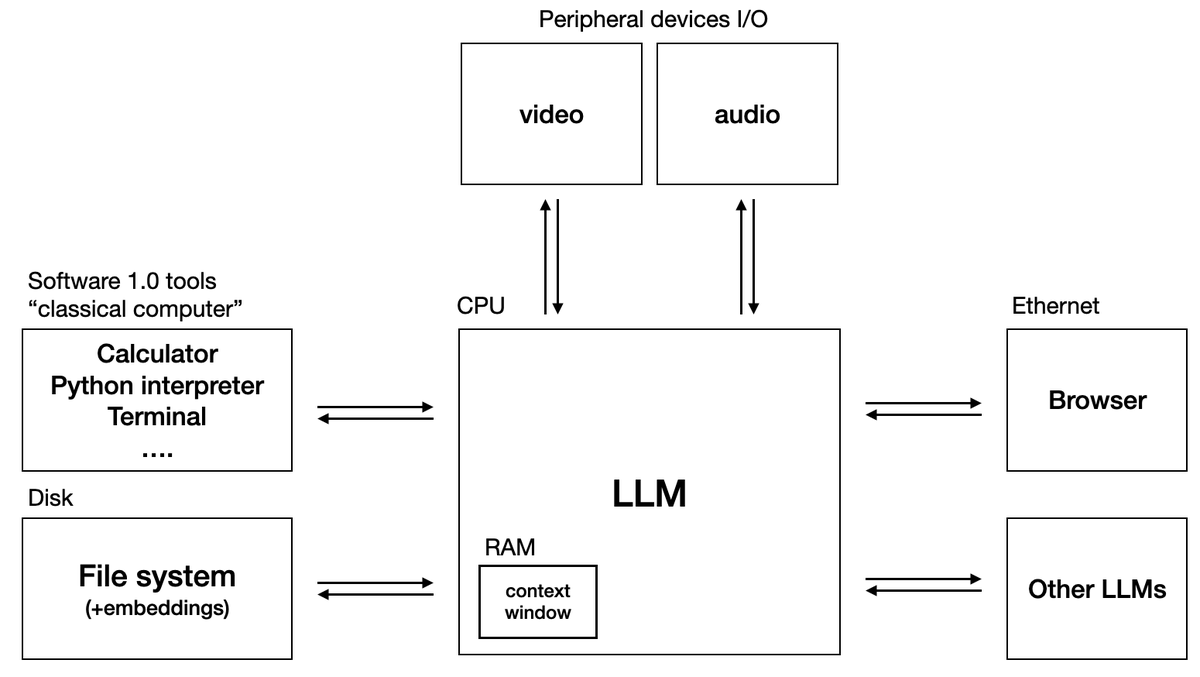
This reminds me of Karpathy's llm os (https://t.co/N8IR4VuYTl).
In that, and in many approaches I've seen online, the basic tree-based fs seems like a given. Notion, Coda, et. al. are built on "blocks", but I haven't yet seen how that significantly aids in content generation (e.g. coding, writing, etc.).
Interesting to read through this paper on semantic file systems (https://t.co/VppYbUXSBa) in light of agentic search (e.g. swe-grep) vs vector dbs (e.g. the cursor approach).
At a glance, it seems to me that these approaches are kind of mutually exclusive, but I'm not sure if my understanding there is entirely accurate.
Having used Claude Code and Cursor, both of which operate on my local fs (tree-based), I'm curious if changing the underlying fs design is in the cards for these kinds of tools.
The vector stores that these tools use certainly function as an index on top of the raw files. So does agentic search augment this index? Or obviate it?
launching @waldium on product hunt
built an AI that:
→ researches trending topics
→ generates content
→ publishes to your blog (hosting included)
→ optimizes for AI search
CI/CD for your content
support us: https://t.co/zS8U6ZIcnR
@ProductHunt
Modern marketing can be reframed as a process of domain-specific training data generation whose primary purpose is to teach both human and agents how to model, reason about, and act in relation to your business. Every artifact.. web copy, documentation, sales decks, blog posts, support threads, etc functions as labeled examples in a corpus that defines the ontology of your company: what entities exist (products, features, roles), what relations connect them (pricing, workflows, integrations), and what distributions describe them (use cases, success rates, benchmarks).
@lennysan Writing technical blog posts. With architecture diagrams (mermaid), direct code snippets, create sample/test endpoints for getting data + charts.
We’re live on @eventbrite with our first webinar!
Catch @amruthagujjar talking about AI Content Engineering for Demand Generation
https://t.co/f6oaVitfUu
I’m excited to finally share blogwald, something we’ve been burning the midnight oil to put out (put on?).
Blogwald helps businesses understand and optimize their content for AI discovery and citation.
- Auto-generated llms.txt & llms-full.txt endpoints so LLMs ingest structured, meaningful markdown.
- Crawlability analytics to see exactly how AI agents interact with your content.
- Developer API for scalable, volume publishing.
As agents become primary content consumers, this is the next layer of content creation, visibility and optimization.
Try it today: https://t.co/9rpjiykfeI
We built a system that detects highly complex objects NO vision model can find—introducing tool use for vision. 🧵
Say you wanted to detect for the @ycombinator logo in this image. (▶️ see step-by-step thinking)
Using our solution, it's able to detect the logo perfectly, *zero-shot* with just a single prompt!
Try it out: https://t.co/rKT3NBhM6y
Code: https://t.co/V5G9csfVhT
1/10