i hooked my whoop to my work calendar to find which coworker gives me the most stress 🚨
thanks to fable, I reverse engineered whoop to pull per minute heart rate. nd matched spikes with cal events and attendees
I now have a leaderboard and I think about it daily.
few info masked for obvious reasons ;)
Workflows are the biggest upgrade to Claude Code’s capabilities since skills and subagents.
I dove deep into it with @sidbid to figure out best practices, examples and more. I’m particularly excited about the non-technical tasks it enables for Claude Code.
In the last 6 months at @Ahrefs, we analyzed over 1 billion data points across 14 studies. Here's what we learned about AI search optimization:
1) "Best X" blog listicles are the single most prominent content format cited by AI chatbots. They make up 43.8% of all page types cited by ChatGPT specifically.
2) 67% of ChatGPT's top 1,000 citations come from sources marketers can't influence: Wikipedia (29.7%), homepages (23.8%), app stores (6.6%). Only 32.3% are influenceable content like educational pages, reviews, news, and blog posts.
3) 28.3% of ChatGPT's most-cited pages have zero Google organic visibility. These pages get cited repeatedly by ChatGPT despite not ranking in Google at all. A completely separate discovery layer.
4) ChatGPT only cites about 50% of the URLs it retrieves. It fetches dozens of pages per query but uses half as background context without attribution. This means that being retrieved and being cited are very different things.
5) Adding schema markup had zero meaningful impact on AI citations. AI Overviews actually dipped −4.6%, while AI Mode (+2.4%) and ChatGPT (+2.2%) showed changes indistinguishable from zero.
6) YouTube mentions have the highest correlation (0.737) with AI brand visibility out of all the factors we studied (including all the conventional SEO metrics like backlinks, page count, DR, etc). This held true for both Google-owned and OpenAI products.
7) AI Overviews reduce clicks to the #1 result by 58%. That’s up from 34.5% just 10 months earlier. The trend is accelerating.
8) 99.9% of AI Overviews appear on informational intent queries. Transactional, navigational, and local searches are almost entirely AIO-free. Shopping triggers AIOs just 3.2% of the time.
9) For a given search query, Google’s AI Mode and AI Overviews reach the same conclusions 86% of the time — but cite almost entirely different sources (only 13.7% citation overlap).
10) AI Overviews change every 2.15 days on average, with 70% of content differing between consecutive observations. But semantic similarity stays at 0.95. The words, sources, and entities constantly shuffle, but the actual meaning barely moves.
The fallacy of this is that more creates more. More hours, more hiring, more something.
And it is true in a sense. If you put in more work, more work will happen. But I think for most startups, the leverage is really in how differently you approach the problem, how well you cultivate your team, and the strategy.
Any large company can outspend you on hours. They have thousands or tens of thousands more people, spending more hours. If hours worked were the metric, every large company and government organization would always win and do the best work. More hours, better output.
This thinking is often representative of younger founders, where the startup becomes their identity and life. They have a hard time doing anything else, and cannot understand that your work is not the person that is you. But activities outside of work can grow you as a person too and make you do better work.
I’ve never worked this way. As a designer, I always saw the need to take a step back, to take a break. At times, I might work 12 hours or 16 hours, or whatever amount was needed, but it wasn’t the norm. You just can't grind design, you need inspiration. But taking that step away from the work, would give me more perspective, inspiration and I could approach the problem differently or I could just see the solution.
Grinding is never good for any creative problem, and startups or creating new products are often mostly about creative problem solving. Grinding works ok for email jobs, or where you just executing on very clear playbook.
With Linear, we’ve never worked this way. We work reasonable hours, 5 days a week. All of us founders have families. Many of our employees have families. I personally stop every evening, spend time with the family, cook dinner for the family, eat dinner together, and focus on things outside of work. Sometimes I work in the late evenings or weekends, but to me the pride is that I don’t need to. Company should be succesful without it.
My goal is to build a company that is sustainable in the long term, and doesn’t require heroics or personal sacrifices every single day.
There are times when our team is heroic. Launches, incidents, some other work that just needs to be done. They will work late into the night because they know it is the right thing. But we don’t require that every day or every week, and the more this happens, the more I think it is a failure of our company and leadership. The team and the leaders should always keep a reserve to use when something is needed.
Our thinking was also that quality, which we value, doesn’t emerge from working more or stressing people more. It emerges when you create the conditions for it to emerge. Often it is the appreciation, space, time, and how the person feels. A person who is rested will do better work.
I wouldn’t attribute much of our success to working a lot. The success came from having clear thinking, ideas, and focus to do the right things.
