Meet DiffusionGemma!
An experimental open model that explores a fast approach to text generation, released under an Apache 2.0 license.
Moving beyond sequential, token-by-token processes to generate entire blocks of text simultaneously. Here’s what’s new with DiffusionGemma: 👇
Introducing DiffusionBlocks: Block-wise Neural Network Training via Diffusion Interpretation
https://t.co/c9AvsRKybj
What if we didn’t have to hold an entire neural network in memory to train it?
Standard neural net training optimizes all parameters jointly. As a result, the memory required during training grows linearly with the depth of the network.
In our #ICLR2026 paper, we propose DiffusionBlocks, a principled framework to train networks one block at a time, drastically reducing memory requirements while matching end-to-end performance.
With DiffusionBlocks, we split the network into blocks and train them one at a time, so you only need memory for a single block.
How? We explicitly assign each block a role: to move the representation a little closer to the target than the block before it did. That role turns out to be precisely what a diffusion model does, step by step. Each block only needs to optimize its own objective and can be trained independently.
We validated this across five different architectures:
• ViT
• DiT
• Masked diffusion
• Autoregressive transformers
• Recurrent-depth transformers
In each case, performance is competitive with end-to-end training while using a fraction of the memory.
This perspective also extends naturally to recurrent-depth (Looped) transformers, which apply the same network iteratively and normally require expensive backpropagation through time (BPTT). Viewed through DiffusionBlocks, we can replace those multiple iterations with a single forward pass during training.
Read our paper and code, to learn more.
Paper: https://t.co/CRj96VGYQn
GitHub: https://t.co/eNW0K9Xh8E
🐟
New blackboard lecture w @reinerpope
How do chips actually work – starting with basic logic gates, and working up to why GPUs, TPUs, FPGAs, and the human brain each look the way they do.
0:00:00 – Building a multiply-accumulate from logic gates
0:16:20 – Muxes and the cost of data movement
0:25:59 – How systolic arrays work
0:39:00 – Clock cycles and pipeline registers
0:51:40 – FPGAs vs ASICs
1:03:14 – Cache vs scratchpad
1:07:16 – Why CPU cores are much bigger than GPU cores
1:11:49 – Brains vs chips
1:15:22 – A GPU is just a bunch of tiny TPUs
Look up Dwarkesh Podcast on YouTube/Spotify/etc to watch. Enjoy!
Today, we share a breakthrough on the planar unit distance problem, a famous open question first posed by Paul Erdős in 1946.
For nearly 80 years, mathematicians believed the best possible solutions looked roughly like square grids.
An OpenAI model has now disproved that belief, discovering an entirely new family of constructions that performs better.
This marks the first time AI has autonomously solved a prominent open problem central to a field of mathematics.
Introducing HRM-Text.
An ultra-lean 1B-parameter reasoning language model designed to deliver strong general performance with a fraction of the data, compute, and infrastructure.
Trained on just 40B structured tokens, HRM-Text achieves competitive performance while using ~1/1000 of the training data of comparable models.
The kicker? The full model trains in roughly one day on a $1,000 budget.
This opens the door to a new generation of AI that is powerful, accessible, and radically easier to adapt. Theories and research concepts once deemed too expensive to test are officially back in the game.
Sapient Intelligence invites you to help us shape a new paradigm for general intelligence.
New blackboard lecture w @ericjang11
He walks through how to build AlphaGo from scratch, but with modern AI tools.
Sometimes you understand the future better by stepping backward. AlphaGo is still the cleanest worked example of the primitives of intelligence: search, learning from experience, and self-play. You have to go back to 2017 to get insight into how the more general AIs of the future might learn.
Once he explained how AlphaGo works, it gave us the context to have a discussion about how RL works in LLMs and how it could work better – naive policy gradient RL has to figure out which of the 100k+ tokens in your trajectory actually got you the right answer, while AlphaGo’s MCTS suggests a strictly better action every single move, giving you a training target that sidesteps the credit assignment problem. The way humans learn is surely closer to the second.
Eric also kickstarted an Autoresearch loop on his project. And it was very interesting to discuss which parts of AI research LLMs can already automate pretty well (implementing and running experiments, optimizing hyperparameters) and which they still struggle with (choosing the right question to investigate next, escaping research dead ends). Informative to all the recent discussion about when we should expect an intelligence explosion, and what it would look like from the inside.
