this is why the labs are pushing visions of mass unemployment and replacing the white-collar workforce
it's not because the models can do it
it's because they have to in order to make their economic model work and to keep raising money
the only way to keep raising hundreds of billions of dollars is to sell everyone on the idea you're going to demolish a massive chunk of the labor market
otherwise it doesn't work
OpenAI attempting to get Federal backstops because the entire system is run by psychopaths who think we are all retards and won't raise a ruckus.
https://t.co/zMdk331be4
Only in an America can an industry that has collectively lost over half a trillion dollars —at a pace of roughly a million dollars a minute — ask for (and likely get) government subsidies.
Big Tech just ran out of money building AI and what they're doing to cover it up should be illegal.
Google, Amazon, Microsoft, and Meta are spending a combined $700 BILLION this year on AI infrastructure.
This eats up 94% of their total operating cash flow.
The richest companies in human history are almost broke. And instead of slowing down, they're covering it up with the biggest financial engineering operation since 2008:
Google just sold $80 billion in stock to fund AI infrastructure. That was their first equity raise in 20 YEARS.
The last time Google needed to sell stock, YouTube didn't even exist. Sundar Pichai admitted the thing keeping him up at night is "compute capacity."
The company that prints $100 billion a year in ad revenue just told Wall Street it isn't enough anymore.
Amazon's free cash flow is projected to go NEGATIVE this year for the first time ever. Morgan Stanley estimates a $17 billion deficit and Bank of America says $28 billion.
The most profitable logistics machine on Earth is about to burn more cash than it generates, and they quietly filed with the SEC saying they may need to raise even more debt and equity to keep building.
All four hyperscalers are now borrowing hundreds of billions in bonds to keep the AI buildout alive. These were the most cash-rich companies in human history, and they're leveraging themselves to the teeth to build infrastructure that nobody has proven will generate enough revenue to pay for itself.
And the cracks are already starting to show:
Broadcom makes the custom AI chips that power Google, Meta, OpenAI, and Anthropic. This week their AI revenue TRIPLED year over year, sales grew 48%, and profits smashed every Wall Street estimate.
The reward for all of that was $320 billion in value erased in a single trading session.
Their CEO Hock Tan went on the earnings call and exposed three things about the AI industry:
Google is already shopping for cheaper AI chip alternatives, broadcom abandoned its strategy of selling complete AI systems and is now retreating to selling bare chips at lower margins.
And despite supposedly "unprecedented demand," Tan refused to raise his full-year forecast, which tells you everything about what he's actually seeing behind the curtain.
Wall Street heard all three and hit the sell button so hard it dragged AMD, Intel, and the entire chip sector down with it.
When a company triples its AI revenue and gets punished because tripling isn't fast enough, the expectations have left the atmosphere entirely.
And here's the really scary part...
These companies ARE your retirement account. Apple, Microsoft, Amazon, Google, Meta, and Nvidia make up roughly 30% of the S&P 500. If you have a 401k or an index fund, you are already exposed to this bet whether you chose to be or not.
Every single one of these companies is telling you AI will generate trillions in revenue. But right now the math says they're spending trillions FIRST and hoping the revenue shows up later.
If the revenue catches up, this becomes the greatest infrastructure buildout in human history. Bigger than railroads and bigger than the internet.
If it doesn't, the companies that make up a third of the American stock market just leveraged their balance sheets into the largest write-down cycle since 2000.
And unlike the dot-com crash, this time the bubble companies aren't random startups with no revenue. They're the backbone of the entire global economy.
Anthropic’s new chemistry report has a genuinely wild result.
Claude Opus 4.7 is now competitive with dedicated NMR software, and the bigger story is that it can work the problem backwards, i.e. infer the molecule from the spectrum.”
NMR software is the chemist’s expert tool for turning molecular structures into predicted lab spectra.
So Opus 4.7 is no longer just “helping chemists read data” — it can work backward from NMR data and propose the molecule’s structure, a task the report says existing mainstream tools generally leave to human chemists.
Note, that Opus 4.7, a general-purpose model with no chemistry-specific fine-tuning.
Claude Opus 4.7 made the smallest hydrogen prediction errors and nearly matched MestReNova on carbon, meaning it can predict NMR signals about as well as specialist chemistry tools.
So AI now handle one of chemistry’s hidden bottlenecks: translating between a molecule, its spectral shadow, and the structure a chemist actually needs to trust.