I sometimes wish we could move the culture more toward a Zen master.
Real mastery is not exerting the most effort. It is achieving the outcome with the least necessary effort.
I've got an agent in a loop optimizing a renderer with the goal to minimize frame times (and tests to measure). It got times down from 88ms to 2ms and allocations down from ~150K to 500. Sounds good, right? Wrong. This is exactly why agent psychosis is a big fucking problem.
As an experiment, I rewrote the Ghostty core render state in Go, with access to identically laid out data structures as Ghostty and the exact same validation tests. I made a purposely naive renderer (simple, correct, but slow). 88ms per frame with 150,000 allocations (horrendous, lol)!
I then kickstarted a Ralph loop to bring the frame times down. I told it it can't modify input data structures or the public API or tests (they're correct), but it can do anything else it wants. It got to work.
It has worked for about 4 hours. I've spent around $350 on this experiment so far. The results?
88ms => 1.5ms
150K allocs => ~500 allocs
Incredible right? Nope.
My hand-written renderer I ported has frame times (same benchmark) of ~20us (0.020ms) and 0 allocations in the update path.
This is the problem with psychosis and lacking systems understanding. If you don't understand the system, you're going to accept that this is an incredible result. If you understand the system, you'll see better solutions immediately and can do roughly 75x better on throughput.
The people who blindly trust agent output are in the former camp. They're sheeple, overdrinking from a fountain of mediocrity.
Standard disclaimer: I use AI all the time. I like AI. The point I'm making is to not blindly accept results. Think. Analyze. Learn.
Why is the creator of OpenCode pretty skeptical about AI productivity gains, and the hype around AI? A very conversation @thdxr (and lots of truth bombs:)
Timestamps:
00:00 Intro
07:03 Dax’s path into tech
09:04 Early startup experience
13:16 Getting involved with open source
16:13 OpenCode
23:17 Anthropic banning OpenCode
30:34 From terminal to GUI
32:34 OpenCode’s business model
36:33 Why inference is profitable
39:11 GPU bottlenecks
40:54 AI hype
45:50 AI spending
48:47 Dax’s memo
55:41 Dax’s skepticism of predictions
58:58 Engineering culture at OpenCode
1:02:38 How building works at OpenCode
1:05:36 Taste and quality
1:11:32 Dax’s work setup
1:12:35 The role of engineers and EMs
1:15:50 Advice for engineers
1:18:12 Book recommendation
Brought to you by:
• @AntithesisHQ – verify your system’s correctness without human review or traditional integration tests – and avoid bugs or outages https://t.co/AKYm4cbVCU
• @WorkOS – everything you need to make your app enterprise ready https://t.co/aiAee0oF5h
• @turbopuffer – a vector and full-text search engine built on object storage. It’s fast, cheap, and extremely scalable https://t.co/w9y67Gs8ab
Three interesting thoughts from Dax:
1. No AI-native coding agent company is “winning” by being better with AI.
Dax says that none of OpenCode’s competitors are crushing them, and that nobody is using AI so well that others cannot compete.
2. Most software engineers profit from AI as time gained, not increased output — unless you change incentives!
Dax says the natural way for software engineers to “cash out” their AI tooling gains is with time savings, by doing the same work as before, but faster. Until compensation and motivation structures change, most teams should expect output to stay flat while engineers go home earlier. There’s nothing wrong with this, but AI vendors sell a different outcome to CFOs: increased output.
3. AI code generation mutes the “guilt” of doing the wrong thing, but this builds up tech debt.
Pre-AI, writing a hack felt bad, the second time it felt really bad, and by the third time you’d often just refactor in order to fix up the code. Now, the agent hides the hack, which skews devs’ judgment and results in less tech debt being cleaned up.
Man. Changing my algo from political slop to engineering and robotics has been so refreshing, so many new awesome people to follow and who are following me as well. I am going to keep posting content from current and past work from my career in robotics, my path moving forward, and stuff in between. Glad to be out of that rut of depressing x feeds. It didn't take long to change it up either. Here's a pretty cool robot EOAT I did for a customer who manufactured Amazon infrastructure hardware. I also did about 25 robotic welding cells for them.
You might believe you should spend less time thinking about code because of AI.
I strongly disagree! We’re watching this play out live where tons of AI generated code becomes a liability.
At the end of the day, an engineer needs to be responsible / on call for code that gets shipped to production. If you don’t understand the system you’re trying to debug, you’re probably going to have a bad time.
