What are the real problems to be solved in continual learning? In my latest post, I tackle this question — reviewing where I think the field went astray in the past, how language models changed things, and where the real challenges remain. 1/2
Extraordinary scenes on my TL
Guys there’s more than one way to optimize AI on a task. If you’re working on harnesses try to slowly add all these in your bag.
The classic way is to update the weights (RL)… The modern way is to optimize prompts/context (Dspy optimizers/GEPA)… and the hypermodern way is to self evolve the codebase itself (auto research/alpha-evolve/darwin-godel variants)
All of them need an eval dataset of prompts/task scenarios, a rubric of success, and an initial forward pass (harness+model) to learn. They just update different things to get your system to better evals.
There’s nuance to each. There’s a time and place for all of them.
The recording of @xiao_ted's guest lecture on "Three Eras of Robot Learning" at @ETH is now live on YouTube! He shares unique insights on scaling physical AGI, drawing from his experience at @GoogleDeepMind .
📽️ YouTube: https://t.co/9NiKJaUPyo
📚 Course: https://t.co/QJcfXJRfX8
Everyone is talking about "World Models" for robotics, following the buzz from GTC 2026.
But the research landscape is shifting so fast it’s difficult to keep up.
In my view, here are the two dominant paradigms currently grounding the video world models in robot control.
---
Paradigm 1: Use the Video Model as a Simulator
The first major approach is using video world models to simulate reality. In this framework, the model predicts "what happens next" in either pixel space or latent space, conditioned on text prompts or robot actions. Much like traditional analytical simulators (e.g., IsaacSim, MuJoCo, ManiSkill), these learned simulators are used for data synthesis, planning, and evaluation.
1.1 Synthesizing Data for Policy Training
A representative work is DreamGen [1]. Given an initial frame and a language instruction, a fine-tuned video model synthesizes clips of a robot completing a task. An inverse dynamics model then labels these videos with actions to train a separate robot policy. GR00T N1 [2] uses a similar strategy. Alternatively, models can act as interactive simulators where agents (like UniSim [4]) or humans (like Interactive World Simulator [3]) generate data through interaction.
Key Advantages: Thousands of hours of "synthetic experience" at a lower cost and the ability to safely simulate rare, dangerous edge cases.
1.2 Inference-Time Planning
Instead of following a fixed path, robots can use video models to "imagine" multiple future outcomes. In V-JEPA 2 [5], an action-conditioned video model evaluates different action sequences to find the best next step. This "imagination-based planning" is also a core theme in CLASP [6], SWIM [7], VLP [8], GPC [9], DreamDojo [10], and Cosmos Policy [11]. The challenge remains fitting this heavy computation into real-time control budgets.
1.3 Policy Evaluation
Video models allow us to test policies before they ever touch physical hardware. Veo Robotics [12] demonstrates that these models can accurately predict relative performance and perform "red teaming" to expose safety violations. This approach is also seen in IRASim [13], 1XWM [14], Ctrl-World [15], and others.
Summary of Paradigm 1: While powerful, there is no "free lunch." These methods depend on prediction accuracy. Our physical world is complex, and teaching video models to handle every edge case without hallucinating physics remains a significant challenge.
---
Paradigm 2: Use the Video Model as a Policy
The second, more integrated paradigm is using the generative video model as the policy (decision-maker) itself. Because the native outputs are videos rather than robot actions, several methods have been developed to obtain control signals.
2.1 Generating Video and Action Jointly
A straightforward idea is to add an action decoder to the video model backbone and run video and action denoising jointly during inference. Representative works include DreamZero [16], Cosmos Policy [11], Motus [17], PAD [18], GR-1 [19], and GR-2 [20] (note that the GR series are not diffusion models). This method leverages the rich spatiotemporal priors of pre-trained models with minimal architecture changes.
2.2 Extracting Visual Representations for Action Generation
Rather than full generation, many methods use video models to extract deep visual representations to guide action generation. Example works include VPDD [21], VPP [22], UVA [23], UWM [24], Video Policy [25], and DiT4DiT [26]. A major advantage here is that you don’t necessarily need to run multiple denoising steps on giant models, making real-time control easier, though it remains unclear if the full potential of the video models is being utilized.