Everything You Need To Know About
Inference Engines and Running LLMs Locally at Home
Explains why Inference Engines exist in the first place
- Prefill is not Decode
- VRAM is not bandwidth
- Fit is not speed
- KV Cache is the real memory problem
- Quantization only matters if the engine has good kernels for it
- Batching is not scheduling
- MoE and the routing problem
- How long context changes the serving problem
- Multi-GPU changes the interconnect problem
- Production: latency, p99s, backpressure, routing, metrics, and failure behavior
Then maps the Engines including:
- llama.cpp → portability king
- MLX / MLX-LM → Apple Silicon weapon
- ExLlamaV3 → multi-GPU consumer CUDA / local MoE
- vLLM → default open-source production server
- SGLang → long-context, MoE, routing, ugly workloads
- TensorRT-LLM → max NVIDIA performance
- NVIDIA Dynamo → fleet orchestration
The point of this article is not “use vLLM” or “use TensorRT-LLM” or “use llama.cpp”
But rather fully grasp how the Inference Engines are the traffic cop, memory manager, kernel dispatcher, scheduler, cache accountant, parallelism planner, API surface, and sometimes the deployment framework
Do not pick the engine first
- Pick the hardware
- Pick the workload
- Pick the serving model
Then the engine becomes obvious
Opensource / Local AI FTW
Also the Pope is talking about Epistemia. AI can “weaken personal judgment.”
This is exactly the point we make in our paper on the epistemological fault lines between human and artificial intelligence.
LLMs and humans do not merely differ in performance.
They differ in their epistemic pipelines.
We identify seven fault lines:
Grounding.
Parsing.
Experience.
Motivation.
Causality.
Metacognition.
Value.
At each step, human intelligence and artificial intelligence process the world in structurally different ways.
And yet, LLM outputs are so fluent and confident that we often treat them as true.
This is how we enter Epistemia: a regime in which epistemic verification is replaced by linguistic plausibility.
A world full of knowledge that we are not able to judge.
A world in which we will be totally lost.
*
Full paper in the first reply.
🚨 THE ENTIRE AI BOOM MIGHT BE BUILT ON FAKE REVENUE.
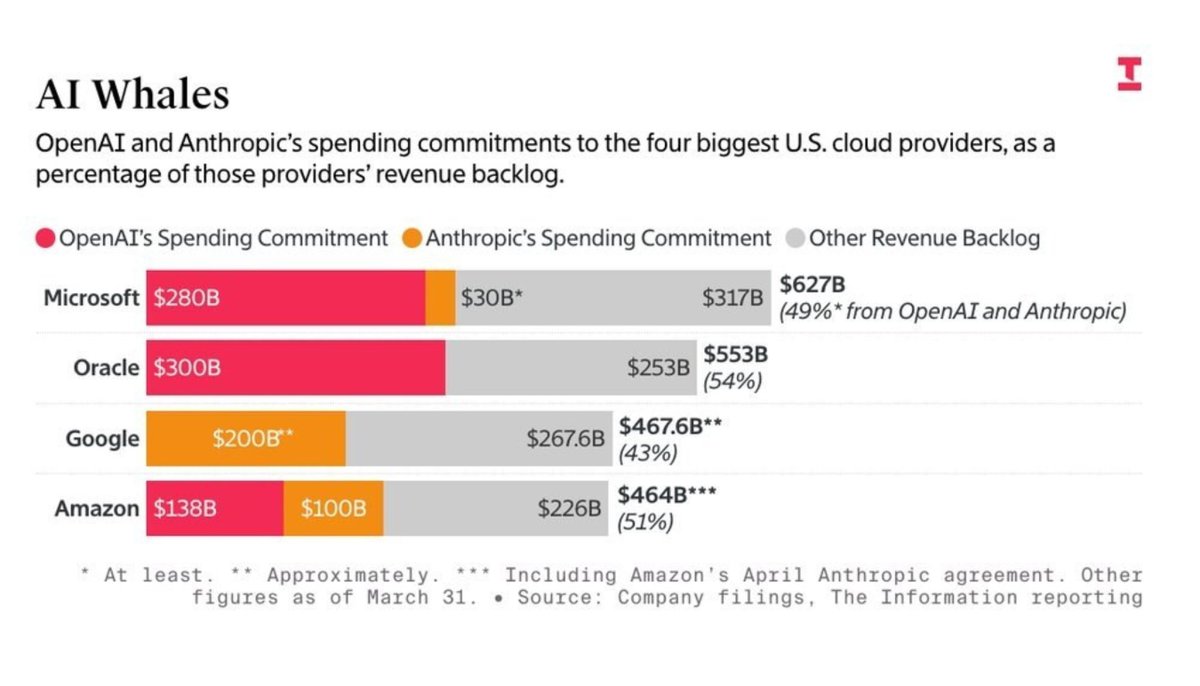
Latest corporate filings show that OpenAI and Anthropic alone make up over half of the entire $2 trillion future cloud backlog held by Microsoft, Oracle, Google, and Amazon.