Yes, AI can help with all of this, if you set up the proper systems. You can have agents triage prod logs, look at errors, etc. You can speed up parts of the investigation, but an engineer needs to make the call. There might be serious customer or financial implications from that change.
I expect the trend continue for trimming dependencies, vendoring code so you can modify it directly, preferring simpler systems with fewer abstractions, and spending waaaay more time thinking about system design and code maintenance.
I’ve said this before, but it’s a great time to get familiar with CS fundamentals and some of the history behind what great software looks like. Many parts will be different in the coming years as AI progresses, but also a lot more than people realize will stay the same.
🚀 Just launched: ExtendDB — an open source DynamoDB-compatible adapter written in Rust.
✅ Full wire-protocol compatibility ✅ PostgreSQL storage backend ✅ Pluggable architecture for more backends ✅ Works with existing AWS SDKs & CLI
Apache 2.0 | v0.1 — come build with us 🛠️
https://t.co/U6xouvSRwX
Yoo I know I am a bit late with the list tho ... I hope you are able to squeeze enough time to dedicate atleast 30 mins of your day to read 1 article per day or maybe 2
I have also added few of my fav developer blogs/articles too
Companies
# Dropbox
- Why we chose apache superset as our data exploration platform : [https://t.co/H43FGKUVnu]
- How low-bit inference enables efficient AI : [https://t.co/8fgYTrFuxS]
- Reducing our monorepo size to improve developer velocity : [https://t.co/UcaNi8CuUp]
- Selecting a model for semantic search at Dropbox scale : [https://t.co/aFNkXj7xSD]
- What’s new with Robinhood, our in-house load balancing service : [https://t.co/W0yliQukkz]
# Twilio
- Build an AI Video Analysis App with FastAPI, OpenAI, and SendGrid : [https://t.co/mZsiV5RWtv]
- Calculating Character Count of RCS Messages : [https://t.co/9f6PhHSNQs]
- Making Alt Text Fast: How Twilio Scaled Docs Accessibility with Automation : [https://t.co/HiFbZm1rzG]
# Reddit
- Evolving Signals-Joiner with Custom Joins in Apache Flink : [https://t.co/Kp6g11Ntde]
- Query Autocomplete from LLMs : [https://t.co/NHUC0AEwfm]
- Evolution of Reddit's In-house P0 Media Detection : [https://t.co/xiNiZwi66h]
- An In-Depth Look at the Notifications Recommender System : [https://t.co/ici4TDGSQT]
# Pinterest
- How Pinterest Built a Real‑Time Radar for Violative Content using AI : [https://t.co/Y5GMBisqRy]
- Next-Level Personalization: How 16k+ Lifelong User Actions Supercharge Pinterest’s Recommendations : [https://t.co/ApbhzphBkg]
# Bumble
- Who, where, when: a components system for allotting team member responsibilities : [https://t.co/OfaQXMxzvM]
Developers Blog list
Some developers blog list I love to go through for maximum experience learning ... What is Experience Learning ?? Something which an engineer learns only while experiencing new problems, new limitations, new constraints from different situations ...
# Pragmatic Engineer
- Cloudflare rewrites Next.js as AI rewrites commercial open source : [https://t.co/qwZ0gwEqUl]
- Is the FDE role becoming less desirable? : [https://t.co/F3BH4hpy5D]
# Julia Evans (1/3 top favs of my list)
- Examples for the tcpdump and dig man pages: [https://t.co/Fh2Ywc8fTL]
- Using `make` to compile C programs (for non-C-programmers) : [https://t.co/bhqoB4vQVs]
- What helps people get comfortable on the command line? : [https://t.co/41C3YfM6vm]
# Dan Lu
- Tracing vs Sampling : [https://t.co/SvznCZXquS]
- How are coorporate blogs are written : [https://t.co/y2hMBboOzy]
# Martin Fowler (2/3 top favs)
- APIs should not be copyrightable : [https://t.co/m2FDr2d7P2]
- Refactoring Module Dependencies : [https://t.co/53glO8Y8w5]
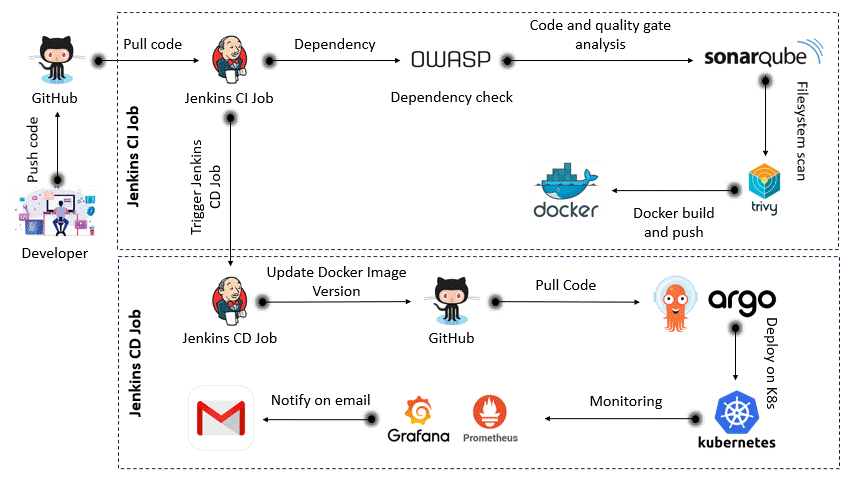
From GitHub -> Jenkins -> Docker -> Kubernetes -> complete DevOps workflow.
