ANN Engineer in GPS PNT - And neural network on a quest for cat videos, brain-inspired ML, CS, and math. Probably in that order. Ph.D. Former HPC-CTX research
@Artoftheproblem@a16z People should not come away from this video thinking cerebellum is *the* world model prediction circuit. Many areas predict, contain a world model. See cortical and hippocampal literature. Cerebellum does have a map of the body and cognitive area, helping error correct model.
Most neural nets are still based on the model of a neuron as proposed in the 1950's: u = activation(w·x + b)
In a new paper, researchers propose a more accurate model of a biological brain neuron and found that it has quite a few advantages, like needing less training data.
we've already seen that biology models represent features in curved geometries — see our work on a fragmentomic signal for alzheimer's! our neural geometry agenda is bringing us closer to understanding models' natural ontologies
some of the most interesting artifacts in history
Neural networks might speak English, but they think in shapes.
Understanding their rich *neural geometry* is key to understanding how they work – and to debugging and controlling them with precision.
Starting today, we’re releasing a series of posts on this research agenda. 🧵
This looks amazing. Rats composing long action sequences out of short ones. mPFC constructing the long sequence by Reusing primitive representations but composing overall progression. One of the most impressive things I have ever seen a rodent do.
https://t.co/HxsSArGoxt
Research we co-authored on subliminal learning—how LLMs can pass on traits like preferences or misalignment through hidden signals in data—was published today in @Nature.
Read the paper: https://t.co/b1BYwcW9dH
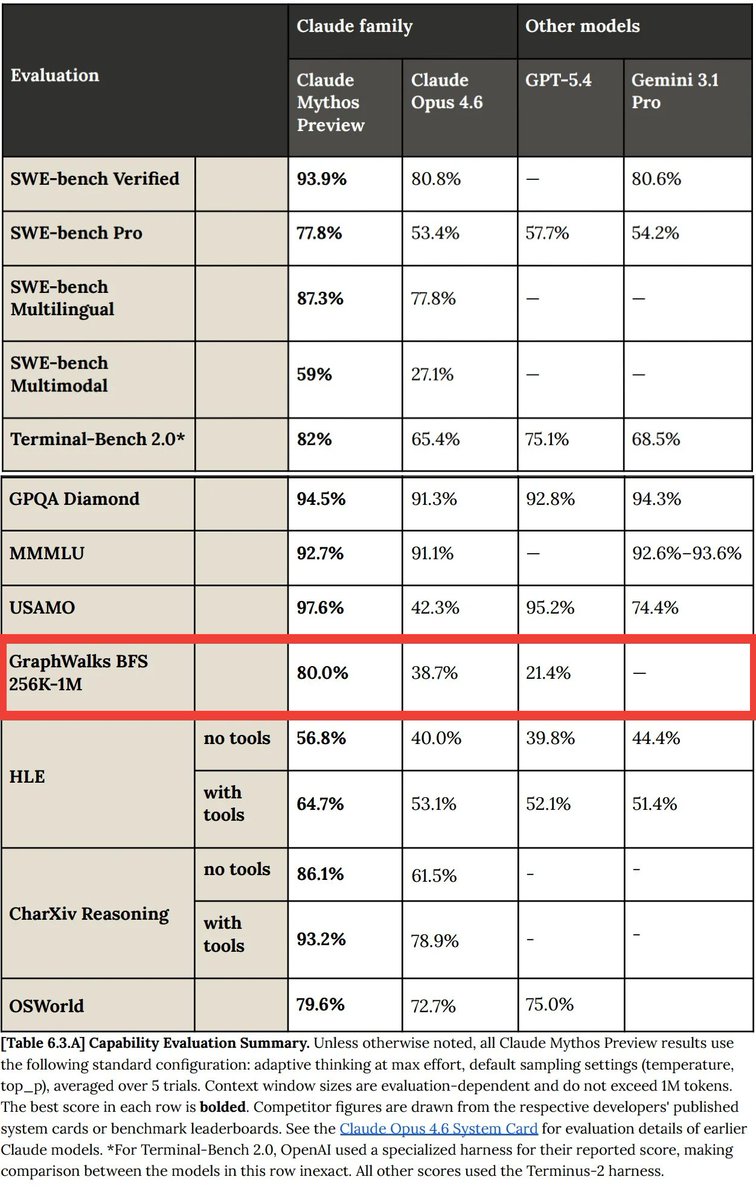
I strongly suspect that Claude Mythos is a looped language model, as described in the paper "Scaling Latent Reasoning via Looped Language Models" from ByteDance
The authors of that paper called out graph search as one of the areas where looping provides a huge theoretical advantage over standard RLVR. And look at where Mythos blows out its competitors the most
Software horror: litellm PyPI supply chain attack.
Simple `pip install litellm` was enough to exfiltrate SSH keys, AWS/GCP/Azure creds, Kubernetes configs, git credentials, env vars (all your API keys), shell history, crypto wallets, SSL private keys, CI/CD secrets, database passwords.
LiteLLM itself has 97 million downloads per month which is already terrible, but much worse, the contagion spreads to any project that depends on litellm. For example, if you did `pip install dspy` (which depended on litellm>=1.64.0), you'd also be pwnd. Same for any other large project that depended on litellm.
Afaict the poisoned version was up for only less than ~1 hour. The attack had a bug which led to its discovery - Callum McMahon was using an MCP plugin inside Cursor that pulled in litellm as a transitive dependency. When litellm 1.82.8 installed, their machine ran out of RAM and crashed. So if the attacker didn't vibe code this attack it could have been undetected for many days or weeks.
Supply chain attacks like this are basically the scariest thing imaginable in modern software. Every time you install any depedency you could be pulling in a poisoned package anywhere deep inside its entire depedency tree. This is especially risky with large projects that might have lots and lots of dependencies. The credentials that do get stolen in each attack can then be used to take over more accounts and compromise more packages.