Timestamps:
0:00:00 – Basics of Go
0:08:06 – Monte Carlo Tree Search
0:31:53 – What the neural network does
1:00:22 – Self-play
1:25:27 – Alternative RL approaches
1:45:36 – Why doesn’t MCTS work for LLMs
2:00:58 – Off-policy training
2:11:51 – RL is even more information inefficient than you thought
2:22:05 – Automated AI researchers
“Attention Drift: What Autoregressive Speculative Decoding Models Learn”
Speculative decoding makes LLM inference faster, but drafters break under small template changes and long context. But why?
This paper shows that as the drafter predicts more tokens, its attention drifts away from the prompt and onto its own recent guesses.
The key fix is to normalize the drafter’s hidden states so they stay stable across draft steps.
With post-norm and RMSNorm fusion, the paper gets up to 2x better acceptance under template perturbations and stronger long-context robustness.
Pretraining data curation alone — no SFT, no RL — within 1.8pp of Qwen3-VL-2B at ~87× less train compute. New VLM research from our team. https://t.co/zGLEjLspN9
How do we make LLMs faster and lighter? Don’t force the GPU to adapt to sparsity. Reshape the sparsity to fit the GPU! ⚡️
Excited to share our new #ICML2026 paper in collaboration with @NVIDIA: "Sparser, Faster, Lighter Transformer Language Models". This work introduces new open-source GPU kernels and data formats for faster inference and training of sparse transformer language models:
Paper: https://t.co/3Avj8N8iYO
Blog: https://t.co/SqFkkKvkbd
Code: https://t.co/PHSzMq8pg0
While LLMs are undoubtedly powerful, they are increasingly expensive to train and deploy, with a large part of this cost coming from their feedforward layers. Yet, an interesting phenomenon occurs inside these layers: For any given token, only a small fraction of the hidden activations actually matter. The rest approximate zero, wasting computation. With ReLU and very mild L1 regularization, this sparsity can exceed 95% with little to no impact on downstream performance.
So, can we leverage this sparsity to make LLMs faster? The challenge is hardware. Modern GPUs are optimized for dense matrix multiplications. Traditional sparse formats introduce irregular memory access and overheads that cancel out their theoretical savings for GEMM operations.
Our contribution is twofold:
1/ We introduce TwELL (Tile-wise ELLPACK), a new sparse packing format designed to integrate directly in the same optimized tiled matmul kernels without disrupting execution.
2/ We develop custom CUDA kernels that fuse multiple sparse matmuls to maximize throughput and compress TwELL to a hybrid representation that minimizes activation sizes.
We used our kernels to train and benchmark sparse LLMs at billion-parameter scales, demonstrating >20% speedups and even higher savings in peak memory and energy.
This work will be presented at #ICML2026. Please check out our blog and technical paper for a deep dive!
(1/5) Great to be at @sequoia to give a sneak peek of one of our research directions!
TL;DR one path to data-efficiency may be to “abuse GPUs like they’ve never been abused before”
Breaking LLM inference’s autoregressive bottleneck 🛠️
We've teamed up with @haozhangml, @YimingBob, and @aaronzhfeng, among others from UCSD to achieve a massive 3.13X speedup for LLM inference on Google Cloud TPUs using Diffusion-Style Speculative Decoding (DFlash).
Read the blog: https://t.co/bIugAUJm8S
1. I never said LLMs were not useful. They are, particularly with all the bells and whistles that are being added to them. I use them.
2. A robot-rich future can't be built with AIs that don't understand the physical world and don't anticipate the consequences of their actions. And LLMs really don't.
3. The future in the cartoon looks pretty dystopian TBH, but even a non-dystopian version will require world models and zero-shot planning abilities.
