Just came up with a new concept while deeply thinking about a business question: Business Process Interface - BPI.
It will have common characteristics of API that lets applications talk to each other, plus "evidential cuts" that contain data to prove a process was done properly.
@JIACHENLIU8@kunalt12345 each generation tends to focus on their own problems. The current trend empowers already capable people, leaving juniors in many professionals out of focus. I'm trying to figure out too, for the sake of our future
Puzzle me these can be all true
- You have the best foundation model
- Your engineers are dogfooding extensively
- You have the best agentic tool who codes itself
- You have the too-dangerous-to-release model that can identify problems
- More than 1h to fix "complex" issues
The Jensen + @dwarkesh_sp podcast was fantastic.
Jensen is someone who understood how ecosystems work and someone who understands real-world trade, policy and controls work. And in some deeper sense how AI will actually diffuse into the world.
In this podcast, Dwarkesh came off as someone who picked up talking points from an AGI party in the SF Mission District.
And the contrast was so evident.
As someone who understood ecosystems relatively deepy, maybe I understood Jensen's take more than others did (idk).
Mythos, that Dwarkesh kept bringing up, is not a single absolute turning point in the AI development landscape. Take a state-of-the-art Chinese open-source model, and give it three orders of magnitude more test-time compute + post-training algorithmic advances that haven't been published yet. That's the baseline. It was evident that in whatever bubble Dwarkesh is in, that is seen as a naive or illogical baseline.
When AI has such a complex development cycle, it's evident that America needs many levers of policy intervention across multiple layers in a dominant ecosystem that ideally the Western world controls.
The entire premise that a particular model with AI development will have a critical phase change is neither correct nor does evidence point to it. OpenAI made this point with GPT-4, Anthropic made this point with Mythos, but neither stood / will stand the test of time.
I think Jensen's repeated emphasis within the podcast to try to make this point mostly didn't get Dwarkesh's attention. And Dwarkesh (in this podcast) represents an entire cult of AI researchers and decision-makers that are going to influence policy.
