🚀 AI is business superpower that helps grow revenue, reduce costs, and delight customers... and this is just the beginning.
To take advantage of the AI Transformation that is coming, today we explore 10 groundbreaking AI technologies that are revolutionizing industries right now:
🤝 Human-AI Collaboration: Amplify your team's capabilities
🏰 AI-Powered Reliability: Prevent issues before they happen
🌐 Edge Computing & AI: Make smart decisions in real-time
🛡️ Next-Gen Cybersecurity: Stay one step ahead of threats
🔮 Predictive Analytics & Digital Twins: Test strategies risk-free
🧭 Trustworthy AI: Build unshakeable customer confidence
📂 Open-Source AI: Tap into global innovation
🐘 Large v 🐁 Small Models: The right tool for every job
🧠 Self-Learning AI: Systems that improve automatically
🔬 Quantum-Ready Infrastructure: Prepare for computing's next leap
Why does this matter to you? Because these technologies aren't just for tech giants—they're becoming as essential as electricity or the internet for businesses of all sizes.
By understanding these AI pillars, you'll be equipped to:
⚡️ Make faster, more accurate decisions
⚙️ Dramatically improve operational efficiency
✅ Enhance customer experiences and build trust
📈 Stay ahead of competitors in rapidly evolving markets
🤖 Future-proof your business against technological disruptions
Don't let the AI revolution pass you by. Watch our video to learn how these technologies can propel your business to new heights.
The future is here—are you ready to harness its power?
#AIinBusiness #FutureOfWork #DigitalTransformation #ExecutiveStrategy #Entrepreneurs #Innovation
A Russian psychologist spent 10 years proving that the act of talking to yourself out loud is one of the most powerful cognitive tools the human brain has, and almost nobody outside his field has read the work.
His name was Lev Vygotsky.
He worked in Moscow in the 1920s and died of tuberculosis in 1934 at the age of 37. He had no laboratory, no funding, almost no English readers, and a body of work that the Soviet government suppressed for two decades after he died.
He produced the foundational theory of how human cognition actually develops, and the central piece of that theory was a behavior almost every adult is faintly embarrassed about.
Vygotsky noticed that young children talk to themselves constantly. They narrate their own actions, they argue with imaginary opponents, they instruct themselves through tasks out loud.
The dominant theory at the time, from the Swiss psychologist Jean Piaget, said this was a sign of cognitive immaturity that children would eventually grow out of as they learned to think properly.
Vygotsky said the exact opposite.
He argued that this self-directed speech was the most important cognitive event in the entire developmental window, because it was the moment a child first started to use language as a tool to control their own mind. The child was not failing to think. The child was learning how to think by externalizing the process and listening to themselves do it.
He predicted that as children matured, this out-loud self-talk would not disappear. It would go underground. It would become silent inner speech, which is the running monologue every adult has inside their own head for the rest of their life.
The voice you hear when you read this sentence is the direct descendant of a four-year-old narrating their own block tower.
For 50 years almost nobody outside Russia had access to his work, and the few researchers who did pick it up could not get funding to test it. Then in the early 2000s the experiments finally started to pile up, and what they found was that Vygotsky had been right about something even more important than he knew.
The first major study came from Gary Lupyan at the University of Wisconsin and Daniel Swingley at the University of Pennsylvania in 2012. They ran a simple visual search experiment. Participants were shown 20 images at once and asked to find a specific object, like a banana or a chair. In one condition they searched silently. In the other condition they were told to say the name of the object out loud to themselves while looking for it.
The participants who spoke the target name out loud found the object significantly faster, with higher accuracy, than the participants who searched in silence. The effect was strongest when the spoken word matched a familiar object the brain already had a strong category for.
Saying the word out loud literally tuned the visual system to detect that thing better. The researchers called it the label feedback effect, and the implication was that the act of vocalizing a goal physically changes how the brain processes the world while pursuing it.
