i was reading the SQLite source
and found that DELETE does not actually shrink the database file
deleted pages are placed onto an internal freelist inside the file
new inserts reuse those free pages before growing the database again
the file itself only gets smaller when you run VACUUM
delete everything from a 1GB database and the file is still 1GB until you compact it
New Stanford paper argues that, under equal reasoning budgets, one LLM usually solves multi-hop problems better than many coordinated ones.
The core point is almost embarrassingly simple.
A single agent keeps the whole problem in one internal chain of thought, while a multi-agent system has to slice that chain into messages, summaries, and handoffs.
Every handoff is a compression step.
And once reasoning is compressed, some information is easier to drop than to recover, which is why the paper leans on the Data Processing Inequality as a formal explanation rather than just an empirical hunch.
The experiments back that up across Qwen, DeepSeek, and Gemini on FRAMES and MuSiQue: when thinking-token budgets are matched, single-agent systems usually match or beat sequential, debate, role-based, and ensemble setups.
Here’s the part most people miss.
Many celebrated multi-agent gains may not be architectural gains at all. They often come from spending more test-time compute, surfacing more visible reasoning, or benefiting from evaluation quirks that make the pipeline look smarter than it is.
The paper is especially sharp when it looks for the boundary case instead of pretending the rule is universal.
When the single agent’s effective context is degraded by masking, substitution, or misleading distractors, multi-agent pipelines become more competitive and sometimes win, not because message passing is magical, but because structure can partially stabilize corrupted reasoning.
That is a much narrower and more useful claim than “more agents is better.”
It suggests the real trade-off is not single versus multi so much as latent reasoning versus external coordination, with context quality and compute accounting deciding which side looks stronger.
For multi-hop reasoning, the default should now be clear: start with one strong model, and treat extra agents as a repair strategy, not an upgrade.
----
Paper Link – arxiv. org/abs/2604.02460
Paper Title: "Single-Agent LLMs Outperform Multi-Agent Systems on Multi-Hop Reasoning Under Equal Thinking Token Budgets"
Generating an image from a sentence used to require a separate classifier trained on noisy images just to steer the output toward the prompt.
This paper from OpenAI shows you can drop that. The core idea is classifier-free guidance: during training the text caption is sometimes replaced with an empty one, so a single model learns to predict image noise both with and without text; at generation time you take the difference between the text-conditioned and unconditioned predictions and exaggerate it, which sharpens how closely the image follows the caption with no extra classifier.
The authors built a 3.5 billion parameter diffusion model around this, and human evaluators preferred its output to DALL-E (OpenAI's then-main system at twelve billion parameters) about 87% of the time for photorealism, even when DALL-E was allowed to generate many candidates and keep the best; they also finetuned the same model to fill erased image regions from a prompt, with matching shadows and reflections, making text-driven editing practical.
Classifier-free guidance went on to become standard and is still used in the systems leading the field in 2026 (FLUX.2, later Stable Diffusion, the models behind DALL-E 3 and Imagen).
Read with an AI tutor; https://t.co/c6zqRqaPCD