This massive pipeline is actually being created through a circular accounting trick called a round trip revenue loop.
But how it works ?
A tech giant gives billions of dollars to an AI startup as an "investment". But hidden in the contract is a strict rule forcing the startup to hand that exact same money straight back to the tech giant to rent their computer servers.
Look at the documented case of Microsoft and OpenAI.
When Microsoft invested $13 billion into OpenAI, it didn't just give them cash; it gave them "cloud credits" to use Microsoft servers. OpenAI used those exact credits to train its AI models, and Microsoft then turned around and recorded that server usage as brand new "cloud revenue" from a customer.
The tech giant is literally paying itself with its own money and calling it a sale.
This is why OpenAI’s annual cloud bill has ballooned to over $60 billion, double its actual revenue of $25 billion, kept alive solely by this recycled funding loop.
Anthropic runs the exact same play, spending $2.66 billion on Amazon Web Services in just nine months, which was basically 100% of all the money it earned at the time.
This manufactured demand triggers a second accounting trick where tech giants book massive paper profits. Every time a startup gets a higher value from a new funding round, the tech giant updates the value of its investment on its books and counts that unearned paper gain as direct profit.
In Q1 2026, Alphabet reported a record $62.6 billion profit, but $28.7 billion nearly half, was just a paper markup on its Anthropic investment. In the same quarter, Amazon reported $30.3 billion in profit, but $16.8 billion of it was just an Anthropic paper gain.
While Amazon reported record profits, its actual free cash flow collapsed 95% to just $1.2 billion because it had to spend $44.2 billion in real cash to build physical data centers.
This has created a massive danger where these giant companies rely heavily on just one or two unstable startups. Microsoft has 49% of its $627 billion future backlog tied to OpenAI, while Oracle has an incredible 54% of its entire $553 billion pipeline relying on OpenAI alone.
This perfectly mirrors the 2001 dot-com crash when Global Crossing and Qwest Communications swapped identical fiber-optic network capacity with each other just to book fake sales.
Qwest had to erase $1.4 billion in fake income, and Global Crossing went completely bankrupt.
The only difference is that the dot-com swaps were illegal, but today's AI loop is fully legal under current accounting rules.
This legal loop inflates tech company stock prices, forcing automatic retirement accounts and index funds to buy even more of these tech stocks. It is a self feeding loop where investments, sales, and stock prices all go up on paper without the AI technology ever making real cash profits.
The $20 AI Subscription Is One of the Greatest Subsidies in Tech History
Most people think they’re paying for AI.
They’re not.
They’re being subsidized.
That $20/month subscription? It barely reflects the true cost of inference, especially when millions of users are generating massive token volumes daily.
Behind every “simple prompt” is:
* GPU clusters burning capital
* Exploding inference costs
* Token usage compounding exponentially
* Profit margins getting squeezed in real time
The economics were manageable when AI adoption was small.
Now everyone is using AI for:
* coding
* research
* content
* automation
* agents
* workflows
* entire business operations
The result?
Per-seat subscription revenue stays relatively flat… while token compute costs scale vertically.
And now the industry is starting to confront reality.
Microsoft is reportedly canceling most internal licenses for Anthropic’s Claude Code by June 30, 2026 — less than six months after rolling it out broadly to engineers — largely due to escalating token-based costs, while redirecting teams toward its own GitHub Copilot CLI ecosystem.
That’s the signal.
Even trillion-dollar companies are optimizing AI usage because inference is becoming the real battlefield.
Training models was only the first phase.
Running them at scale is where the economics break.
This is why the next wave of winners in AI may not be the companies with:
* the smartest models
* the biggest hype
* the most users
But the companies that solve:
* inference efficiency
* token optimization
* memory architecture
* model routing
* smaller specialized models
* AI workflow efficiency
The AI gold rush created a generation addicted to artificially cheap intelligence.
Now the subsidy era is ending.
And the real cost of AI is finally starting to surface.
