"I looked round the trees. The thin net of reality. These trees, this sun. I was infinitely far from home. The profoundest distances are never geographical."
~John Fowles, The Magus
How do you improve vehicle #simulation when key physics are difficult to model directly? This #webinar with Dr. Michael Hoffmann explores how Scientific Machine Learning in #Dyad helps engineers combine test data with physics-based models to uncover missing behaviour, improve ride model fidelity, and avoid the trade-off between rigid first-principles models and black-box AI. A practical session for simulation and vehicle dynamics teams. Register now - https://t.co/uMuekBOGg7
#julialang #Dyad #ScientificMachineLearning #VehicleDynamics #Simulation #Engineering #SciML
Run @tenstorrent kernels on your CPU.
ttsim is a bit-exact, full-system simulator of Wormhole and Blackhole. The whole tt-metal stack on Linux, Mac (UTM/QEMU) or Windows (WSL2) — numerics match silicon bit-for-bit.
Bring up kernels of explore the architecture. No silicon required. First of its kind. Now Open Source
https://t.co/AtcZ9L9e6T
"A team of UCLA computer scientists and mathematicians has been awarded a three-year, $5 million grant by the Defense Advanced Research Projects Agency to develop artificial intelligence tools aimed at transforming how mathematical discoveries are made."
https://t.co/pJ3PKoD1F1
I am very proud of the progress that @RenPhilanthropy and its partners have made in our first two years – $533 million in funding for science and technology, launching more than 20 programs, training 45 scientists and innovators to design transformative, ARPA-style programs, partnering with the UK, German and Japanese governments, and publishing our first 10 playbooks on the “how” of innovation. Our field strategists are accelerating progress in areas such as AI for fundamental math, AI for early literacy, geologic hydrogen, stabilizing the Arctic climate, low-cost space telescopes, and open-source software for life sciences. Thanks to all the philanthropists, foundations, and governments that have supported our work – and please reach out if you’d like to collaborate. The best is yet to come!
Introducing Ineffable Intelligence. Led by David Silver, we're assembling the best engineers and researchers in the world to make first contact with superintelligence. We’ll be solving the hardest problems in AI on the way. Come join us.
https://t.co/zUuvPJGmcq
Boost Blueprint 036: Boost.Pool. Fast, fixed-size-block memory allocation with O(1) allocate and deallocate — no fragmentation, no per-object header overhead, no free-list traversal
object_pool<T> constructs and destroys typed objects; singleton_pool gives you thread-safe global pools; pool_allocator plugs directly into STL containers. All memory returned to the system in one shot on pool destruction
Level up your C++ architecture. Follow @Boost_Libraries for the #BoostBlueprint series
#cpp
We’re launching the beta for our new commercial AI product: Sakana Fugu 🐡, a multi-agent orchestration system!
Blog: https://t.co/36Ud311KCP
Fugu hits SOTA on SWE-Pro, GPQA-D, and ALE-Bench, and has been our internal secret weapon. It dynamically coordinates frontier models, autonomously selecting the optimal agent combinations and roles for each task.
Available as an OpenAI-compatible API, you can seamlessly integrate Fugu into your existing workflows with minimal changes.
🐟 Fugu Mini: High-speed orchestration optimized for latency
🐡 Fugu Ultra: Full model pool utilization for deep, complex reasoning
Apply for the beta test here: https://t.co/1fjuAha7ci
Today, MIT & the IMO released MathNet, the world’s largest dataset of International Math Olympiad problems & solutions 🌍
MathNet is 5x larger than previous datasets & is sourced from over 40 countries across 4 decades: https://t.co/vvojP7Fu9t
Congratulations to the AMR @AMathRes on receiving a major donation from the Sergey Brin Family Foundation and from Michael Brin! These funds will be used to sustain and grow the AMR's diamond open access journals.
If you too value the work we're doing in open science, please donate here: https://t.co/hVosmwp9hY
Today's best AI needs orders of magnitude more data than a human child to achieve visual competence.