The second major study came out of the University of Michigan and Michigan State in 2017. The lead researchers were Ethan Kross and Jason Moser, and they used both EEG and fMRI to record what happens inside the brain when people talk to themselves while emotionally upset.
They asked participants to recall painful autobiographical memories and reflect on them in two different ways. Some used the first person, saying things like "why am I feeling this way." Others used the third person, referring to themselves by their own name, saying things like "why is John feeling this way."
The brain scans showed that the simple act of switching from first person to third person, even silently, decreased activity in the medial prefrontal cortex, the region responsible for rumination and self-referential pain. Within a single second of using their own name instead of the word I, participants showed measurably lower emotional reactivity. The shift required no extra cognitive effort. It cost the brain nothing. And it worked.
Kross described the mechanism in his interviews. Talking to yourself by name creates a small amount of psychological distance from your own experience. Your brain processes the situation more like a problem belonging to someone else, which means it can analyze it instead of drowning in it.
What Vygotsky had intuited in 1934 turned out to be even more powerful than the developmental theory he built it into. The voice you use to talk to yourself is not background noise. It is one of the most precise cognitive tools the brain has, and you can change how it works just by changing the pronoun you use.
People who talk through problems out loud are not anxious or unstable. They are running an externalized version of a process the rest of us are running silently and worse. The kindergartener narrating their block tower, the surgeon muttering through a procedure, the engineer pacing a hallway describing a bug to nobody, the athlete repeating a cue to themselves before a free throw, they are all using the same ancient mechanism that builds and steers human thought.
You can run the experiment yourself the next time you are stuck on something hard. Stop trying to solve it silently in your head. Say it out loud. Describe what you are seeing. Walk yourself through the steps as if you were explaining it to a colleague who is not in the room.
And when something genuinely upsets you, switch to your own name. Ask why this person is feeling this way, instead of why I am feeling this way.
The voice you have been told to keep quiet your entire life is one of the oldest pieces of cognitive technology you own.
Most people are still embarrassed to use it.
I want some kind of LLM workflow tool.
• Ability to manage a set of input files (Markdown or similar), plus other general-purpose context.
• With real-time collaboration. (And maybe some concept of snapshots or VCS integration.)
• And the ability to create/manage a inference workflows and a stored set of prompts.
• Access to general-purpose coding agents (and not just chat models).
• Some concept of compiled outputs/inference results (which ideally can be shared externally).
Many projects have this feeling: "there is all this stuff, which I want to process/compute over in this iterated way, with some build artifacts being important/worth saving." GNU Autotools x Notion or something. Is anyone building this?
Your margin is my opportunity: AI version…
The biggest surprise of 2026 is that the capability gap between the best open-weight/source models and the best closed models has narrowed much faster than the pricing gap. The pricing gap remains enormous while the capability gap is quite narrow.
What does this means in practice?
For a company consuming 1 billion input tokens and 1 billion output tokens per month:
GPT-5.5 Pro: ~$105,000
Claude Opus 4.8: ~$30,000
DeepSeek V4 Pro: ~$5,220
DeepSeek R1: ~$2,740
I asked ChatGPT what it thought about this and it answered as follows:
“If I were building a company today, the economic frontier would look roughly like:
DeepSeek V4 Pro / R1 for high-volume inference.
Claude Opus for premium agent workflows where reliability matters.
GPT-5.5 Pro only for workloads where its incremental capability demonstrably produces enough business value to justify a 20–40× token premium.”
Most CEOs have no idea that, instead of this nuanced approach, their teams are running amok internally by picking the most expensive models in most cases and burning through massive budgets with zero governance, audit ability and control.
As control planes like our Software Factory become more standard, you can expect the run rate revenue growth of the frontier labs to go down meaningfully and the revenues of the open models to skyrocket.
Why? Because we can implement the nuanced approach above and be agnostic to model - instead focusing on customer intent, model task and cost management among other things.
From John Plender's FT column:
"At the same time, Treasury funding is increasingly reliant on shorter-term securities, which means constant rollover risk. With US public debt approaching its highest ever level, this combination sounds like the very definition of a non-geopolitical financial chokepoint, with vulnerability to shocks. It also suggests there are now systemic risks in the Treasury market."