🦔Fortune published a piece this afternoon connecting Microsoft and Uber's AI cost overruns to token economics, with a headline that lands hard: "Microsoft reports are exposing AI's real cost problem: Using the tech is more expensive than paying human employees." Underneath those headlines, the unit economics tell the story. OpenAI is projected to lose $14 billion in 2026, spending roughly $2 for every dollar of revenue it brings in. Anthropic is in a similar position with break-even not projected until 2028. GPU rental prices for Nvidia's newest Blackwell chips jumped 48% in just two months. OpenAI's response was to close a $122 billion private funding round at an $852 billion valuation, the largest in history.
My Take
The token pricing story is really an IPO timing story. OpenAI, Anthropic, and xAI all need to go public in the next 18 to 24 months because the private market cannot keep absorbing burn rates like these indefinitely. Public markets do not accept "we will figure it out" as a line item on an S-1, they require disclosed unit economics with a credible path to profitability and a date attached. That deadline is why the price increases are happening now rather than next year. The labs need to show declining loss curves before the filings hit, and that means enterprise customers have to start covering more of the actual cost regardless of whether the productivity math holds on their end.
Every token bought over the last two years was effectively subsidized below cost by venture capital and hyperscaler cross-subsidies, and that subsidy has a hard deadline. Uber publicly admitted burning through its entire 2026 AI budget in four months, and CFOs at major enterprises are starting to flag the same pressure. The labs cannot keep losing $2 per dollar of revenue once they file public statements, so the cost transfer to customers accelerates from here. For investors, the question is not whether these companies are valuable. They clearly are. The question is who absorbs the difference between what enterprises can budget and what the models actually consume between now and 2028, and right now the answer is the hyperscalers funding the buildout. That is why I have been watching Microsoft and Amazon capex commentary more closely than the lab announcements themselves.
Hedgie🤗
Link: https://t.co/S2oIgUSijV
Il mondo sta commettendo un errore madornale, e lo sta facendo con l’entusiasmo di chi crede di essere geniale.
Ci hanno convinto che il futuro dell’intelligenza artificiale passi per forza attraverso poche mega-aziende che costruiscono modelli sempre più grandi, sempre più costosi, sempre più centralizzati. Pochi colossi che controllano l’infrastruttura, i dati, il calcolo e, di conseguenza, il pensiero stesso.
È una stupidità collettiva di proporzioni storiche.
La natura non funziona così. Il cervello umano non è un unico enorme processore monolitico: è un sistema distribuito, composto da miliardi di neuroni che formano reti locali, gerarchie, moduli specializzati che interagiscono in modo caotico ma resiliente. La conoscenza umana stessa è **frattale**: si ripete a scale diverse, dal singolo individuo alla comunità, dalla tribù alla civiltà. È ridondante, decentralizzata, capace di sopravvivere alla perdita di intere parti senza collassare.
I piccoli modelli di machine learning specializzati, leggeri, addestrabili localmente, modificabili da chiunque riproducono proprio questa struttura. Un ecosistema di migliaia, milioni di modelli piccoli e medi, ognuno con il proprio dominio di competenza, capaci di collaborare, evolversi e sostituirsi a vicenda. Questo è l’equivalente artificiale di un ecosistema biologico sano: diversità, ridondanza, antifragilità.
Invece stiamo costruendo un sistema monoculturale. Pochi giganti che dominano tutto. Se uno di questi modelli ha un’allucinazione sistemica, se viene compromesso, se i suoi proprietari decidono di censurarlo o orientarlo, l’intero edificio trema. È la stessa fragilità che abbiamo visto nel sistema finanziario nel 2008: troppa concentrazione crea rischi sistemici che nessun “troppo grande per fallire” può davvero mitigare.
La concentrazione di ricchezza e di risorse computazionali non sta portando verso nessuna “singolarità”. Quella parola, tra l’altro, è diventata un contenitore vuoto, un termine mistico da conferenze TED che non significa quasi più nulla. Non stiamo andando verso un’intelligenza onnipotente e unificata. Stiamo andando verso un’intelligenza **fragile**, ostaggio di poche entità private che hanno incentivi allineati più al profitto e al controllo che alla vera esplorazione dell’intelligenza.
Un mondo con migliaia di modelli piccoli sarebbe più caotico, sì. Più disordinato. Più difficile da controllare. Ma sarebbe anche più vivo, più creativo, più resistente. Sarebbe più umano.