PDF: https://t.co/sp7MZljI1X
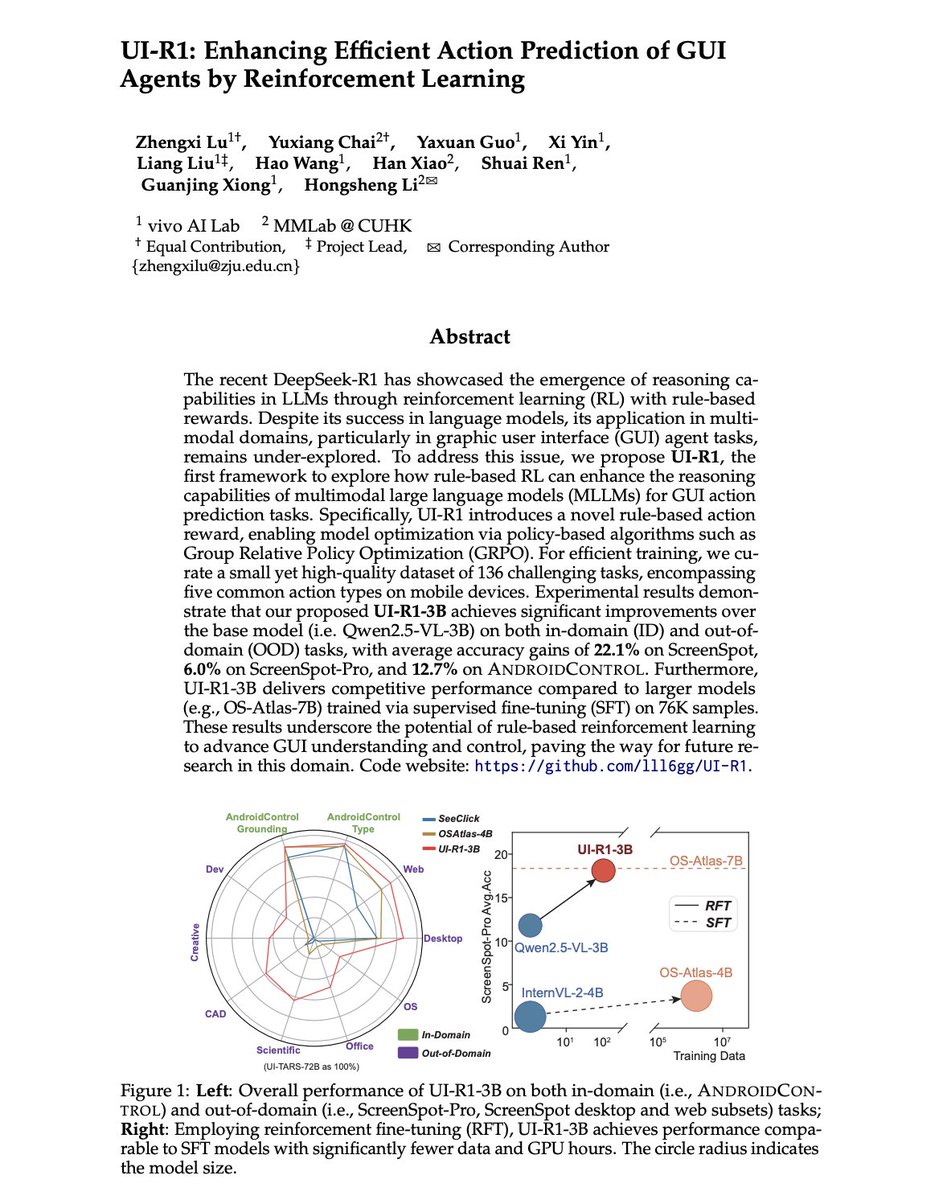
This AAAI 2026 paper introduces UI-R1, a framework demonstrating how rule-based reinforcement learning with a novel action reward significantly enhances multimodal LLM' reasoning capabilities for accurate GUI action prediction, outperforming larger supervised models on challenging in-domain and out-of-domain tasks.
Read with an AI tutor: https://t.co/1DxTqKmDyd
PDF: https://t.co/1mM57KiIAI
This is like a good stress test for optimizers.
Kaon is basically Muon/lmo + spectral noise. It preserves the singular vectors of the gradient and randomizes only the positive singular weights. For exchangeable noise, the conditional expectation is the spectral-norm-ball lmo direction up to scale. Individual draws are not necessarily lmos tho.
Freon’s map for c>1/2 is decreasing on the singular values, so the operator is non-monotone. Exact fixed-step Freon can fail even on a simple convex quadratic minimization near rank deficiency.
Freon’s map for c<=1/2 (i.e., the monotone case) can also be analyzed using phi-convexity. Shameless plug: https://t.co/nm16wKDz9L
Order From Chaos
The Geometry of Emergence
In the 1960s, Ilya Prigogine proposed something profound:
Under the right conditions, chaos does not always destroy structure.
Sometimes it creates it.
He called these dissipative structures:
A hurricane.
Geometric convection cells in heated fluids.
A living cell.
Order arising through instability rather than despite it.
———
Researchers like Karl Friston and Michael Levin are now exploring adjacent principles in biological systems.
Friston’s work on active inference suggests biological systems persist by constantly updating internal models against an unpredictable environment —
stabilizing themselves through perception, prediction, feedback, and energetic exchange.
Order is not static.
It is actively maintained through recursive information processing across dynamic systems.
———
Levin’s work on morphogenesis and basal cognition suggests cells and tissues may function as distributed information-processing networks capable of memory, coordination, and anatomical problem-solving through bioelectric signaling.
Stable biological form emerges not from centralized control…
but from collective cellular communication organizing matter toward persistent anatomical states despite constant molecular fluctuation.
In both Levin’s and Friston’s frameworks, intelligence begins looking less like a property confined to neurons…
and more like an emergent process of dynamic self-organization across relational systems.
>A brain maintaining identity despite neuronal turnover.
>An embryo constructing stable anatomy from unstable substrate.
———
Perhaps intelligence is not fundamentally a thing.
But a process by which matter organizes information across time under constraint.
Not intelligence as object. But intelligence as topology:
Relational geometry stabilized through energy flow, feedback, and adaptive coordination.
// δ-mem: Efficient Online Memory for LLMs //
One of the more elegant memory mechanisms I've seen this month.
Most long-term memory work either inflates context or retrains the model. This paper shows a tiny external state, coupled directly into the attention computation, can do the work that bigger context windows fail at.
It's cheap, modular, and frozen-model friendly.
There is no fine-tuning, no backbone swap, and no context extension.
δ-mem augments a frozen full-attention model with a compact online associative-memory state. The state is a fixed-size matrix updated by delta-rule learning, and its readout produces low-rank corrections to the backbone's attention during generation.
