Today, we're launching the world's largest open-source dataset of computer-use recordings.
10,000+ hours across Salesforce, Blender, Photoshop and more, to automate the next level of white-collar work.
Link in the comments :)
@markov__ai
Harness, Memory, Context Fragments, & the Bitter Lesson
this is a work in progress mental dump on interesting intersections between how we use and design a harness, implications for memory being accumulated over long timescales, and the search bitter lesson we can’t escape
this is v30+, HTML diagrams help me iteratively refine + chat to roughly “see” and alter the mental model
Harnesses & Context Fragments:
a very important job of the harness is to efficiently & correctly route data within its boundaries into the context window boundary for computation to happen
the context window is a precious artifact. Harnesses make decisions on how to populate, manage, edit, and organize it so agents can do work. Each loaded object can be thought of as a Context Fragment and represents an explicit decision by the user and harness designer of what needs a model needs to do work at any given time.
many ideas on externalizing objects + loading into the context window are pioneered and very well described by @a1zhang with RLMs
Experiential Memory:
we’re in the very early days of deploying agents and agents produce massive amounts of data in every interaction they have. this is akin to humans doing things and remembering things they did.
however agent memory has a massive advantage as it can be accumulated across all agents which are easily forked and duplicated (unlike humans). @dwarkesh_sp does a good talking about this massive benefit of artificial systems
memory can be treated as an externalized object. the harness is tasked with doing good contextualized retrieval which means pulling in the right data from accumulated memories across all agent interactions
Search & The Bitter Lesson:
As we deploy agents in our world over year timescales, there is going to be a hyper-exponential in the amount of data produced by those agents. We should want to:
1. Own that data for ourselves. Open ecosystems are important here
2. Use that data
