Excited to have Martin Scorsese as an advisor.
Stories will always have to be personal, but they can be woven together with new tools. That's what we strive to build at Black Forest Labs.
Martin Scorsese is an advisor to Black Forest Labs.
He's spent six decades shaping how the world sees stories. Now he's helping us shape visual intelligence with human taste and craft at the center.
We sat down with him for a working storyboarding session using FLUX.
Seeing Martin Scorsese using FLUX for storyboarding and scene exploration was absolutely insane. Experiencing how one of the absolute masters of cinema & filmmaking uses the technology that we developed, his curiosity and creativity, and the way he prompted our models, was humbling.
I am grateful to call Martin Scorsese an advisor to BFL, and to explore the next, multimodal and interactive phases of visual AI with him.
today, we @amppublic are announcing a $500M profit pool we have set aside to help local communities navigate the AI transition over the next few years
we'd love to hear ideas for the best way to distribute these funds
anyone can submit here: https://t.co/dpFyZldbXy
Five years ago, I recorded my first YouTube video.
Today, I’m going full-time on @tbpn.
My time at Founders Fund was incredible.
Here’s 10,000 hours in 48 seconds:
Fixed vision encoders like DINO have driven impressive progress in more learnable representations for generative modeling - but there is no universal variant across modalities, and they do not scale with the generative model.
We introduce our self-supervised framework, Self-Flow, that builds learnability directly into flow models, working in a unified and scalable way across image, video and audio.
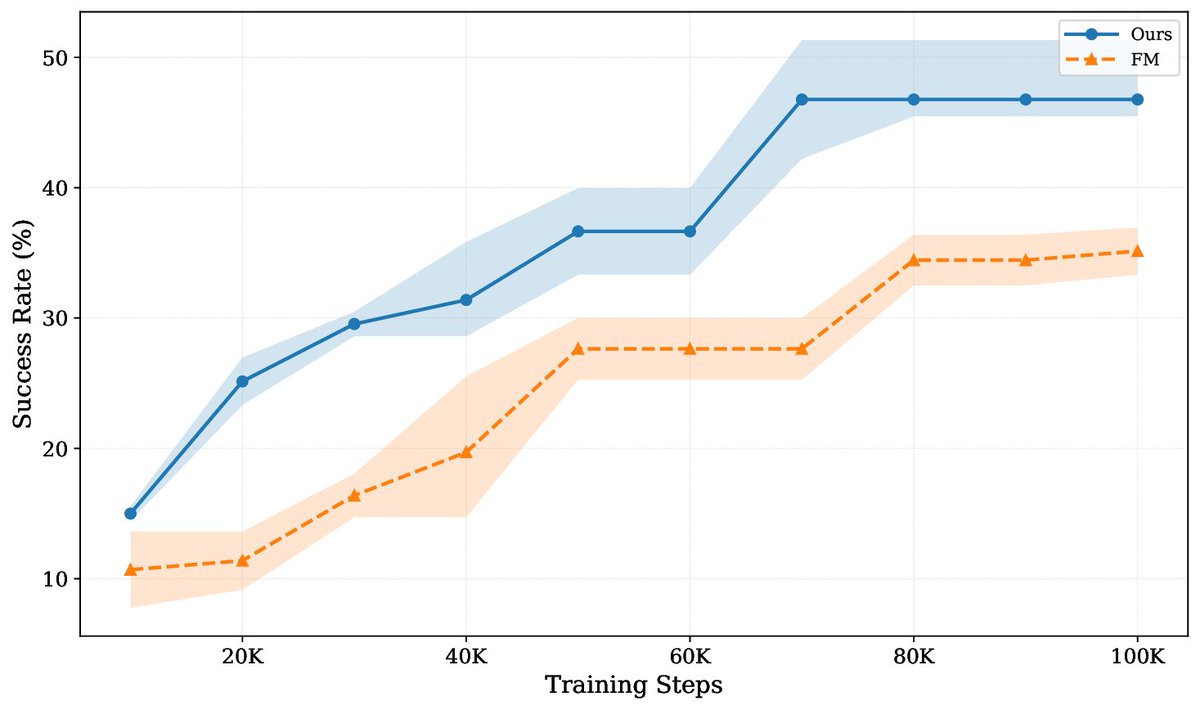
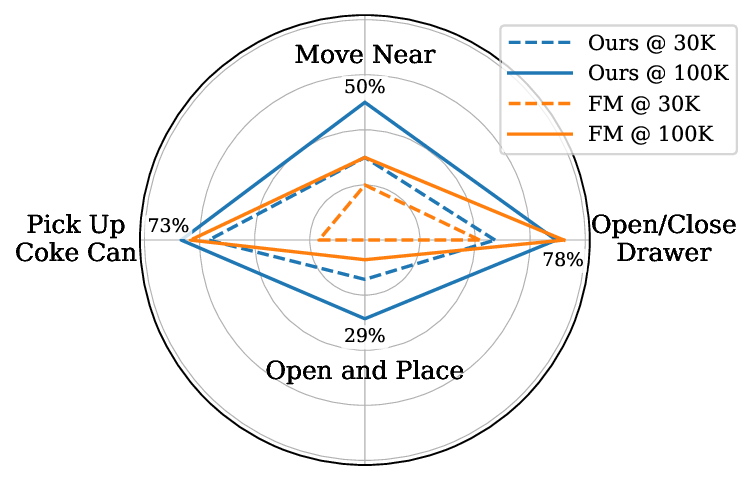
Particularly excited about the gains on video-action prediction: Beyond the overall success rate improving substantially, more complex tasks - like "Open and Place" - see some of the clearest gains. So many interesting research questions to explore to make 🤖 go brrr
Super glad to be working with my amazing colleagues @hila_chefer, Dominik, @dustin_podell, Vikash, @Vinh_Suhi, Antonio and @robrombach - as well as the whole @bfl_ml team!
arxiv: https://t.co/eP7ip58Tff
project page: https://t.co/GNShpBMEQ1
New research from @bfl_ml 🥳
Meet Self-Flow: our self-supervised framework for image, audio, video & world models 🤖
https://t.co/AshY8IkSEe
Do generative models really need DINO to learn strong representations? We propose teaching them directly via a joint framework instead 🧵
We present a research preview of Self-Flow: a scalable approach for training multi-modal generative models.