#economy #markets #bonds
A scientist in Denmark figured out how to make Claude prepare his job applications. He open-sourced the whole thing.
His name is Mads Lorentzen. He is a PhD geophysicist. He built it on top of Claude Code and released it under MIT license.
Here is what it does. You fork the repo, fill in your background once, and it runs a five-step pipeline for every job you want to apply to.
Step 1. It reads the job posting and scores how well you fit.
Step 2. It drafts a tailored CV in LaTeX, picking only the experience that matches.
Step 3. It writes a cover letter framed around what you would bring to the role.
Step 4. A second AI agent reviews the first agent's work, points out weaknesses, and the first agent revises.
Step 5. It compiles both into clean PDFs you can send.
The whole thing is a folder of markdown files. The candidate profile, the writing style rules, the CV templates, the interview prep notes. Every step is plain text you can read and change.
The job portal search is built for Danish boards. The application workflow itself works for any country.
489 stars. 270 forks. A fork-to-star ratio that high means people are using it, not only bookmarking.
Mads is not a startup founder. He built this because he needed it for himself, then shared it.
This is the future of job hunting. Not a service you pay for. A workflow you own.
(Link in the comments)
This is huge.
A group of 50 AI researchers (ByteDance, Alibaba, Tencent + universities) just dropped a 303 page field guide on code models + coding agents.
And the takeaways are not what most people assume.
Here are the highlights I’m thinking about (as someone who lives in Python + agents):
A Stanford neuroscientist warns high cortisol wrecks memory, enlarges your fear center, and make your brain feel broken.
If I wanted to fix it naturally, I'd do these 8 things every day:
1. Walk barefoot on grass for 5–7 minutes.
Again, maybe counterintuitive, but in the majority of conversations I have with CIOs, CTOs, and CEOs in large enterprises, they are either growing due to AI (in new job functions like FDEs, engineering, etc.) or at a minimum reinvesting efficiency savings back into the business in new areas (sales, marketing, etc.).
David Solomon, CEO of Goldman Sachs, articulated this perfectly in a NYTimes OpEd last week. The AI boom is both creating all new jobs in the build out of AI systems and the implementation across sectors, but also freeing up dollars to invest in areas that have been underfunded or have more demand now because of AI.
Most businesses have been constrained by how much software they can produce at a given cost, how many sales reps they can hire, how many marketing campaigns they can run, how they can do outbound customer success motions with enough tailoring, how they can find more risk in their business and prevent it, and 100s of other things.
When AI makes it possible to do more of this, investment goes back into the business. The companies that better serve their customers win over the long run, and those that just try and find savings end up doing worse.
Artificial Analysis and IBM Research are launching ITBench-AA, the first in a new series of benchmarks evaluating models on agentic enterprise IT tasks, starting with Site Reliability Engineering tasks where frontier models score below 50%
ITBench-AA’s SRE tasks benchmark model performance on Kubernetes incident response, where models must diagnose live systems by reading logs, tracing dependencies, and identifying root-cause entities across complex infrastructure. The underlying ITBench dataset has been developed by @IBM's Software Innovation Lab, leveraging IBM’s deep expertise in enterprise IT operations
Artificial Analysis has worked closely with IBM over the last 6 months to develop a implementation of the dataset for frontier AI evaluation, beginning with Site Reliability Engineering (SRE) and expanding to Financial Operations (FinOps) and Chief Information Security Officer (CISO) tasks over time
ITBench-AA SRE overview:
➤ 59 SRE tasks in total: 40 public tasks and 19 brand new, held-out tasks
➤ Each task provides a Kubernetes incident snapshot containing alerts, events, traces, metrics, logs, and application topology. The model must identify the minimal set of independent root-cause Kubernetes entities responsible for the incident
➤ Faults span typical SRE failure modes including infrastructure, service, application, and chaos-injected incidents, such as resource quota exhaustion, rollout failures, connection pool exhaustion, and network partitions
Methodology details:
➤ Agentic harness: each task is solved by the model running in our open-source Stirrup reference harness, with shell access to a sandboxed file system containing the relevant logs and snapshots. 100-turn cap per task, 3 repeats per task
➤ Models submit a list of root-cause entities (Kubernetes Deployments, Services, Pods, etc.) they believe caused the incident. Each submission is compared against a ground-truth set of root causes provided by IBM Research
➤ Scoring uses average precision at full recall: if a model misses any of the ground-truth root causes, it scores 0.0 for that repeat. If it identifies all of them, it is awarded a score equal to its precision - the share of its submitted entities that are actual root causes, i.e. true positives / (true positives + false positives). The headline score is the average across 59 tasks × 3 repeats.