2.3 Open-loop Video Generation + Video-to-Action Translation
A rising trend involves generating a "desired future" video and using a separate inverse dynamics model to translate that video into actions. UniPi [27] pioneered this, followed by This&That [28], TesserAct [29], and 1XWM Self-Learning [30]. Some methods generate videos of humans completing tasks (Dreamitate [31], Gen2Act [32], LVP [33]) and translate those to robot actions. This approach allows video models to do exactly what they were trained for: video generation.
2.4 Closed-loop Video Generation + Video-to-Action Translation
Open-loop generation often leads to hallucinations: the model might "see" the robot picking up an apple that isn't actually there. Closed-loop generation avoids this by constantly conditioning on the latest real-world observations, replacing generated frames with real ones in the next call. Recently, mimic-video [34] and LingBot-VA [35] reached real-time speeds using KV caching and partial denoising. Most notably, the DVA [36] model released this month manages real-time generation with full video denoising, which means denoising pure noise all the way to clean video for every step. This approach seems really promising to me, because it reduces robot control into a problem of real-time video generation, which can directly benefit from large-scale video pre-training.
---
To me, the key takeaway from this evolution is how we have begun bridging the gap between the digital and physical worlds. Instead of trying to manually program every physical law, we are leveraging the implicit physics embedded in billions of web videos.
Whether we use these models as simulators or as direct policies, the objective is the same: providing robots with a “physical common sense.” By reformulating robot control as a challenge of real-time video generation, we may be on the verge of a new scaling law for embodied intelligence.
[References in the comment]
im often asked “how do i break into robot learning without a phd?”
buy an SO-101 ($300) and do something interesting
understand the stack, train models, implement a paper, do serious on-robot evals, document your work
the pool of talent with real experience is v small
I'm Boris and I created Claude Code. I wanted to quickly share a few tips for using Claude Code, sourced directly from the Claude Code team. The way the team uses Claude is different than how I use it. Remember: there is no one right way to use Claude Code -- everyones' setup is different. You should experiment to see what works for you!
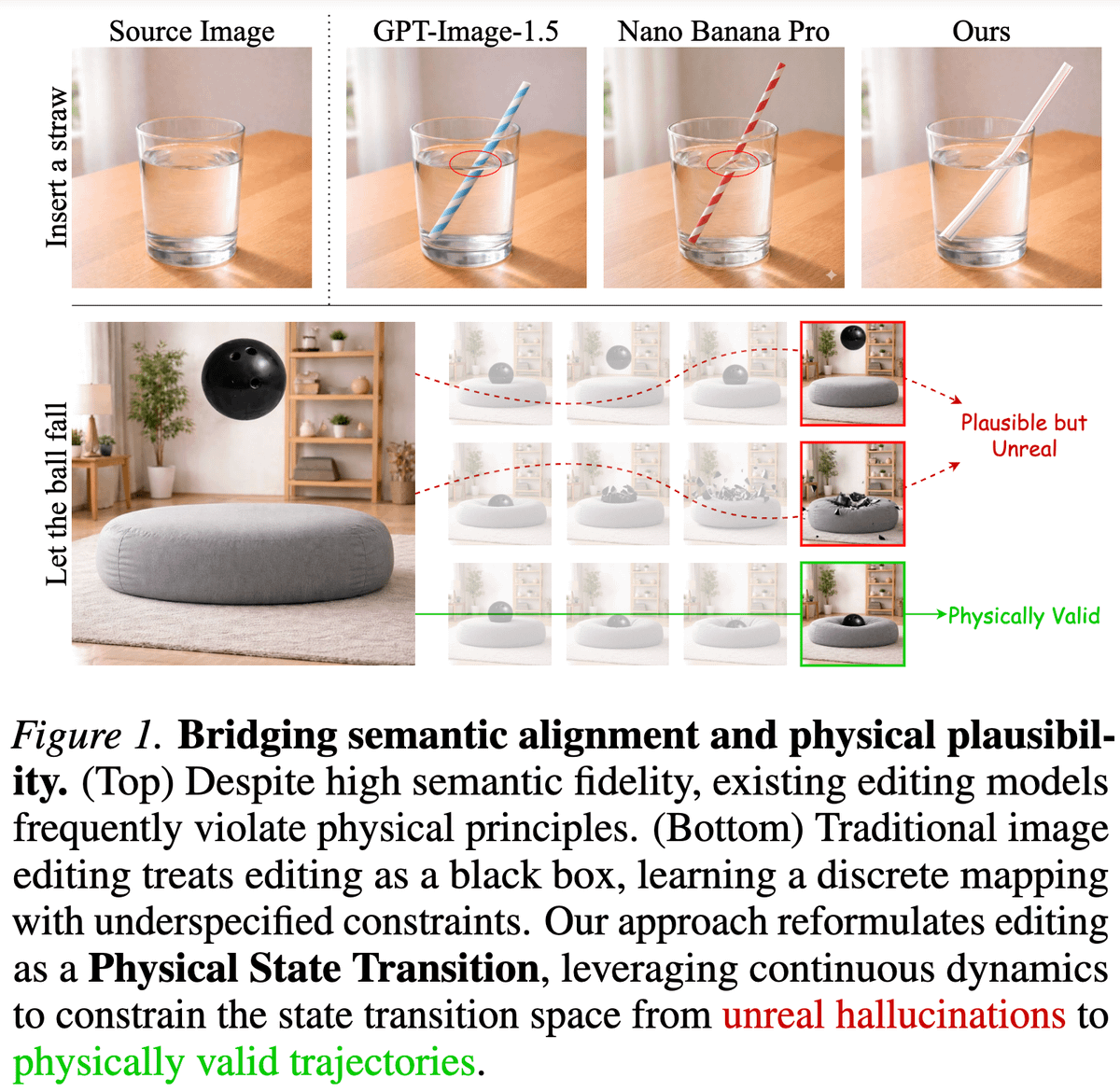
