⭐Soo happy to share that I'll be joining @NYUDataScience as a PhD student this Fall!
Excited to learn from and work with @eunsolc, @hhexiy, and the amazing folks at @CILVRatNYU. Looking forward to better understanding and improving large ML models.
12/ We just think the evidence so far doesn't quite support a strong interpretation of the introspection findings in previous work. And, as always, extraordinary claims require extraordinary evidence. Paper: https://t.co/oHhjysLCJl
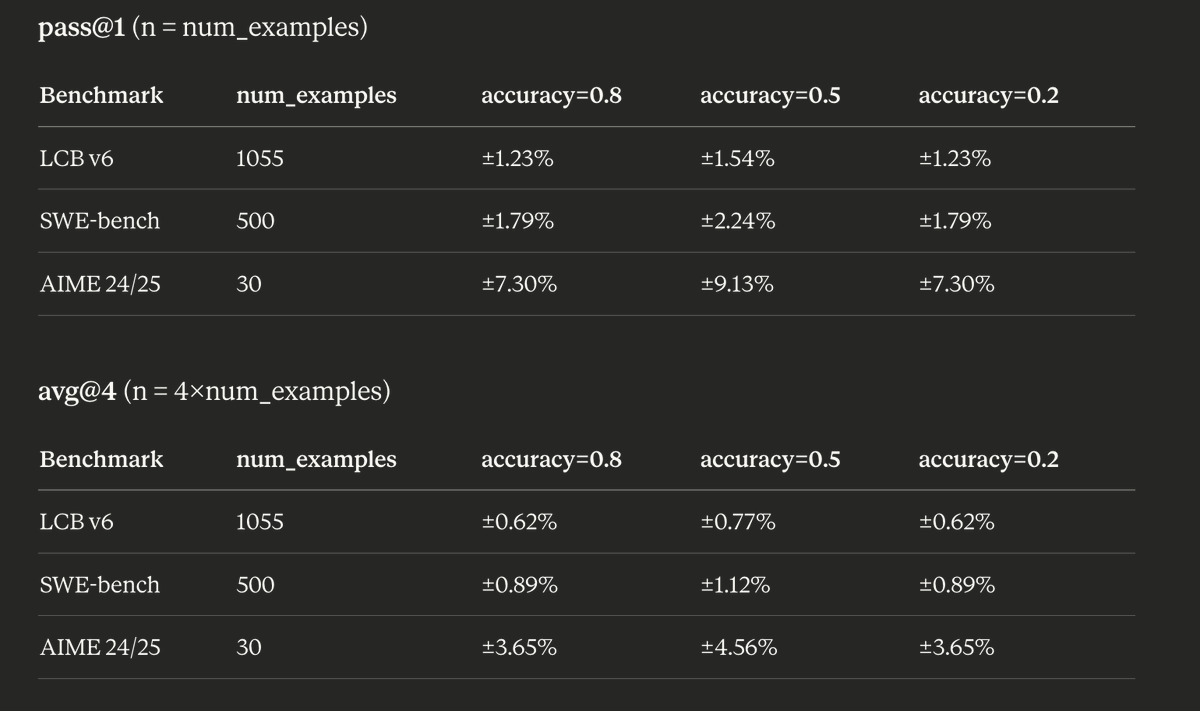
Pulled out some high school statistics to find that many of the benchmark / loss improvements in papers seem to be just noise.
For example, AIME 24/25 each has 30 problems. So if an RL method scores 50% on avg@4, the variance is 0.5 * (1-0.5), and it will be scaled down by 4 * 30. That gives a standard error of ~4.56%, meaning that unless the method improves by the baseline by that much, it could very well by chance.
Similarly, other reasoning benchmarks such as LCB v6 and SWE-bench for coding only have 1055 and 500 problems. That puts the standard error of avg@4 to be around 1%. This is modest, but in reality we see a lot of paper claiming some 1% advantage on these!
But all of the above assumes a paper reports avg@4. Many actually report pass@1. Pass@1 means less trials, so the variance is not narrowed down as much. So on AIME, that will mean an improvement smaller than 9.13% is noise.
For a lot of the pretraining benchmarks, the situation is better because we have more examples to check. For example, HellaSwag has 10K examples, so even with pass@1 reported the standard error is within 0.5%. Other benchmarks have a similar range within 1%.
Finally, the training curves have a similar issue. All training curves are run once, and there is no error bar whatsoever. That could very well just be the random seed in many cases. But this is a more acknowledged problem and mostly because running training is expensive. The excuses for benchmarking seems not as many.
Hi I along with @pranamyapk will be presenting our work on ROPES: Robotic Pose Estimation via Score-Based Causal Representation Learning (https://t.co/UNHr1mbx4S) at Embodied World Models for Decision Making Workshop #NeurIPS
📍Upper Level Room 30A-E
⏲️ Dec 6
my greatest hack to learn faster is tactical naps
I blitz-learn a topic until my head can’t do it no more
then I take a nap wherever and repeat the process
I used to sleep in my college library like I lived there
> Get a research idea
> Realize you need to finetune a model
> No resources available
> Prompt chatgpt to mimic your "imaginary model"
> It doesn't mimic well
> Have a melt down and scold it
> Apologize
⭐Soo happy to share that I'll be joining @NYUDataScience as a PhD student this Fall!
Excited to learn from and work with @eunsolc, @hhexiy, and the amazing folks at @CILVRatNYU. Looking forward to better understanding and improving large ML models.
⭐Soo happy to share that I'll be joining @NYUDataScience as a PhD student this Fall!
Excited to learn from and work with @eunsolc, @hhexiy, and the amazing folks at @CILVRatNYU. Looking forward to better understanding and improving large ML models.
This wouldn't have been possible without the guidance and support from an incredible set of mentors and role models: Karthikeyan Shanmugam, @PNetrapalli , @jainprateek_ , Arun Suggala, @Sravanti_A , et al.🙏
🚨Come check out our poster at #ICML2025!
QuantSpec: Self-Speculative Decoding with Hierarchical Quantized KV Cache
📍 East Exhibition Hall A-B — #E-2608
🗓️ Poster Session 5 | Thu, Jul 17 | 🕓 11:00 AM –1:30 PM
TLDR:
Use a quantized version of the same model as its own draft for speculative decoding. It’s fast, memory-efficient, and works great for long context—no extra draft model needed. 2.5× End-to-End generation speedup is achieved. 🔥
🔗 https://t.co/FzyxwJrNbB