The thing with policy interventions is that if you do too much too early, you shoot yourself in the foot. There's a good reason American foreign policy and general sanctions of all kinds are measured and continuous.
Despite Jensen's attempt at educating the "Anthro" audience how ecosystems work, I'm also not super hopeful a lot of people who've taken the extreme position will change their thought after listening to this podcast. I do think there's a certain religiousness that has permeated some of that community that would make it hard to understand ecosystems at a deeper level.
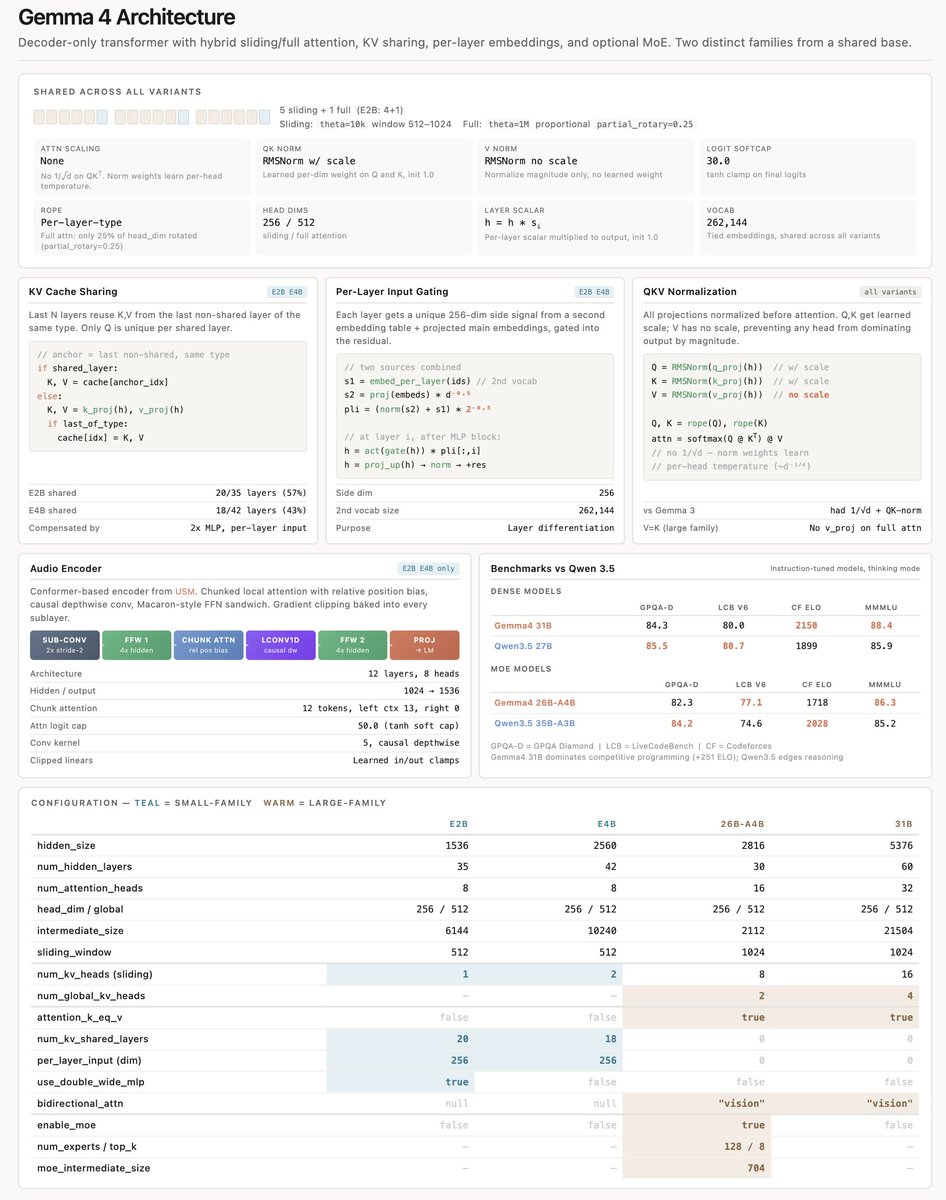
google gemma 4 architecture is very interesting and every model has some subtle differences, here is a recap:
> per layer embedding only on the small variant
> no attention scale (usually you divide qk^T by sqrt(d), they don't)
> they do QK norm + V norm as well
> they share K and V for the large variant
> they do quite aggressive KV cache sharing on the small variant
> sliding window (512 and 1024) is bigger than gpt-oss 128 and they don't use sinks!
> softcapping
> rope only on part of the dimensions + different rope theta for the local/global layer
Introducing 𝑨𝒕𝒕𝒆𝒏𝒕𝒊𝒐𝒏 𝑹𝒆𝒔𝒊𝒅𝒖𝒂𝒍𝒔: Rethinking depth-wise aggregation.
Residual connections have long relied on fixed, uniform accumulation. Inspired by the duality of time and depth, we introduce Attention Residuals, replacing standard depth-wise recurrence with learned, input-dependent attention over preceding layers.
🔹 Enables networks to selectively retrieve past representations, naturally mitigating dilution and hidden-state growth.
🔹 Introduces Block AttnRes, partitioning layers into compressed blocks to make cross-layer attention practical at scale.
🔹 Serves as an efficient drop-in replacement, demonstrating a 1.25x compute advantage with negligible (<2%) inference latency overhead.
🔹 Validated on the Kimi Linear architecture (48B total, 3B activated parameters), delivering consistent downstream performance gains.
🔗Full report:
https://t.co/u3EHICG05h
Terence Tao says AI can lower mental effort so much that the brain may stop “lifting its own weights.”
Early studies suggest reduced cognitive load can come with real harms, not just convenience.
Math is especially vulnerable because it’s easy to outsource every step to a tool.