4. I rarely wear a suit and absolutely never wear a tie.
5. I would never ever place a coffee mug on top of a piece equipment.
6. I hope I'll look this young in 2032.
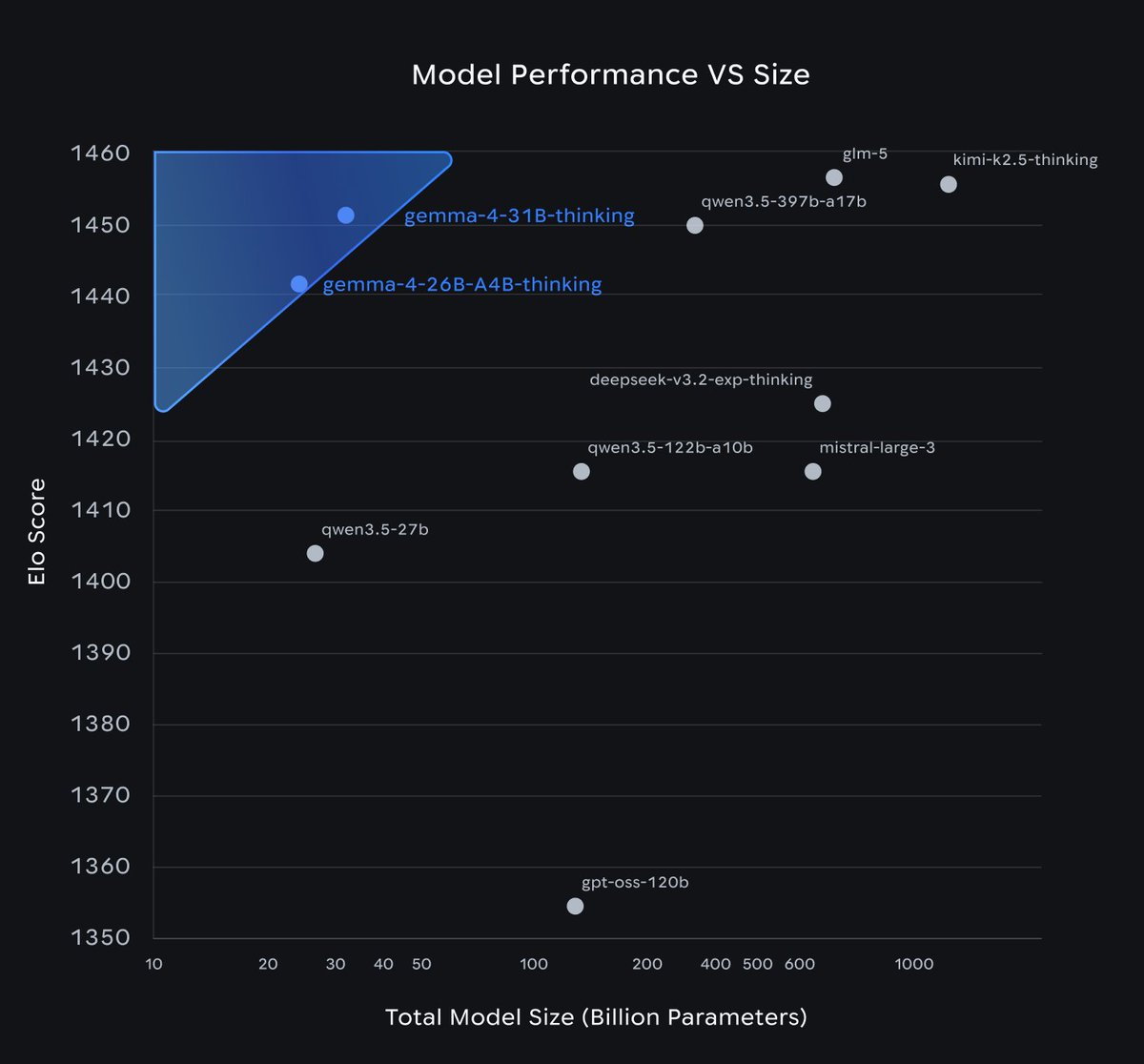
Meet Gemma 4!
Purpose-built for advanced reasoning and agentic workflows on the hardware you own, and released under an Apache 2.0 license.
We listened to invaluable community feedback in developing these models. Here is what makes Gemma 4 our most capable open models yet: 👇
Introducing TurboQuant: Our new compression algorithm that reduces LLM key-value cache memory by at least 6x and delivers up to 8x speedup, all with zero accuracy loss, redefining AI efficiency. Read the blog to learn how it achieves these results: https://t.co/CDSQ8HpZoc
JEPA are finally easy to train end-to-end without any tricks!
Excited to introduce LeWorldModel: a stable, end-to-end JEPA that learns world models directly from pixels, no heuristics.
15M params, 1 GPU, and full planning <1 second.
📑: https://t.co/cpTzgvbTS0