We introduce the Zero-shot World Model (ZWM), an approach that substantially narrows this gap. Even when trained on the first-person experience of a single child, BabyZWM matches state-of-the-art models on diverse visual-cognitive tasks – with no task-specific training, i.e., zero-shot. 🧵
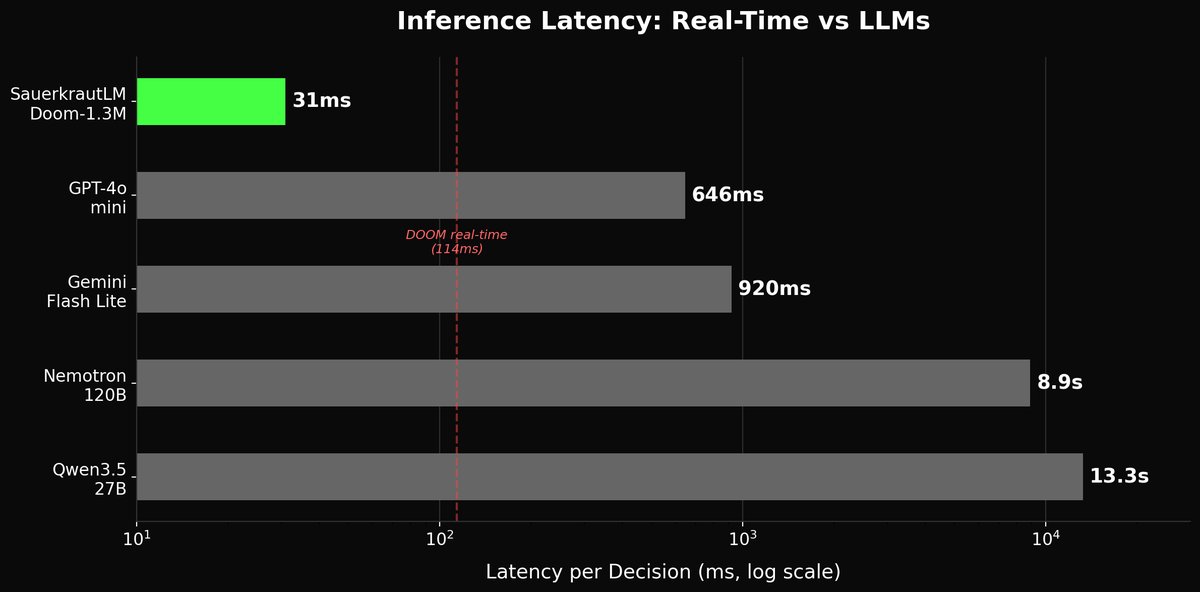
We taught a 1.3M parameter model to play DOOM. It outperforms LLMs up to 92,000x its size.
Happy Easter Monday! Here's our Easter egg release: SauerkrautLM-Doom-MultiVec-1.3M.
17.8 average points per episode.
We benchmarked our tiny model against GPT-4o-mini (via OpenAI API), Nemotron-120B, Qwen3.5-27B, and Gemini Flash Lite (via OpenRouter API) on VizDoom's defend_the_center:
- Our model: 17.8 avg points/episode, 31ms per decision, runs on CPU
- Gemini Flash Lite: 0.8 avg points/episode (920ms latency)
- Qwen3.5-27B: 0.67 avg points/episode (13.3s latency)
- Nemotron-120B: 0.6 avg points/episode (8.9s latency)
- GPT-4o-mini: 0.0 avg points/episode (just dodges, never engages)
The architecture: ModernBERT-Hash
We took hash embeddings (Svenstrup et al. 2017), previously only applied to the original BERT architecture (see @neumll 's BERT-Hash models), and brought them to ModernBERT, adding rotary position embeddings, alternating local/global attention, Flash Attention 2 support, and learned depth embeddings from VizDoom's depth buffer.
The result is a 5-layer encoder with a 75-token character-level tokenizer (no BPE, every ASCII character is one token, preserving spatial structure), attention pooling, and a 4-action classification head. Total: 1,319,300 parameters, ~5MB on disk, 31ms inference on CPU.
Trained on 31K frames of a human playing DOOM for about 2 hours. That's it.
Fully open source. Everything you need to reproduce this:
Model weights: https://t.co/bBvtlYFq2l
Training data (31K frames): https://t.co/AyEXw4mwbp
Code, training scripts, benchmark framework: https://t.co/GmPnTbQgAL
Full paper with methodology included in the repo.
Why does this matter beyond the fun factor?
Small specialized models can decisively beat general-purpose LLMs at real-time control tasks. Not by a small margin, by 22x on average points per episode. At 1/400th the latency. On a CPU. For free.
This has real implications for robotics, autonomous systems, game AI, and any domain where you need sub-100ms decisions on edge hardware. The future of AI isn't exclusively large. It's appropriately sized.
Thank you to my co-authors Daryoush Vaziri (University of Applied Sciences Bonn-Rhein-Sieg) and Alexander Marquardt (Nara Institute of Science and Technology, CARE Laboratory) for their contributions to this work.
Built with VizDoom, PyTorch, HuggingFace Transformers, and the ModernBERT architecture by @benjamin_warner , @antoine_chaffin, @ClavierBenjamin et al. Hash embedding approach inspired by NeuML's BERT-Hash models.
#AI #DOOM #GameAI #SmallModels #OpenSource #ModernBERT #SauerkrautLM #VAGOSolutions #Easter #TinyML
Today we're releasing Gemma 4, our new family of open foundation models, built on the same research and technology as our Gemini 3 series. These models set a new standard for open intelligence, offering SOTA reasoning capabilities from edge-scale (2B and 4B w/ vision/audio) up to a 26B parameter MoE model and a 31B dense model. By releasing Gemma 4 under the Apache 2.0 license, we hope to enable more innovation across the research and developer communities. Our earlier Gemma 3 models were downloaded 400M times and over 100,000 variants of those models have been published, so we're excited to see what the community will do with the even better Gemma 4 models!
Learn more at https://t.co/BW6O3Gr8bc and https://t.co/8M0XSQSP4u
Great work by everyone involved!
#Gemma4 #AI #OpenSource #ML