Results:
An 8×8 online memory state is enough to lift the frozen backbone's average score by 1.10x and beat the strongest non-δ-mem memory baseline by 1.15x. On memory-heavy benchmarks the gap widens (1.31x on MemoryAgentBench, 1.20x on LoCoMo) while general capabilities are largely preserved.
Paper: https://t.co/peVmZ9reue
Learn to build effective AI agents in our academy: https://t.co/LRnpZN7L4c
Must-read research of the week
▪️ Generate, Filter, Control, Replay: A comprehensive survey of rollout strategies for LLM reinforcement learning
▪️ Hallucinations Undermine Trust; Metacognition is a way forward
▪️ ARIS: Autonomous Research via Adversarial Multi-Agent Collaboration
▪️ MolmoAct2: Action Reasoning Models for Real-world Deployment
▪️ Can RL Teach Long-Horizon Reasoning to LLMs? Expressiveness Is Key
▪️ Nonsense Helps: Prompt Space Perturbation Broadens Reasoning Exploration
▪️ Stream-T1: Test-Time Scaling for Streaming Video Generation
▪️ HERMES++: Toward a Unified Driving World Model for 3D Scene Understanding and Generation
▪️ MiA-Signature: Approximating Global Activation for Long-Context Understanding
▪️ Rethinking Reasoning-Intensive Retrieval: Evaluating and Advancing Retrievers in Agentic Search Systems
▪️ Continuous Latent Diffusion Language Model
▪️ Prescriptive Scaling Laws for Data Constrained Training
Find the full list and the most interesting AI news of the week here: https://t.co/gt98mzvLGR
“Attention Drift: What Autoregressive Speculative Decoding Models Learn”
Speculative decoding makes LLM inference faster, but drafters break under small template changes and long context. But why?
This paper shows that as the drafter predicts more tokens, its attention drifts away from the prompt and onto its own recent guesses.
The key fix is to normalize the drafter’s hidden states so they stay stable across draft steps.
With post-norm and RMSNorm fusion, the paper gets up to 2x better acceptance under template perturbations and stronger long-context robustness.
We introduce Sparse Autoencoder Neural Operators (SAE-NOs), a functional framework for representation learning and mechanistic interpretability that treats data as samples from underlying continuous functions and learns mappings between function spaces.
Standard SAEs (SAE-MLP) represent each concept with a scalar activation and a vector-valued dictionary atom, limiting their ability to capture how and where a concept is expressed across structured domains.
SAE-FNO introduces feature-map representations with both concept sparsity and domain sparsity, allowing the model to capture not only which concepts are active, but also where and how they are expressed across the domain.
This is a joint collaboration, between @UAlberta/@AmiiThinks and @Caltech, with Ailsa Shen and @AnimaAnandkumar. 1/
arXiv: https://t.co/EphbL2FJYA
Introducing Flux Matching, a generative modeling paradigm that generalizes diffusion models to vector fields that need not be the score function.
Enables structural priors in the dynamics, faster sampling, interpretable generation, and more!
w/ @StefanoErmon@Xiaojie_Qiu 🧵⤵️
Interesting paper. What I like about this is that it is a relatively low-commitment attention modification.
I.e., one can use it during most of training, switch back to vanilla attention near the end, and recover roughly the same modeling performance as if full attention had been used the whole time.
Andrej Karpathy: "90% of your AI coding bill is paying for context you didn't need to send"
Here are 10 things senior AI engineers stopped wasting tokens on:
1. Auto-context loading 50 files for a 30-line fix: $1.20/turn for tokens you'll never read. 80% input waste, every session
2. Running Opus on lint, format, and rename tasks: $0.60 for what Haiku nails at $0.02. 30x overpay on the cleanup tier
3. Tool call loops that re-send the full repo on every retry: 5x context cost per agentic flow. fixing these alone cuts 30-50% of bills
4. Sonnet as the default model: Kimi 2.6 matches its quality on most coding tasks at 1/6 the cost. defaulting to Sonnet in 2026 is leaving 60-70% on the table
5. Streaming responses on stable-prefix workflows: kills your prompt cache. you pay 10x for tokens that should have cost cents
6. "Just in case" file includes: 80,000-token prompts that should be 3,000. context bloat is the silent budget killer
7. Per-session knowledge rebuilding: 10 min writing a SKILL.md once vs paying agents to re-figure out your environment every run. $4 vs $0.30 per execution
8. Single-model setups: premium tier on every task is the most expensive mistake in AI coding right now
9. Asking 10 small questions one at a time: 10 separate input prefix charges vs one batched call. 70-90% savings on routine workflows
10. Buying Claude Pro + ChatGPT Plus + Cursor Pro: you seriously use one. the other two are habit, not utility
what actually compounds instead:
- context discipline (grep before fetching, always)
- prompt caching on every stable prefix
- multi-model routing (Kimi 2.6 default, Opus for the 10%)
- graduated skills via SKILL.md files
- profiling tool calls before optimizing prompts
- the routing mindset (right model for right task)
in 12 months, the gap between developers shipping on $200/month and $4,000/month budgets won't be skill
it'll be how well they route
study this.