Responsible use means choosing when to think, not just when to click, says Terence Tao.
In a recent chat with a Gemini VP regarding hiring philosophy, one trait he emphasized: the combination of low ego and high competence. We are no longer in an era defined by individual papers or claims of ownership. Success today requires a 'last mile' mindset—a relentless focus on doing whatever work is necessary to deliver world-class models. A team member who pairs high contribution with low ego simplifies and energizes the entire organization. In this hyper-competitive frontier, the delta between contribution and ego has become a key metric for identifying the talent that actually moves the needle.
Meta × TBD Lab × CMU × UChicago × UMaryland
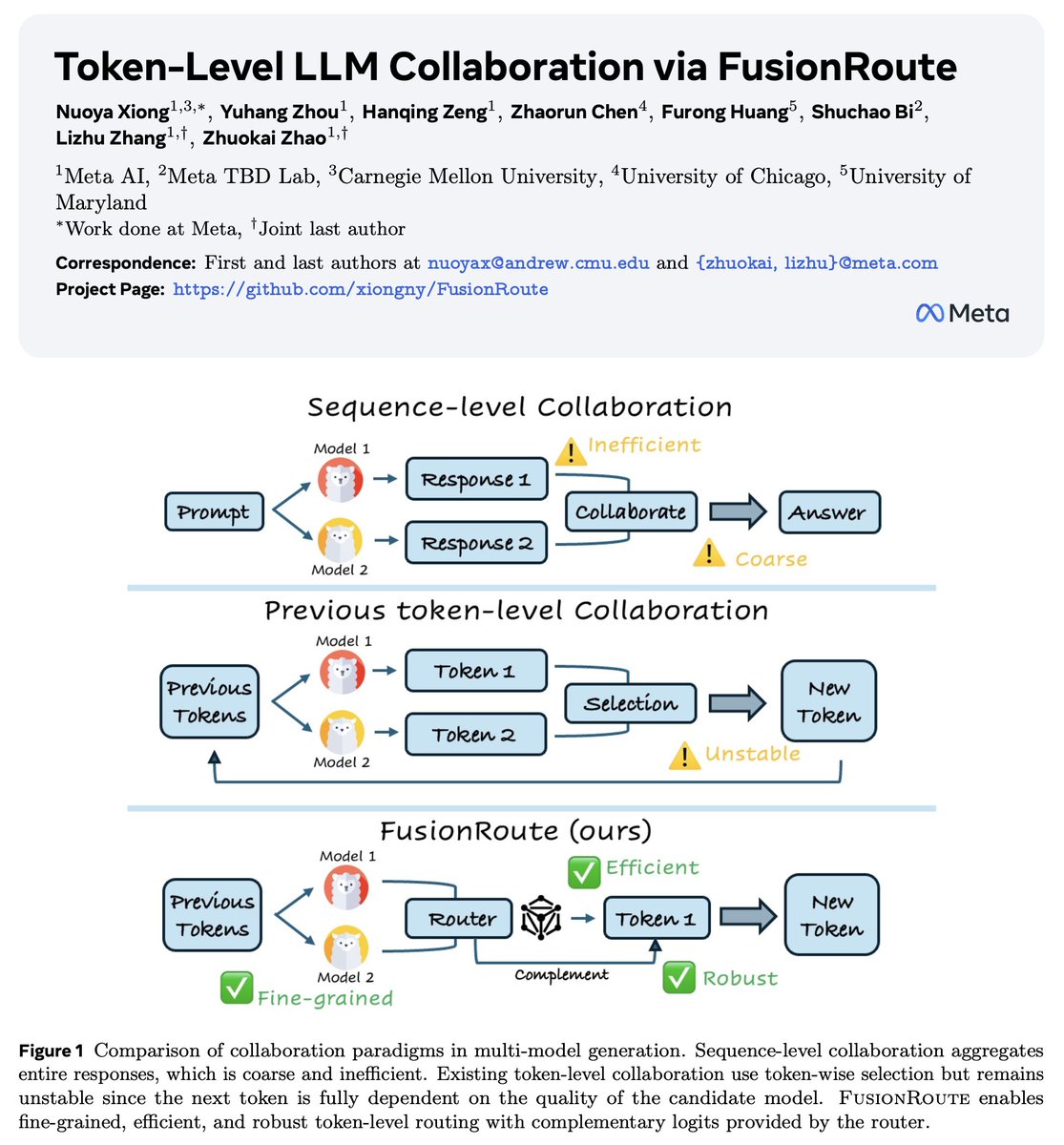
In our latest work, we introduce
Token-Level LLM Collaboration via FusionRoute
📝: https://t.co/L0bCn3yHP9
LLMs have come a long way, but we continue to face the same trade-off:
– one huge model that kind of does everything, but is expensive and inefficient, or
– many small specialist models that are cheap, but brittle outside their comfort zones
We’ve tried a lot of things in between — model merging, MoE, sequence-level agents, token-level routing, controlled decoding, etc.