Editing images is a series of state transitions between the source image and the edited image that we want. Yet, the existing paradigm doesn't explicitly include any transitioning priors in the editing process.
This becomes particularly prevalent for edits, involving causal dynamics (e.g., refraction, deformation).
To model this kind of physics-informed information, we leverage the rich priors present in videos and introduce PhysicEdit 🔥
TL;DR: We fine-tune QwenImage Edit on a curated dataset of videos with reasoning traces and fixed-length transition queries to do solid physics-aware image editing!
In the process, we introduce a cool dataset "PhysicTran38K", consisting of 38K transition trajectories across five physical domains and devise a method to provide supervision from it QwenImage Edit.
Hop in to learn more ⬇️
If you're thinking about AI-generated UIs, recommend checking out JELLY by @YiningCao3, @peilingjiang, and @HaijunXia. My favorite kind of work: both a compelling system/demo AND a bigger idea that people can build on!
talk video: https://t.co/Enk5MD1JSb
paper: https://t.co/FhTkoev9nP
tldr: vibe-coded UIs aren't ideal for users generating software, because it's hard to steer the generation and keep things consistent. They propose solving this by first generating a more structured model of the user's needs, including a data schema that the user can see/edit.
Then UIs get generated based on this schema, but it feels more like fluidly composing premade widgets in a task-specific way than building a new "application". Reminds me of @alexobenauer's work on an itemized OS and @jasonyuan's Mercury concept, as well as the Embark system that I worked on.
The demos feel compelling and magical, but there's also enough technical meat to see how this is actually feasible today with LLMs. Really cool.
Things I'm not so sure about:
- I like formality on demand: super unstructured representations (text, drawings) and only adding structure when needed. It seems like Jelly jumps straight to rigid relational models. Good fit for some tasks but not all. I wonder about fitting in less-structured bits and then structuring on-the-fly with LLMs. (As a mitigating factor: the fact that you can edit the schema live on the fly does help a lot, blurring the line between using and creating the software. And structure is really useful for things like different views of the same info)
- I'm curious how much the exposed schema ends up really being useful to users for understanding. Their own user study found the majority of users just relied on the UI rather than the schema. Feels like there's a lot more work to do here to achieve deeper interpretability. The challenge of "how do you tell users what software does without showing code" is endlessly deep...