Many people learn DevOps tools individually.
But the real value comes from understanding how these tools work together in a real pipeline.
Here’s a simplified breakdown of the 𝐞𝐧𝐝-𝐭𝐨-𝐞𝐧𝐝 𝐂𝐈/𝐂𝐃 𝐟𝐥𝐨𝐰 shown in the diagram
𝐂𝐈 𝐏𝐢𝐩𝐞𝐥𝐢𝐧𝐞 (𝐁𝐮𝐢𝐥𝐝 & 𝐒𝐜𝐚𝐧)
‣ Developer pushes code to GitHub
‣ Jenkins CI pulls the code and triggers the pipeline
‣ OWASP Dependency Check scans for vulnerable libraries
‣ SonarQube performs code quality & security analysis
‣ Docker builds the image
‣ Trivy scans the image for vulnerabilities
‣ Image is pushed to the registry
𝐂𝐃 𝐏𝐢𝐩𝐞𝐥𝐢𝐧𝐞 (𝐃𝐞𝐩𝐥𝐨𝐲)
‣ Jenkins CD updates the image version
‣ Changes pushed back to GitHub
‣ ArgoCD pulls the latest changes
‣ Deploys application to Kubernetes
𝐌𝐨𝐧𝐢𝐭𝐨𝐫𝐢𝐧𝐠 & 𝐀𝐥𝐞𝐫𝐭𝐬
‣ Prometheus collects metrics
‣ Grafana visualizes dashboards
‣ Email notifications for pipeline status
𝐓𝐡𝐢𝐬 𝐢𝐬 𝐰𝐡𝐚𝐭 𝐜𝐨𝐦𝐩𝐚𝐧𝐢𝐞𝐬 𝐞𝐱𝐩𝐞𝐜𝐭 𝐲𝐨𝐮 𝐭𝐨 𝐮𝐧𝐝𝐞𝐫𝐬𝐭𝐚𝐧𝐝:
‣ CI (build + scan)
‣ CD (deploy + automate)
‣ Security (shift-left approach)
‣ Monitoring (production visibility)
Kubernetes is beautiful.
Every Concept Has a Story, you just don't know it yet.
In k8s, you run your app as a pod. It runs your container. Then it crashes, and nobody restarts it. It is just gone.
So you use a Deployment. One pod dies and another comes back. You want 3 running, it keeps 3 running.
Every pod gets a new IP when it restarts. Another service needs to talk to your app but the IPs keep changing. You cannot hardcode them at scale.
So you use a Service. One stable IP that always finds your pods using labels, not IPs. Pods die and come back. The Service does not care.
But now you have 10 services and 10 load balancers. Your cloud bill does not care that 6 of them handle almost no traffic.
So you use Ingress. One load balancer, all services behind it, smart routing. But Ingress is just rules and nobody executes them.
So you add an Ingress Controller. Nginx, Traefik, AWS Load Balancer Controller. Now the rules actually work.
Your app needs config so you hardcode it inside the container. Wrong database in staging. Wrong API key in production. You rebuild the image every time config changes.
So you use a ConfigMap. Config lives outside the container and gets injected at runtime. Same image runs in dev, staging and production with different configs.
But your database password is now sitting in a ConfigMap unencrypted. Anyone with basic kubectl access can read it. That is not a mistake. That is a security incident.
So you use a Secret. Sensitive data stored separately with its own access controls. Your image never sees it.
Some days 100 users, some days 10,000. You manually scale to 8 pods during the spike and watch them sit idle all night. You cannot babysit your cluster forever.
So you use HPA. CPU crosses 70 percent and pods are added automatically. Traffic drops and they scale back down. You are not woken up at 2am anymore.