Each helps a bit, but all come with real limitations.
A key realization behind FusionRoute is:
Pure token-level model selection is fundamentally limited, unless you assume unrealistically strong global coverage.
We show this formally. And then we fix it by letting the same router also generate.
Concretely, FusionRoute is a lightweight router LLM that
– performs token-level model selection, and
– directly contributes complementary logits to refine or correct the selected specialist when it fails
So it's not "routing + another model" — the router itself is part of the decoding policy as well.
This turns token-level collaboration from a brittle "pick-an-expert" problem into a strictly more expressive policy.
No joint training of specialized models.
No model merging.
No full multi-agent rollouts.
In our experiments, FusionRoute works across math, coding, instruction following, and consistently outperforms sequence-level collaboration, prior token-level methods, model merging, and even direct fine-tuning.
Feeling especially timely as LLM systems (e.g., GPT-5) move toward routing-based, heterogeneous model stacks (whether prompt-level or test-time).
Here's my enormous round-up of everything we learned about LLMs in 2025 - the third in my annual series of reviews of the past twelve months
https://t.co/HD9Zf85SG2
This year it's divided into 26 sections! This is the table of contents:
あけましておめでとうございます!いくつかAI業界の動向をまとめました。
🚀 Scaling Won’t Stop (自律性とGrounding) スケーリングは止まりません。「自律性(Autonomy)」と「Grounding(現実世界への接地)」の二つの方面で。人の介入なしにAIがどれだけ長時間タスクをこなせるか、その進化に驚くはずです。Gemini、Astra、Genie等を活用した没入型マルチモーダルアプリも標準化し、人間が認識する現実と、AIが認識・行動する世界の境界線はますます薄れていくでしょう。
📦 Products are as important as Models 優れたAIプロダクトにおける「ラストワンマイル」の仕事は、フロンティアモデルを作ることと同等に重要です。MetaによるManus買収はその価値を証明しました。AGIに貢献するなら、論文を書くだけでなく、最先端のモデルかプロダクトのどちらかで手を動かすべき。両方とも巨大な価値があります。
📈 Year of Google 2025年、Googleの株価は66%成長しました。しかし重要なのは数字そのものではなく、単発のモデルヒットに依存しない「継続的なイノベーションを生む文化」が完全に確立されたことです。(余談:1年前のNeurIPS2024で「Googleで何してるの?」と聞かれ「株価を上げてる」と答えてました)。私は2023年9月、OpenAIからGoogleに戻りましたので当時からGoogleの可能性は信じていました。あれから2年、まだ課題はあれど「勝ちパターン」に入ったと確信しています。OpenAIについては、かつて内部で対立した5〜10人の人物が既に去ったため、以前のような敵対心はありません。
🤖 Physical AI & Robotics 米国のTesla Optimus, Figure AI, Sunday Robotics, Generalist, Dyna、そして中国勢が2026年も圧倒します。ロボットの「器用さ」においてGPT-3的なモーメントが来れば、過去想像できなかった能力がアンロックされます。ただし、ハードウェア普及の壁はあるので「ChatGPTモーメント(大衆化)」はまだ先。フィジカルAIは絶対に解決はされますが、デジタルAIより時間はかかります。故に数は少ないですがロボット領域のスタートアップではSundayやMIT教授発などのトップへしかエンジェル投資はしていません。