The technical report of @Meituan_LongCat LongCat-Flash is crazy good and full of novelty.
The model is a 560B passive ~27B active MoE with adaptive number of active parameters depending on the context thanks to the Zero-Computational expert.
1) New architecture
> Layers have 2 Attention blocks and both FFN and MoE, that way you can overlap the 2 all-to-all coms. (also it's only 28 layers but you have to take into account the 2 attention blocks).
> They add the zero-computational expert that tokens can choose and do nothing, kinda like a "sink" for easy tokens.
> For load balancing, they have a dsv3-like aux loss free to set the average real/fake expert per token. They apply a decay schedule to this bias update. They also do loss balance control.
2) Scaling
> They made changes to MLA/MoE to have variance alignment at init. The gains are pretty impressive in Figure 5, but i don't know to what extent this has impact later on.
> Model growth init is pretty cool, they first train a 2x smaller model and then "when it's trained enough" (a bit unclear here how many B tokens) they init the final model by just stacking the layers of the smaller model.
> They used @_katieeverett@Locchiu and al. paper to have hyperparameter transfer with SP instead of muP for the 2x smaller model ig.
3) Stability
> They track Gradient Norm Ratio and cosine similarity between experts to adjust the weight of the load balancing loss (they recommend Gradient Norm Ratio <0.1).
> To avoid large activations, they apply a z-loss to the hidden state, with a pretty small coef (another alternative to qk-clip/norm).
> They set Adam epsilon to 1e-16 and show that you want it to be lower than the gradient RMS range.
4) Others
> They train on 20T tokens for phase 1, "multiple T of tokens" for mid training on STEM/code data (70% of the mixture), 100B for long context extension without yarn (80B for 32k, 20B for 128k). The long context documents represent 25% of the mixture (not sure if it's % of documents or tokens, which changes a lot here).
> Pre-training data pipeline is context extraction, quality filtering, dedup.
> Nice appendix where they show they compare top_k needed for different benchmarks (higher MMLU with 8.32, lower GSM8K with 7.46). They also compare token allocation in deep/shallow layers.
> They release two new benchmarks Meeseeks (multi-turn IF) and VitaBench (real-world business scenario).
> Lots of details in the infra/inference with info on speculative decoding acceptance, quantization, deployment, kernel optimization, coms overlapping, etc.
> List of the different relevent paper in thread 🧵
New: Paper + Code — T2I-Copilot, a training-free multi-agent text-to-image system for agentic co-creation. ICCV 2025:
https://t.co/gXCn6T8nVb
Multi-agent coding systems (e.g., Claude Code) are sweeping the world like a storm this summer. The success rests on a simple but fundamental idea in “Biological Scaling Laws”: intelligence emerges not only from scaling a single mind/model, but even more from effectively orchestrating many specialized models/agents into a society/civilization that can perceive, reason, plan, act, and collaborate.
The same multi-agent scaling principle applies to multimodal AI. We’re open-sourcing T2I-Copilot — a training-free, multi-agent generative AI system we’ve been building since last year.
T2I-Copilot turns text-to-image into agentic co-creation and significantly boosts quality and controllability using open-source base models (e.g., FLUX.1-dev) with help from other multimodal agents — comparable to top industry APIs (Imagen 3, Recraft V3) at the time of submission in March 2025.
In T2I-Copilot, three agentic specialists — Input Interpreter → Generation Engine → Quality Evaluator — bridge human intent and model behavior with pre-generation disambiguation and post-generation iterative improvement.
On GenAI-Bench (VQAScore) we’re comparable to Imagen-3, and +6.17% over FLUX1.1-pro at ~16.6% of its cost. With human-in-the-loop, results improve further.
Open-Source Code & Paper: https://t.co/gXCn6T8nVb
The evolution of Agentic AI—and our human PhD students—never stops. We’ll keep iterating and add newer open-source models before @ICCVConference (Hawaii, Oct 2025). Big shout-out to @ChiehYun6, @flying_lynx, and Eric for spearheading this effort. 🐝🚀
Photoshop’s new harmonize feature looks genuinely useful — effectively making complex compositing tasks just one click.
Seems Adobe has productized Project Perfect Blend from their sneaks presentation.