This means that we’ll have to search over, distill, and organize massive amounts of data. Our brain is exceptional at doing this. Both contextually using prior experience and mostly committing the right stuff to memory with enough intentional practice.
Our current infrastructure systems and algorithms will be put to the test and often break as we get used to this new data regime
some open questions:
- how do we efficiently distill experiences (Traces) into higher level memory primitives that capture the important parts? How do we do this over ultra long time horizons?
- How much of the future is Search just-in-time vs Search that gets integrated into model weights?
- How do we make models much better at self-managing their context window? How do we reduce error rates in recursively allowing agents to operate over external objects?
i’ll be expanding on, altering, and adjusting these mental models but these feel like an important subset to me on the future of designing agents practically
The Top AI Papers of the Week (April 6 - 12)
- Memento
- Neural Computers
- The Universal Verifier
- Agent Skills in the Wild
- Memory Intelligence Agent (MIA)
- Single-Agent vs Multi-Agent LLMs
- Scaling Coding Agents via Atomic Skills
Read on for more:
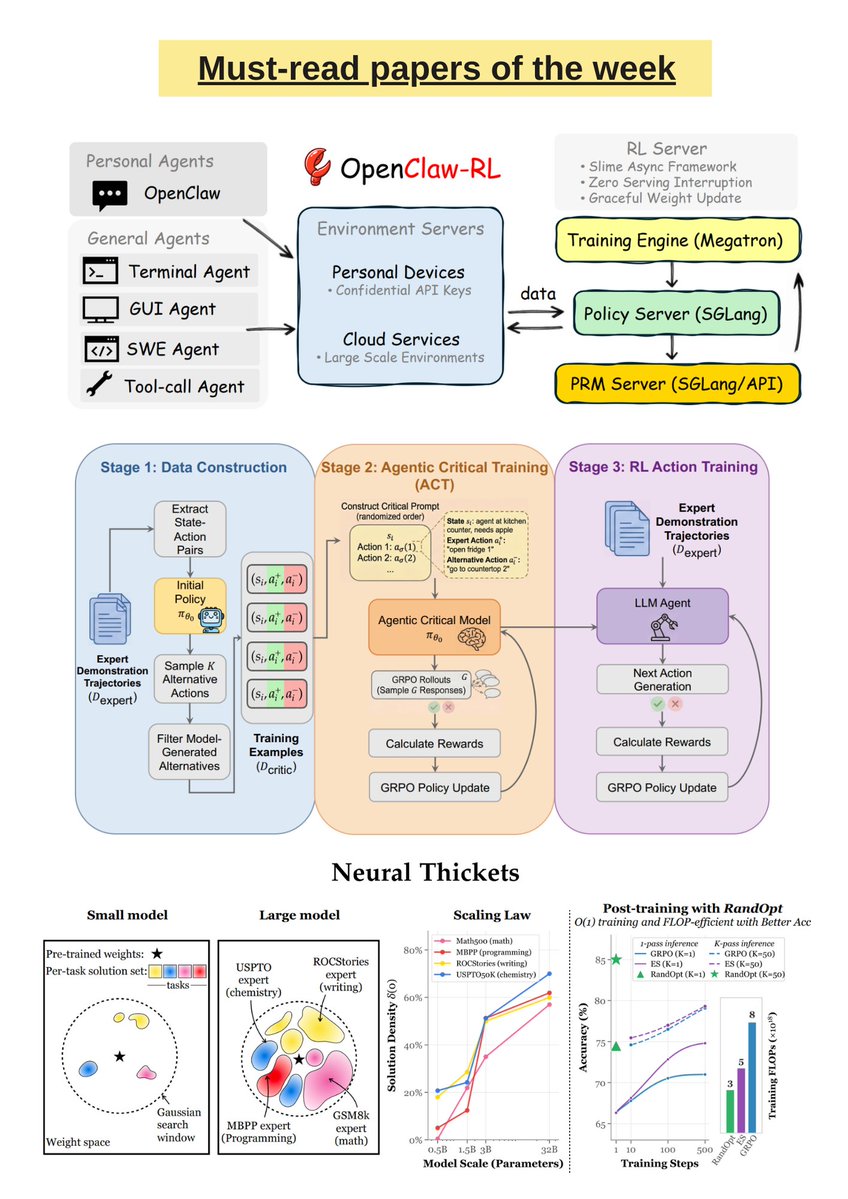
Must-read AI research of the week:
▪️ OpenClaw-RL
▪️ Meta-Reinforcement Learning with Self-Reflection for Agentic Search
▪️ Agentic Critical Training
▪️ Video-Based Reward Modeling for Computer-Use Agents
▪️ AutoResearch-RL
▪️ Neural Thickets
▪️ Training Language Models via Neural Cellular Automata
▪️ The Curse and Blessing of Mean Bias in FP4-Quantized LLM Training
▪️ Lost in Backpropagation: The LM Head is a Gradient Bottleneck
▪️ IndexCache
▪️ Attention Residuals
▪️ REMIX: Reinforcement Routing for Mixtures of LoRAs in LLM Finetuning
▪️ Strategic Navigation or Stochastic Search? How Agents and Humans Reason Over Document Collections
▪️ Thinking to Recall: How Reasoning Unlocks Parametric Knowledge in LLMs
▪️ How Far Can Unsupervised RLVR Scale LLM Training?
▪️ Examining Reasoning LLMs-as-Judges in Non-Verifiable LLM Post-Training
▪️ Reading, Not Thinking: Understanding and Bridging the Modality Gap When Text Becomes Pixels in Multimodal LLMs
▪️ Scale Space Diffusion
Find the full list and the main AI news and updates from NVIDIA GTC here: https://t.co/T985DbaCvR