🧠 From "Knowing" to "Learning" DeepSeek-R1からGemini 3へ。2025年はRLの年でしたが、2026年は「Continual & Sample-Efficient Learning(継続的かつサンプル効率の良い学習)」へ焦点が移ります。 「知識を持ったAI (AI that knows)」から、自ら「学習するAI (AI that learns)」へのシフトです。 私のケンブリッジでの博士論文のタイトルはまさに "Sample-Efficient Deep RL" でした。Sergey Levineらとサンプル効率について叫んでいた頃が懐かしい。2015年、AlphaGoには感動したけど、学習効率の悪さには満足してなく、人と同じ多様性と効率で学習ができないとAGIにはほど遠いと感じたところから深層学習のアルゴリズムとロボット研究に入っていきました。「人間と同じデータ効率での学習能力の学習」こそが次の焦点です。学習能力の学習もスケーリングも必要だと思うのでまだまだフロンティアラボが強いと思っています。
🇯🇵 Message to Japan 最後に、日本への率直な思いを。 日本の最大の課題は、良くも悪くも「日本が日本と日本人にしか興味がない」点にあると感じます。地理的に近い中国・韓国や東南アジアが過去の20年でどれだけ進化しているか、日本人よりも欧米のトップ層の方が遥かに詳しいのが現実です。 現代の「鎖国」状態から抜け出し、外を見ましょう。 例えば、アメリカのMetaで最も年収が高いAI研究チーム「TBD」の80%は中国人エンジニアですし、先日買収されたManusも中国系エンジニア創業です。トップレベルの現場では、国境関係なく才能が混ざり合っています。 「日本スゴイ」や「国産」という内向きな慰めではなく、明治維新のような「謙虚さ」を持ち、日本より速く動く国際社会と交わり働き、世界基準で価値を作っていくことが重要です。 世界を無視し、情報の非対称性の中に閉じこもれば、国も個人も容易に操作される側になってしまいます。
厳しいことも言いましたが、日本の底力と可能性を信じています。 2026年がAIにも日本にとっても飛躍の年になりますように。今年もよろしくお願いします。
Jensen Huang on how to structure a company:
"Don't worry about how other companies' or charts look. You start from first principles.
Remember what an organization is designed to do.
The organizations of the past where there was a king, you know, CEO, and then you have all these, you know, the royal subjects, you know, the royal court, and then e-staff.
And then you keep working your way down. Eventually, they're employees.
But the reason why it was designed that way is because they wanted the employees to have as little information as possible because the fundamental purpose of the soldiers is to die in the field of battle, to die without asking questions.
You guys know this. I only have 30,000 employees.
I would like none of them to die. I would like them to question everything.
Does that make sense?
And so the way you organize in the past and the way you organize today is very different.
Second, the question is, what does NVIDIA build?
An organization is designed so that we could build whatever it is we build better.
And so if we all build different things, why are we organized the same way?
Why would this organizational machinery be exactly the same, irrespective of what you build?
It doesn't make any sense.
You build computers, you organize this way.
You build health care services, you build the same way.
It makes no sense whatsoever.
And so you have to go back to first principles.
Just ask yourself, what kind of machinery?
What is the input? What is the output?
What are the properties of this environment?
What is the forest that this animal has to live in?
What are its characteristics?
Is it stable most of the time?
You're trying to squeeze out the last drop of water? Or is it changing all the time, being attacked by everybody?
And so you've got to understand, if you're the CEO, your job is to architect this company.