A number of people asked If I can share the convo and yes sure - these were the 4 convos with my super noob swift questions lol:
1 starting the app
https://t.co/TMyPAK2RhZ
2 enhancements
https://t.co/vWnkwMrMe8
3 adding AppStorage to persist state over time
https://t.co/NVxc7p1uVH
4 deploy to phone
https://t.co/e4xo4cmcWR
and this is what it looks like late last night
https://t.co/7B8Qp4L0gN
I'm already happily using it today for tracking, and will probably hack on it more on this fine sunday.
I was given early access to Grok 3 earlier today, making me I think one of the first few who could run a quick vibe check.
Thinking
✅ First, Grok 3 clearly has an around state of the art thinking model ("Think" button) and did great out of the box on my Settler's of Catan question:
"Create a board game webpage showing a hex grid, just like in the game Settlers of Catan. Each hex grid is numbered from 1..N, where N is the total number of hex tiles. Make it generic, so one can change the number of "rings" using a slider. For example in Catan the radius is 3 hexes. Single html page please."
Few models get this right reliably. The top OpenAI thinking models (e.g. o1-pro, at $200/month) get it too, but all of DeepSeek-R1, Gemini 2.0 Flash Thinking, and Claude do not.
❌ It did not solve my "Emoji mystery" question where I give a smiling face with an attached message hidden inside Unicode variation selectors, even when I give a strong hint on how to decode it in the form of Rust code. The most progress I've seen is from DeepSeek-R1 which once partially decoded the message.
❓ It solved a few tic tac toe boards I gave it with a pretty nice/clean chain of thought (many SOTA models often fail these!). So I upped the difficulty and asked it to generate 3 "tricky" tic tac toe boards, which it failed on (generating nonsense boards / text), but then so did o1 pro.
✅ I uploaded GPT-2 paper. I asked a bunch of simple lookup questions, all worked great. Then asked to estimate the number of training flops it took to train GPT-2, with no searching. This is tricky because the number of tokens is not spelled out so it has to be partially estimated and partially calculated, stressing all of lookup, knowledge, and math. One example is 40GB of text ~= 40B characters ~= 40B bytes (assume ASCII) ~= 10B tokens (assume ~4 bytes/tok), at ~10 epochs ~= 100B token training run, at 1.5B params and with 2+4=6 flops/param/token, this is 100e9 X 1.5e9 X 6 ~= 1e21 FLOPs. Both Grok 3 and 4o fail this task, but Grok 3 with Thinking solves it great, while o1 pro (GPT thinking model) fails.
I like that the model *will* attempt to solve the Riemann hypothesis when asked to, similar to DeepSeek-R1 but unlike many other models that give up instantly (o1-pro, Claude, Gemini 2.0 Flash Thinking) and simply say that it is a great unsolved problem. I had to stop it eventually because I felt a bit bad for it, but it showed courage and who knows, maybe one day...
The impression overall I got here is that this is somewhere around o1-pro capability, and ahead of DeepSeek-R1, though of course we need actual, real evaluations to look at.
DeepSearch
Very neat offering that seems to combine something along the lines of what OpenAI / Perplexity call "Deep Research", together with thinking. Except instead of "Deep Research" it is "Deep Search" (sigh). Can produce high quality responses to various researchy / lookupy questions you could imagine have answers in article on the internet, e.g. a few I tried, which I stole from my recent search history on Perplexity, along with how it went:
- ✅ "What's up with the upcoming Apple Launch? Any rumors?"
- ✅ "Why is Palantir stock surging recently?"
- ✅ "White Lotus 3 where was it filmed and is it the same team as Seasons 1 and 2?"
- ✅ "What toothpaste does Bryan Johnson use?"
- ❌ "Singles Inferno Season 4 cast where are they now?"
- ❌ "What speech to text program has Simon Willison mentioned he's using?"
❌ I did find some sharp edges here. E.g. the model doesn't seem to like to reference X as a source by default, though you can explicitly ask it to. A few times I caught it hallucinating URLs that don't exist. A few times it said factual things that I think are incorrect and it didn't provide a citation for it (it probably doesn't exist). E.g. it told me that "Kim Jeong-su is still dating Kim Min-seol" of Singles Inferno Season 4, which surely is totally off, right? And when I asked it to create a report on the major LLM labs and their amount of total funding and estimate of employee count, it listed 12 major labs but not itself (xAI).