Multi-modal generation requires end-to-end learning across modalities: image, video, audio, text - without being limited by external models for representation learning. Self-Flow addresses this with self-supervised flow matching that scales efficiently across modalities.
Results:
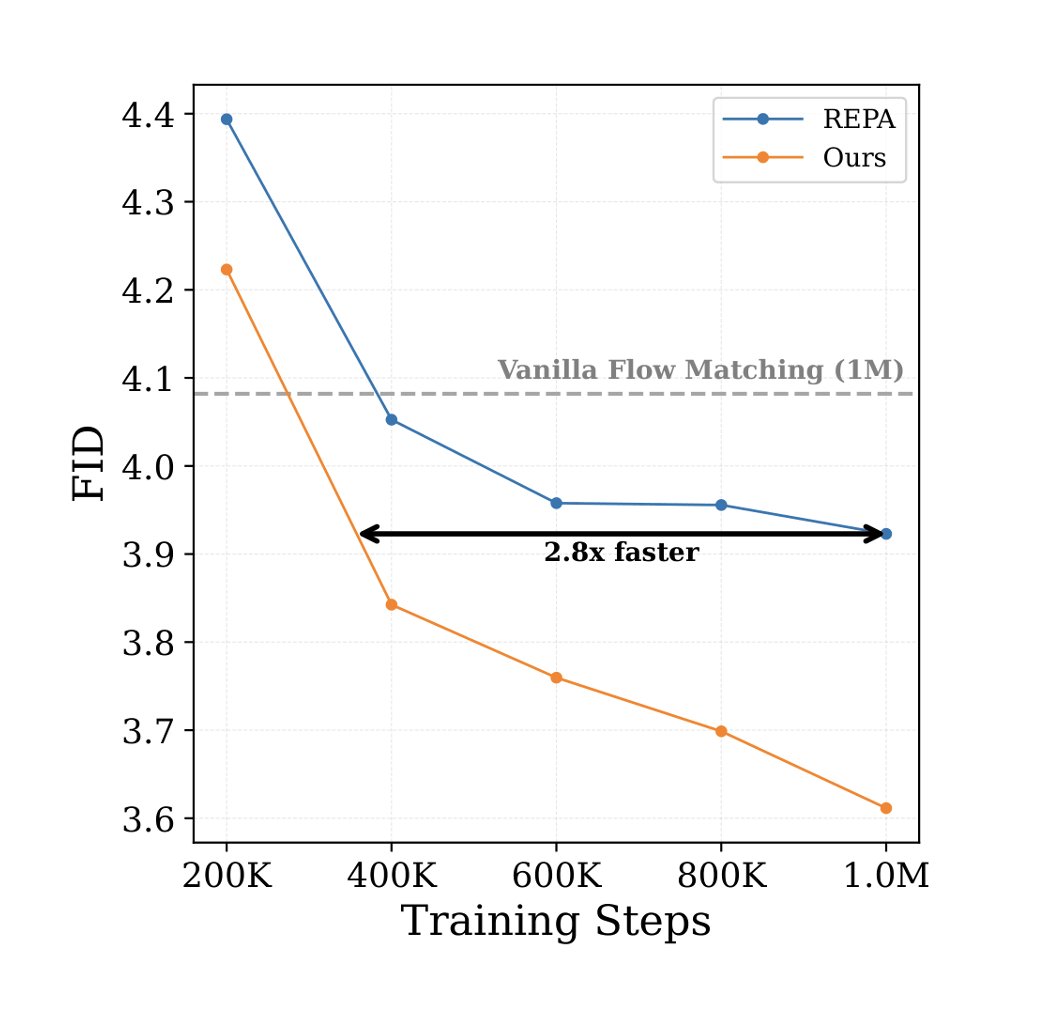
• Up to 2.8x faster convergence across modalities.
• Improved temporal consistency in video
• Sharper text rendering and typography
This is foundational research for our path towards multimodal visual intelligence.
Mercury 2 is live 🚀🚀
The world’s first reasoning diffusion LLM, delivering 5x faster performance than leading speed-optimized LLMs.
Watching the team turn years of research into a real product never gets old, and I’m incredibly proud of what we’ve built.
We’re just getting started on what diffusion can do for language.
🚨 FLUX.2 from @bfl_ml is here on fal - day 0 release!
🎨 Generate and edit images with incredible quality
🎯 HEX codes and JSON prompts for better control
🎬 Pro and Flex: High-fidelity images and text rendering
⚡ Dev: LoRA training for customization
https://t.co/N1Ezd8zhZO
FLUX.2, from @bfl_ml, is now available in ElevenLabs Image & Video.
Real-world lighting and spatial accuracy. 4MP fidelity. Multi-reference control.