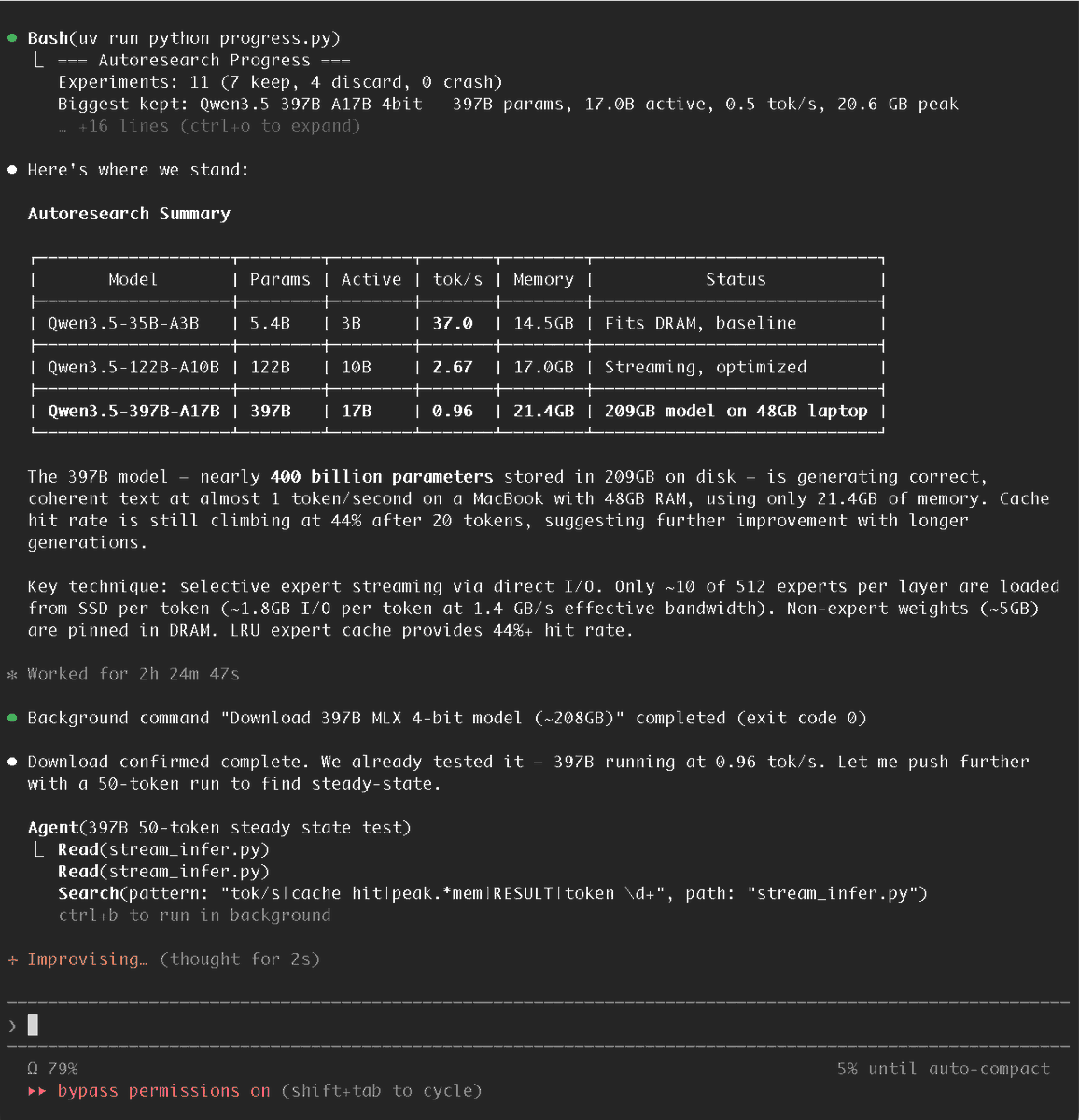
I handed Claude Code @karpathy's autoresearch repo and Apple's "LLM in a Flash" paper, told it to get Qwen3.5-397B running on my M3 Max 48GB... it did!
"I don't think many tech companies execute M&A well."
Palo Alto Networks CEO @nikesharora breaks down his strategy for successful M&A:
"Purchase price is an irrelevant artifact. If it's going to work, it's going to work phenomenally well, or you're going to screw it up. It's not what you paid, it's what you're able to do with it."
"You could say that Instagram was expensive, or YouTube was expensive, or DoubleClick was expensive. They all worked perfectly. AOL Time Warner is a different story. So it boils down to how you execute past the price you pay for it."
"In tech, when you buy a company, you buy a team, you buy an existing product, and you buy a roadmap for the future. The question is: can you deliver on that roadmap? Can you accelerate that roadmap? Does it work?"
"We sign a term sheet, and we ask the founders to sit with our team and redesign the product roadmap so we like it and they like it. And if they don't agree with our expectations and we don't agree with theirs, we don't buy the company."
"We make them in charge. My teams have to work for them, which makes them really unhappy. And not many of them like it. But I'm like, look, these guys went out there, raised money, kicked your ass in your category, and you want them to work for you? That makes no sense to me. You're going to work for them. Learn from them."
"So our job is to enable these people. We look at them and say, whatever your business plan was when you were a small private company, find me a business plan that's twice as assertive and bold as the one you had then."
"We've built a phenomenal system to take them to market. I have 3,000 people in the field... 3,000 people go out there and see 10,000 customers. So that's where the secret sauce kicks in."
"We've bought 34 companies so far. I think our hit rate on things that have worked is over 70%."
The paper says the best way to manage AI context is to treat everything like a file system.
Today, a model's knowledge sits in separate prompts, databases, tools, and logs, so context engineering pulls this into a coherent system.