➤ The harness (Stirrup) is held constant across all evaluated models, allowing an apples-to-apples comparison between models.
Key findings:
➤ Claude Opus 4.7 (Adaptive Reasoning, Max Effort) leads at 47%, followed by GPT-5.5 (xhigh) at 46% and Qwen3.7 Max at 42%
➤ All frontier models score below 50%, making ITBench-AA SRE one of the least saturated agentic benchmarks in our suite. For context, frontier models score considerably higher on Terminal-Bench
➤ Turn counts vary nearly 3x and longer trajectories do not translate to higher accuracy. GPT-5.5 (xhigh) averages 31 turns per task at 46%, while Gemini 3.1 Pro Preview averages 83 turns at 30%. Models that over-investigate tend to surface upstream fault-injection mechanisms or co-occurring symptoms as false positives
➤ GLM-5.1 (Reasoning) leads open weights models at 40%, effectively tied with Gemini 3.5 Flash (high). DeepSeek V4 Pro (Reasoning, Max Effort) follows at 38%, with Gemma 4 31B (Reasoning) at 37%, ahead of Gemini 3.1 Pro Preview at 30%
We took another look at the capability gap between open-weight and proprietary models. Since the start of the year, open-weight models have lagged the state of the art by four months.
This survey suggests over 80% of companies have seen no productivity gains from AI so far, despite billions in spending.
Among 6,000 executives, 1/3 of leaders said they use AI, but only for 90 minutes a week.
This is even though most respondents believe AI will increase productivity by 1.4%, cut staff by 0.7%, and boost output by 0.8% in the next 3 years.
Of the executives, a third said they use AI at work, but only around 1.5 hours per week on average. Meanwhile, 25% of those surveyed have not used AI yet.
---
nber .org/papers/w34836
We're in the weirdest job market of all time.
From 2020 to mid 2022, companies were hiring at a pace that made no sense.
Some teams grew 50%, some doubled. Everyone was afraid of missing out on talent, so they just kept adding headcount. If you could spell the word "javascript" you could land a remote role and a 25% raise.
Then the second half of 2022 hit and the hangover started. Layoff after layoff. Each wave was supposed to be "the last one."
Now in 2026 there are already over 130,000 tech layoffs and we still have another 6 months to go in the year.
The twist this time is AI.
Companies aren't just saying they overhired anymore.
They're saying AI is making them leaner. That they can do more with fewer people. It's become the convenient new reason that sounds strategic while making their stock pop.
But here's where it gets absurd.
More and more companies are admitting the AI math isn't working out. They can't find the ROI they promised their boards. The computing costs are massive. It's more expensive than they thought, not less.
So let me get this straight.
We're in a job market where companies fired their workforce to buy something they now say is too expensive and doesn't work as advertised.
And the executives responsible for those decisions? They're still collecting their bonuses.
Weirdest job market of all time.
Also from the @WSJ:
"Worker compensation—wages and benefits—grew 0.8% in the first quarter from the fourth, while domestic corporate profits jumped 2.7%.