The impression I get of DeepSearch is that it's approximately around Perplexity DeepResearch offering (which is great!), but not yet at the level of OpenAI's recently released "Deep Research", which still feels more thorough and reliable (though still nowhere perfect, e.g. it, too, quite incorrectly excludes xAI as a "major LLM labs" when I tried with it...).
Random LLM "gotcha"s
I tried a few more fun / random LLM gotcha queries I like to try now and then. Gotchas are queries that specifically on the easy side for humans but on the hard side for LLMs, so I was curious which of them Grok 3 makes progress on.
✅ Grok 3 knows there are 3 "r" in "strawberry", but then it also told me there are only 3 "L" in LOLLAPALOOZA. Turning on Thinking solves this.
✅ Grok 3 told me 9.11 > 9.9. (common with other LLMs too), but again, turning on Thinking solves it.
✅ Few simple puzzles worked ok even without thinking, e.g. *"Sally (a girl) has 3 brothers. Each brother has 2 sisters. How many sisters does Sally have?"*. E.g. GPT4o says 2 (incorrectly).
❌ Sadly the model's sense of humor does not appear to be obviously improved. This is a common LLM issue with humor capability and general mode collapse, famously, e.g. 90% of 1,008 outputs asking ChatGPT for joke were repetitions of the same 25 jokes. Even when prompted in more detail away from simple pun territory (e.g. give me a standup), I'm not sure that it is state of the art humor. Example generated joke: "*Why did the chicken join a band? Because it had the drumsticks and wanted to be a cluck-star!*". In quick testing, thinking did not help, possibly it made it a bit worse.
❌ Model still appears to be just a bit too overly sensitive to "complex ethical issues", e.g. generated a 1 page essay basically refusing to answer whether it might be ethically justifiable to misgender someone if it meant saving 1 million people from dying.
❌ Simon Willison's "*Generate an SVG of a pelican riding a bicycle*". It stresses the LLMs ability to lay out many elements on a 2D grid, which is very difficult because the LLMs can't "see" like people do, so it's arranging things in the dark, in text. Marking as fail because these pelicans are qutie good but, but still a bit broken (see image and comparisons). Claude's are best, but imo I suspect they specifically targeted SVG capability during training.
Summary. As far as a quick vibe check over ~2 hours this morning, Grok 3 + Thinking feels somewhere around the state of the art territory of OpenAI's strongest models (o1-pro, $200/month), and slightly better than DeepSeek-R1 and Gemini 2.0 Flash Thinking. Which is quite incredible considering that the team started from scratch ~1 year ago, this timescale to state of the art territory is unprecedented. Do also keep in mind the caveats - the models are stochastic and may give slightly different answers each time, and it is very early, so we'll have to wait for a lot more evaluations over a period of the next few days/weeks. The early LM arena results look quite encouraging indeed. For now, big congrats to the xAI team, they clearly have huge velocity and momentum and I am excited to add Grok 3 to my "LLM council" and hear what it thinks going forward.
OpenAI just dropped a paper that reveals the blueprint for creating the best AI coder in the world.
But here’s the kicker: this strategy isn’t just for coding—it’s the clearest path to AGI and beyond.
Let’s break it down 🧵👇




































![tongzhou_mu's tweet photo. Everyone is talking about "World Models" for robotics, following the buzz from GTC 2026.
But the research landscape is shifting so fast it’s difficult to keep up.
In my view, here are the two dominant paradigms currently grounding the video world models in robot control.
---
Paradigm 1: Use the Video Model as a Simulator
The first major approach is using video world models to simulate reality. In this framework, the model predicts "what happens next" in either pixel space or latent space, conditioned on text prompts or robot actions. Much like traditional analytical simulators (e.g., IsaacSim, MuJoCo, ManiSkill), these learned simulators are used for data synthesis, planning, and evaluation.