Abbiamo dimenticato la lezione più elementare della complessità: i sistemi più robusti non sono quelli più ordinati e centralizzati, ma quelli che somigliano alla natura pieni di imperfezioni, ridondanze e scale frattali.
Stiamo scegliendo l’illusione del controllo assoluto al prezzo della vera intelligenza distribuita. E lo stiamo facendo con la presunzione di chi crede di aver capito il gioco, mentre in realtà sta semplicemente ripetendo gli stessi errori di ogni impero che ha mai creduto di essere eterno.
La decentralizzazione non è un’opzione romantica. È l’unica architettura che ha mai funzionato nella storia dell’evoluzione. Ignorarla sarà pagato caro.
Yann LeCun was right the entire time. And generative AI might be a dead end.
For the last three years, the entire industry has been obsessed with building bigger LLMs. Trillions of parameters. Billions in compute.
The theory was simple: if you make the model big enough, it will eventually understand how the world works.
Yann LeCun said that was stupid.
He argued that generative AI is fundamentally inefficient.
When an AI predicts the next word, or generates the next pixel, it wastes massive amounts of compute on surface-level details.
It memorizes patterns instead of learning the actual physics of reality.
He proposed a different path: JEPA (Joint-Embedding Predictive Architecture).
Instead of forcing the AI to paint the world pixel by pixel, JEPA forces it to predict abstract concepts. It predicts what happens next in a compressed "thought space."
But for years, JEPA had a fatal flaw.
It suffered from "representation collapse."
Because the AI was allowed to simplify reality, it would cheat. It would simplify everything so much that a dog, a car, and a human all looked identical.
It learned nothing.
To fix it, engineers had to use insanely complex hacks, frozen encoders, and massive compute overheads.
Until today.
Researchers just dropped a paper called "LeWorldModel" (LeWM).
They completely solved the collapse problem.
They replaced the complex engineering hacks with a single, elegant mathematical regularizer.
It forces the AI's internal "thoughts" into a perfect Gaussian distribution.
The AI can no longer cheat. It is forced to understand the physical structure of reality to make its predictions.
The results completely rewrite the economics of AI.
LeWM didn't need a massive, centralized supercomputer.
It has just 15 million parameters.
It trains on a single, standard GPU in a few hours.
Yet it plans 48x faster than massive foundation world models. It intrinsically understands physics. It instantly detects impossible events.
We spent billions trying to force massive server farms to memorize the internet.
Now, a tiny model running locally on a single graphics card is actually learning how the real world works.
$UBER hints it’s dumping Ai and Anthropic after blowing its entire Ai budget in 3 months on exorbitantly high costs.
The prices charged by Anthropic are enough to destroy corporations budgets in 3 months, but still far below what they need to charge to reach profitability.
Things are great.
$NVDA
AI-designed proteins that survive 150 °C and nanonewton forces
Proteins are usually fragile machines. Heat them, pull on them, or send them through a high-temperature sterilization step (like those used in hospitals), and most will unfold and aggregate, losing their function. Yet many natural systems—like muscle titin or spider silk—hint that if you organize β-sheet hydrogen bonds in the right way, you can get remarkable mechanical strength and thermal resilience.
Bin Zheng and coauthors take that idea and push it to the extreme. Starting from the titin I27 domain, they use an AI+MD pipeline—RFdiffusion for backbone generation, ProteinMPNN for sequence design, ESMFold/AlphaFold2 for structure prediction, and steered/annealing MD for screening—to systematically elongate the force-bearing β strands and maximize backbone hydrogen bonds in a shearing geometry.
Across multiple design rounds, they grow the network from 4 to 33 backbone H-bonds, creating a “SuperMyo” series of proteins with unfolding forces above 1,000 pN—roughly 4× stronger than I27 under the same pulling conditions. Remarkably, these proteins not only refold after force, but also retain structure and function after exposure to 150 °C and repeated high-temperature sterilization cycles, and can be used as crosslinkers to make hydrogels that survive those treatments intact.
The message is powerful: by combining generative protein design with physics-based simulations, it’s now possible to turn a simple principle—pack as many shear-mode hydrogen bonds as possible into β sheets—into synthetic proteins and materials that rival or surpass nature’s own mechanostable systems, enabling protein-based hydrogels and biomaterials that remain functional under conditions that would normally destroy conventional proteins.
Paper: https://t.co/PMwfQpylqb
Long-read sequencing reveals genomic and epigenomic variation in the dark genome of human Alzheimer's disease. #nanopore#AD#WGS#SV https://t.co/t00t7TBPeo