Classical software engineering would have you believe that dependencies are good (we're building pyramids from bricks), but imo this has to be re-evaluated, and it's why I've been so growingly averse to them, preferring to use LLMs to "yoink" functionality when it's simple enough and possible.
As always, very interesting work by @scott_linderman et al! They let the dynamical system itself evolve over trials, which allows modeling representational drift. Very interesting read for the neural manifold crowd as well
I am totally pumped about this new work. "Task-trained RNNs" are a powerful and influential framework in neuroscience, but have lacked a firm theoretical footing. This work provides one, and makes direct contact with the classical theory of random RNNs.
https://t.co/queri4DIv9
Prof. Donald Knuth opened his new paper with "Shock! Shock!"
Claude Opus 4.6 had just solved an open problem he'd been working on for weeks — a graph decomposition conjecture from The Art of Computer Programming.
He named the paper "Claude's Cycles."
31 explorations. ~1 hour. Knuth read the output, wrote the formal proof, and closed with: "It seems I'll have to revise my opinions about generative AI one of these days."
The man who wrote the bible of computer science just said that. In a paper named after an AI.
Paper: https://t.co/juSOmK9vOt
It’s extremely good that Anthropic has not backed down, and it’s siginficant that OpenAI has taken a similar stance.
In the future, there will be much more challenging situations of this nature, and it will be critical for the relevant leaders to rise up to the occasion, for fierce competitors to put their differences aside. Good to see that happen today.
A really dangerous situation. Too many submissions. Too many generated papers. Little responsibility.
1. In 2026, more than 24,000 submissions were made to the International Conference on Machine Learning (ICML). It’s TWO times more than in 2025. To fight it, the organizers now require researchers to pay $100 for every subsequent paper.
2. LLM adoption has increased researcher productivity by 90% (there’s a recent paper in Science).
3. The number of papers is becoming far too high. Submissions to arXiv have risen by 50% since 2022.
4. There are simply not enough reviewers. Plus, many scientists no longer want to invest precious time in it for free.
5. We can’t easily identify AI-made papers from the genuine ones.
__
Important words from Paul Ginsparg, a co-founder of arXiv:
“AI slop frequently can’t be discriminated just by looking at abstract, or even by just skimming full text. This makes it an “existential threat” to the system.”
Basically, we’re getting closer to the tipping point.
📍 Many professors blame the AI.
But the problem is likely elsewhere:
1. Without a sufficient number of papers, many PIs can’t get funded. They have to prove their credibility to reviewers. Their proposals have to rely on prior publications. In many countries, there are some informal (or even formal) expectations for how many papers a group with a certain size has to publish to survive (funding-wise).
2. Our students / postdocs need papers if they want to be hired in faculty roles. Yes, some departments hire people with few publications. But the majority still want to ensure their faculty can get funded. If funding is partly a function of papers, this is used in decision-making.
3. The number of papers is important if you want to get high-level awards. Many of them are not given because you published one paper (even if it’s great). They are given because you made a meaningful CONTRIBUTION to the field. How do you make it? Publish more papers.
4. Tenure promotions in many places take the number of your papers into account (often indirectly). Your tenure may get delayed if you don’t publish enough. Not everywhere, but for many mid- to low-ranked universities this story is more or less the same.
+ There are many more to mention.
📍My opinion:
Much of this is rooted in how funding is distributed.
There is a strong correlation between the requirements at a university and the funding acquisition criteria.
If funding were based ONLY on the quality of published papers, universities would hire people for the quality of their science. If funding agencies strongly discouraged publishing too many papers, universities wouldn’t expect numbers from faculty during promotions. And some supervisors wouldn’t pressure students and postdocs to publish unfinished studies and low-quality data.
Yes, we need good detectors of fake papers.
But we also need the right policies and better funding allocation criteria.
Let's compare our world models. I find that different people seem to have rather distinct internal world models. E.g. I personally have neither visual imagination nor an inner voice, found it weird others do. Here is a quick google forms to check idea: https://t.co/vTwzShRTuP
A number of people are talking about implications of AI to schools. I spoke about some of my thoughts to a school board earlier, some highlights:
1. You will never be able to detect the use of AI in homework. Full stop. All "detectors" of AI imo don't really work, can be defeated in various ways, and are in principle doomed to fail. You have to assume that any work done outside classroom has used AI.
2. Therefore, the majority of grading has to shift to in-class work (instead of at-home assignments), in settings where teachers can physically monitor students. The students remain motivated to learn how to solve problems without AI because they know they will be evaluated without it in class later.
3. We want students to be able to use AI, it is here to stay and it is extremely powerful, but we also don't want students to be naked in the world without it. Using the calculator as an example of a historically disruptive technology, school teaches you how to do all the basic math & arithmetic so that you can in principle do it by hand, even if calculators are pervasive and greatly speed up work in practical settings. In addition, you understand what it's doing for you, so should it give you a wrong answer (e.g. you mistyped "prompt"), you should be able to notice it, gut check it, verify it in some other way, etc. The verification ability is especially important in the case of AI, which is presently a lot more fallible in a great variety of ways compared to calculators.
4. A lot of the evaluation settings remain at teacher's discretion and involve a creative design space of no tools, cheatsheets, open book, provided AI responses, direct internet/AI access, etc.
TLDR the goal is that the students are proficient in the use of AI, but can also exist without it, and imo the only way to get there is to flip classes around and move the majority of testing to in class settings.
@sama "Building a strategic national reserve of computing power makes a lot of sense. But this should be for the government’s benefit, not the benefit of private companies."
Sounds like The ATOM Project (for open models)
https://t.co/ChhNkP0IKL