1.1 Synthesizing Data for Policy Training
A representative work is DreamGen [1]. Given an initial frame and a language instruction, a fine-tuned video model synthesizes clips of a robot completing a task. An inverse dynamics model then labels these videos with actions to train a separate robot policy. GR00T N1 [2] uses a similar strategy. Alternatively, models can act as interactive simulators where agents (like UniSim [4]) or humans (like Interactive World Simulator [3]) generate data through interaction.
Key Advantages: Thousands of hours of "synthetic experience" at a lower cost and the ability to safely simulate rare, dangerous edge cases.
1.2 Inference-Time Planning
Instead of following a fixed path, robots can use video models to "imagine" multiple future outcomes. In V-JEPA 2 [5], an action-conditioned video model evaluates different action sequences to find the best next step. This "imagination-based planning" is also a core theme in CLASP [6], SWIM [7], VLP [8], GPC [9], DreamDojo [10], and Cosmos Policy [11]. The challenge remains fitting this heavy computation into real-time control budgets.
1.3 Policy Evaluation
Video models allow us to test policies before they ever touch physical hardware. Veo Robotics [12] demonstrates that these models can accurately predict relative performance and perform "red teaming" to expose safety violations. This approach is also seen in IRASim [13], 1XWM [14], Ctrl-World [15], and others.
Summary of Paradigm 1: While powerful, there is no "free lunch." These methods depend on prediction accuracy. Our physical world is complex, and teaching video models to handle every edge case without hallucinating physics remains a significant challenge.
---
Paradigm 2: Use the Video Model as a Policy
The second, more integrated paradigm is using the generative video model as the policy (decision-maker) itself. Because the native outputs are videos rather than robot actions, several methods have been developed to obtain control signals.
2.1 Generating Video and Action Jointly
A straightforward idea is to add an action decoder to the video model backbone and run video and action denoising jointly during inference. Representative works include DreamZero [16], Cosmos Policy [11], Motus [17], PAD [18], GR-1 [19], and GR-2 [20] (note that the GR series are not diffusion models). This method leverages the rich spatiotemporal priors of pre-trained models with minimal architecture changes.
2.2 Extracting Visual Representations for Action Generation
Rather than full generation, many methods use video models to extract deep visual representations to guide action generation. Example works include VPDD [21], VPP [22], UVA [23], UWM [24], Video Policy [25], and DiT4DiT [26]. A major advantage here is that you don’t necessarily need to run multiple denoising steps on giant models, making real-time control easier, though it remains unclear if the full potential of the video models is being utilized.
2.3 Open-loop Video Generation + Video-to-Action Translation
A rising trend involves generating a "desired future" video and using a separate inverse dynamics model to translate that video into actions. UniPi [27] pioneered this, followed by This&That [28], TesserAct [29], and 1XWM Self-Learning [30]. Some methods generate videos of humans completing tasks (Dreamitate [31], Gen2Act [32], LVP [33]) and translate those to robot actions. This approach allows video models to do exactly what they were trained for: video generation.
2.4 Closed-loop Video Generation + Video-to-Action Translation
Open-loop generation often leads to hallucinations: the model might "see" the robot picking up an apple that isn't actually there. Closed-loop generation avoids this by constantly conditioning on the latest real-world observations, replacing generated frames with real ones in the next call. Recently, mimic-video [34] and LingBot-VA [35] reached real-time speeds using KV caching and partial denoising. Most notably, the DVA [36] model released this month manages real-time generation with full video denoising, which means denoising pure noise all the way to clean video for every step. This approach seems really promising to me, because it reduces robot control into a problem of real-time video generation, which can directly benefit from large-scale video pre-training.
---
To me, the key takeaway from this evolution is how we have begun bridging the gap between the digital and physical worlds. Instead of trying to manually program every physical law, we are leveraging the implicit physics embedded in billions of web videos.
Whether we use these models as simulators or as direct policies, the objective is the same: providing robots with a “physical common sense.” By reformulating robot control as a challenge of real-time video generation, we may be on the verge of a new scaling law for embodied intelligence.
[References in the comment]](https://pbs.twimg.com/media/HD3uASFaUAAQbD_.jpg)