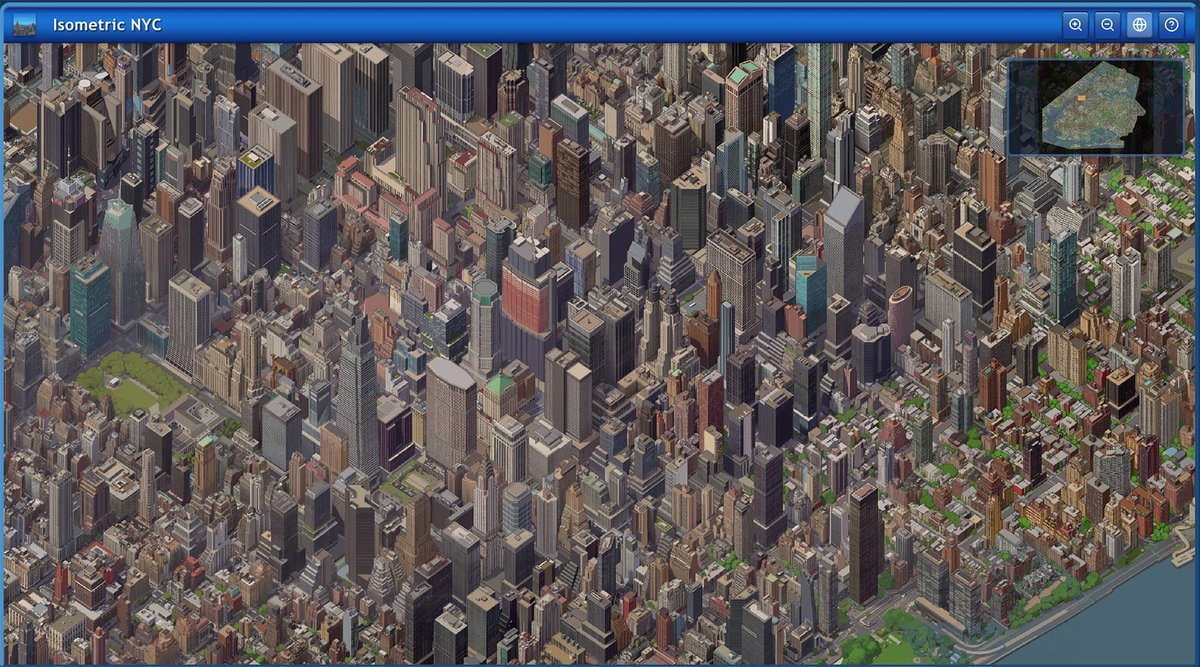
I wanted to share something I built over the last few weeks: https://t.co/QRqMK9CpTR is a massive isometric pixel art map of NYC, built with nano banana and coding agents.
I didn't write a single line of code.
@HardcoreHistory Have you considered publishing the whole catalog of shows to Audible? I have spare credits lying around that I’d definitely spend on HH
"Move 37" is the word-of-day - it's when an AI, trained via the trial-and-error process of reinforcement learning, discovers actions that are new, surprising, and secretly brilliant even to expert humans. It is a magical, just slightly unnerving, emergent phenomenon only achievable by large-scale reinforcement learning. You can't get there by expert imitation. It's when AlphaGo played move 37 in Game 2 against Lee Sedol, a weird move that was estimated to only have 1 in 10,000 chance to be played by a human, but one that was creative and brilliant in retrospect, leading to a win in that game.
We've seen Move 37 in a closed, game-like environment like Go, but with the latest crop of "thinking" LLM models (e.g. OpenAI-o1, DeepSeek-R1, Gemini 2.0 Flash Thinking), we are seeing the first very early glimmers of things like it in open world domains. The models discover, in the process of trying to solve many diverse math/code/etc. problems, strategies that resemble the internal monologue of humans, which are very hard (/impossible) to directly program into the models. I call these "cognitive strategies" - things like approaching a problem from different angles, trying out different ideas, finding analogies, backtracking, re-examining, etc. Weird as it sounds, it's plausible that LLMs can discover better ways of thinking, of solving problems, of connecting ideas across disciplines, and do so in a way we will find surprising, puzzling, but creative and brilliant in retrospect. It could get plenty weirder too - it's plausible (even likely, if it's done well) that the optimization invents its own language that is inscrutable to us, but that is more efficient or effective at problem solving. The weirdness of reinforcement learning is in principle unbounded.
I don't think we've seen equivalents of Move 37 yet. I don't know what it will look like. I think we're still quite early and that there is a lot of work ahead, both engineering and research. But the technology feels on track to find them.
https://t.co/JCxTdKpuzv
02. Sometimes you have to "clean" your layout of unnecessary colors. I need a feature that will allow to group colors by similarity and merge them into one color in case of need. Or to make a general merging of similar colors with a single button. I know there are a lot of pitfalls here, but let's think along these lines, huh?
“Then Apple changes Safari from making Google the default search engine to prompting users with a choice for default search…”
Power move would be Apple extending their OpenAI deal and making SearchGPT the default
https://t.co/LemYTUyXUO