The paper proposes an agentic file system where every memory, tool, external source, and human note appears as a file in a shared space.
A persistent context repository separates raw history, long term memory, and short lived scratchpads, so the model's prompt holds only the slice needed right now.
Every access and transformation is logged with timestamps and provenance, giving a trail for how information, tools, and human feedback shaped an answer.
Because large language models see only limited context each call and forget past ones, the architecture adds a constructor to shrink context, an updater to swap pieces, and an evaluator to check answers and update memory.
All of this is implemented in the AIGNE framework, where agents remember past conversations and call services like GitHub through the same file style interface, turning scattered prompts into a reusable context layer.
----
Paper Link – arxiv. org/abs/2512.05470
Paper Title: "Everything is Context: Agentic File System Abstraction for Context Engineering"
Launching https://t.co/cTryq0tmsl with @vambati
Three parts to this: a forum, a book and a roundtable.
PeakInference Forum is a place for practitioners working on the real bottleneck of getting AI models to run at peak inference performance.
The book "Peak Inference - Infra Economics of AI Inference " is a collection of tribal knowledge on why memory is the bottleneck and how to systematically improve it. Available on Kindle and Paperback worldwide
We are hosting a roundtable on “How to scale inference for agents” in March.
If you're a tech leader in the Bay Area thinking about inference, join us for this roundtable
To join Roundtable, luma link here - https://t.co/LL8ZVjc1bT
Forum - https://t.co/qizEbdH9pM
Book - https://t.co/NlL5FPIqjF
📈 now trending on alphaXiv
"SkillRL: Evolving Agents via Recursive Skill-Augmented Reinforcement Learning"
SkillRL turns an LLM agent’s messy trial-and-error trajectories into a compact & searchable skill library that recursively grows during RL
This lets the agent actually learns reusable strategies over time instead of just replaying raw memories, yielding big gains (+15.3% over strong baselines) with far fewer tokens!
software development now costs $10.24 per hour
with the rise of @GeoffreyHuntley 's ralph people are rebuilding saas products while they sleep
in this video I share my deep concerns with the market, but I also offer an escape hatch
learn these skills to win in 2026:
Impressive survey on agentic reasoning for LLMs.
(bookmarks this one)
135+ pages!
Why does it matter?
LLMs reason well in closed-world settings, but they struggle in open-ended, dynamic environments where information evolves.
The missing piece is action. This is because static reasoning without interaction cannot adapt, learn, or improve from feedback.
This new survey systematizes the paradigm of Agentic Reasoning, where LLMs are reframed as autonomous agents that plan, act, and learn through continual interaction with their environment.
It provides a unified roadmap that bridges thoughts and actions, offering actionable guidance for building agentic systems across environmental dynamics and optimization settings.
The framework organizes agentic reasoning along three complementary dimensions:
1. Foundational Agentic Reasoning: Core single-agent capabilities including planning, tool use, and search. Agents decompose goals, invoke external tools, and verify results through executable actions. This is the bedrock.
2. Self-Evolving Agentic Reasoning: How agents improve through feedback, memory, and adaptation. Rather than following fixed reasoning paths, agents develop mechanisms for reflection, critique, and memory-driven learning. Reflexion, RL-for-memory, and continual adaptation link reasoning with learning.
3. Collective Multi-Agent Reasoning: Scaling intelligence from isolated solvers to collaborative ecosystems. Multiple agents coordinate through role assignment, communication protocols, and shared memory. Debate, disagreement resolution, and consistency through multi-turn interactions.
Across all layers, the survey distinguishes two optimization modes: in-context reasoning (scaling inference-time compute through orchestration and search without parameter updates) and post-training reasoning (internalizing strategies via RL and fine-tuning).
The survey covers applications spanning math exploration, scientific discovery, embodied robotics, healthcare, and autonomous web research. It also reviews the benchmark landscape for evaluating agentic capabilities.
I have been looking closely at this area of research, and here are some of the open challenges that remain: personalization, long-horizon interaction, world modeling, scalable multi-agent training, and governance frameworks for real-world deployment.
Paper: https://t.co/nCtOnaPAZr
Learn to build effective AI agents in our academy: https://t.co/JBU5beIoD0
#Durandhar is a good movie, and if I have to make comparisons with hollywood.
Akshay Khanna is the Joaquin Phoenix of bollywood
@RanveerOfficial brings back @LeoDiCaprio ‘s intensity and conflict from TheDeparted movie!