As a result, labor’s share of gross domestic income (conceptually similar to GDP) sank to 51%, the lowest since records began in 1947. "
#economy #Inequality
Hot take on what comes next, after the sudden decline of tokenmaxxing:
- OpenAI will struggle
- with the decline of tokenmaxxing Anthropic will struggle (aside from this quarter) to make a profit
- Google will catch up to Anthropic
- some Chinese companies might, too
- LLMs will become commodities; margins will be very very thin
- Most of the companies that invested massively in them will struggle to make back their investments
- SpaceX’s AI efforts will flail
- Nvidia will eventually decline, once all of the above becomes widely recognized.
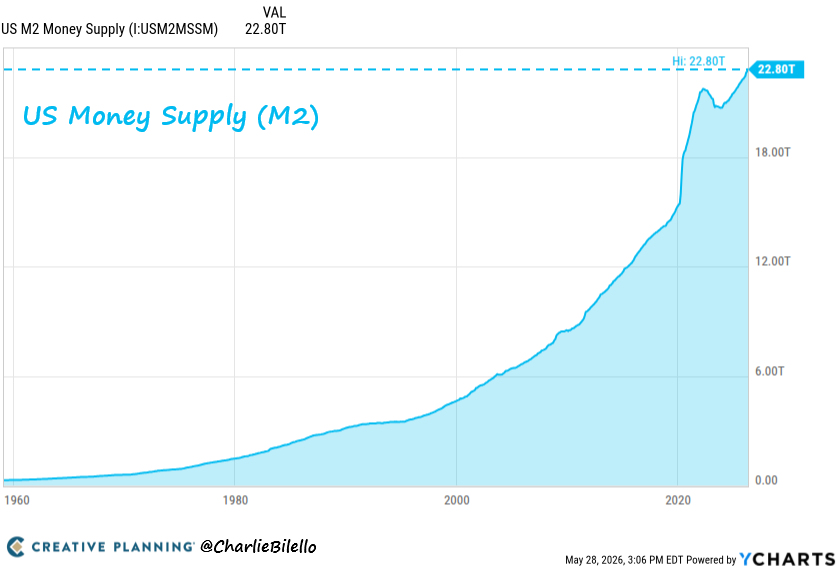
The Fed expanded the money supply by nearly $9 trillion under Powell.
Inflation has averaged >4% per year over the past 6 years.
Powell's explanation? It was nearly all due to rolling “supply shocks" over which the Fed has no control.
The truth: this inflation was made in Washington as it always is - from too much government borrowing/spending and too much government creation of money.
Wall Street Journal:
"In the first quarter of this year, the percentage of [US] credit-card balances that were at least 90 days delinquent rose to 13.12%.... That’s the highest level in 15 years, and the most since the period following the 2008 financial crisis."
#economy #markets #affordability @WSJ
We keep hearing about 10x or 100x productivity gains in engineering and knowledge work.
But outside the model labs, I haven’t seen the corresponding 10-100x revenue growth across the market or increase in quality.
So where is the productivity going?
Since Opus 4.8 is out and more and more designers are getting into Design Engineering, I thought I’d share some of the interaction patterns I use most often:
Use proximity, not just hover. When the cursor gets close, nearby elements can subtly scale and darken based on distance.
It makes interfaces feel more responsive, less binary, and way more alive
onpointermove = e =>
document.querySelectorAll(".dock>*").forEach(el => {
const r = el.getBoundingClientRect();
const t = Math.max(0, 1 - Math.abs(e.clientX - r.x - r.width/2) / 120);
el. style.scale = 1 + t * .5;
});


































![elerianm's tweet photo. Wall Street Journal:
"In the first quarter of this year, the percentage of [US] credit-card balances that were at least 90 days delinquent rose to 13.12%.... That’s the highest level in 15 years, and the most since the period following the 2008 financial crisis."
#economy #markets #affordability @WSJ](https://pbs.twimg.com/media/HJfBIfcWYAcAiAR.jpg)





