But now your nodes are full and new pods sit in Pending state. HPA did its job. Your cluster had nowhere to put the pods.
So you use Karpenter. Pods stuck in Pending and a new node appears automatically. Load drops and the node is removed. You only pay for what you actually use.
One pod starts consuming 4GB of memory and nobody told Kubernetes it was not supposed to. It starves every other pod on that node and a cascade begins. One rogue pod with no limits takes down everything around it.
So you use Resource Requests and Limits. Requests tell Kubernetes the minimum your pod needs to be scheduled. Limits make sure no pod can steal from everything around it. Your cluster runs predictably.
I packaged up the "autoresearch" project into a new self-contained minimal repo if people would like to play over the weekend. It's basically nanochat LLM training core stripped down to a single-GPU, one file version of ~630 lines of code, then:
- the human iterates on the prompt (.md)
- the AI agent iterates on the training code (.py)
The goal is to engineer your agents to make the fastest research progress indefinitely and without any of your own involvement. In the image, every dot is a complete LLM training run that lasts exactly 5 minutes. The agent works in an autonomous loop on a git feature branch and accumulates git commits to the training script as it finds better settings (of lower validation loss by the end) of the neural network architecture, the optimizer, all the hyperparameters, etc. You can imagine comparing the research progress of different prompts, different agents, etc.
https://t.co/YCvOwwjOzF
Part code, part sci-fi, and a pinch of psychosis :)
There are many fields in which AI can streamline processes and automate tedious tasks.
And one area with many applications for AI tools and technologies is agriculture.
In this book, Vahe details how AI can help increase crop yields, use water more efficiently, predict and react to stormy weather, and more.
https://t.co/0HswPOr3iW
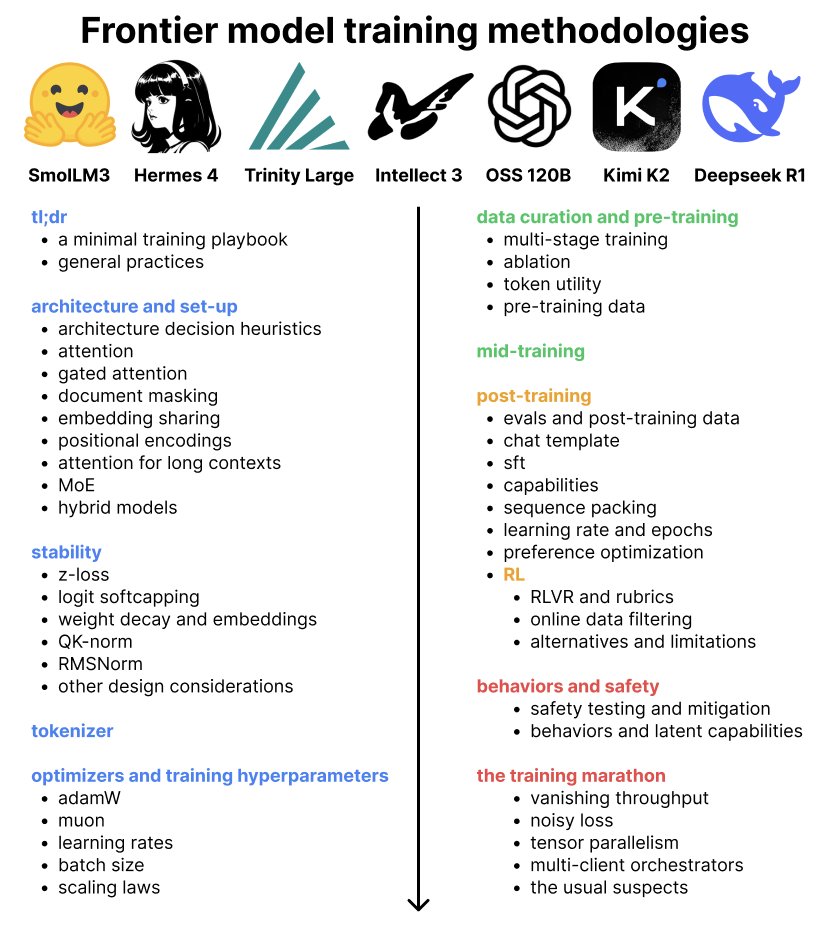
new blog! What methodologies do labs use to train frontier models?
The blog distills 7 open-weight model reports from frontier labs, covering architecture, stability, optimizers, data curation, pre/mid/post-training + RL, and behaviors/safety
https://t.co/88heRH4TcO