That's my first job, to create the conditions by which you can do your life's work.
And the architecture has to be right.
And so you have to go back to first principles and think about those things.
And I was fortunate that when I was 29 years old, I had the benefit of taking a step back and asking myself, how would I build this company for the future, and what would it look like?
And what's the operating system, which is called culture?
What kind of behavior do we encourage, enhance?
And what do we discourage and not enhance? So on and so forth..."
Waymo's system, fueled by careful collection of a large volume of fully autonomous data, is the most advanced, large-scale application of embodied AI today. Very proud to see this level of engineering rigor tackling safe autonomous driving making the roads safer for everyone (and it has been nice to see various Google research collaborations with Waymo be a part of these advances!).
The insights here are foundational for how we design and safely scale all complex AI systems.
Read more at:
https://t.co/TFk9yv6rce
We just built and released the largest dataset for supervised fine-tuning of agentic LMs, 1.27M trajectories (~36B tokens)!
Up until now, large-scale SFT for agents is rare - not for lack of data, but because of fragmentation across heterogeneous formats, tools, and interfaces.
To solve this, we introduce the Agent Data Protocol, a new “interlingua” between a broad variety of heterogeneous agent datasets - coding, browsing, API/tool use - and unified agent training pipelines downstream.
We unified 13 datasets into ADP, converted them to be compatible with multiple agent frameworks, and observed ~20% average gains, reaching SOTA/near-SOTA without domain-specific tuning.
📄 Read our paper: https://t.co/OlCTvhrXQ7
🌐 Check our project website: https://t.co/wBggu0hQ2i
And this is just getting started, we can add more datasets, further expand the resources, and make training agent LMs easy for all. We’d love to have you join the shared effort and help to make ADP the open standard for the community 🚀
My pleasure to come on Dwarkesh last week, I thought the questions and conversation were really good.
I re-watched the pod just now too. First of all, yes I know, and I'm sorry that I speak so fast :). It's to my detriment because sometimes my speaking thread out-executes my thinking thread, so I think I botched a few explanations due to that, and sometimes I was also nervous that I'm going too much on a tangent or too deep into something relatively spurious. Anyway, a few notes/pointers:
AGI timelines. My comments on AGI timelines looks to be the most trending part of the early response. This is the "decade of agents" is a reference to this earlier tweet https://t.co/NiSn6jftqq Basically my AI timelines are about 5-10X pessimistic w.r.t. what you'll find in your neighborhood SF AI house party or on your twitter timeline, but still quite optimistic w.r.t. a rising tide of AI deniers and skeptics. The apparent conflict is not: imo we simultaneously 1) saw a huge amount of progress in recent years with LLMs while 2) there is still a lot of work remaining (grunt work, integration work, sensors and actuators to the physical world, societal work, safety and security work (jailbreaks, poisoning, etc.)) and also research to get done before we have an entity that you'd prefer to hire over a person for an arbitrary job in the world. I think that overall, 10 years should otherwise be a very bullish timeline for AGI, it's only in contrast to present hype that it doesn't feel that way.
Animals vs Ghosts. My earlier writeup on Sutton's podcast https://t.co/rSp1noyGBr . I am suspicious that there is a single simple algorithm you can let loose on the world and it learns everything from scratch. If someone builds such a thing, I will be wrong and it will be the most incredible breakthrough in AI. In my mind, animals are not an example of this at all - they are prepackaged with a ton of intelligence by evolution and the learning they do is quite minimal overall (example: Zebra at birth). Putting our engineering hats on, we're not going to redo evolution. But with LLMs we have stumbled by an alternative approach to "prepackage" a ton of intelligence in a neural network - not by evolution, but by predicting the next token over the internet. This approach leads to a different kind of entity in the intelligence space. Distinct from animals, more like ghosts or spirits. But we can (and should) make them more animal like over time and in some ways that's what a lot of frontier work is about.
On RL. I've critiqued RL a few times already, e.g. https://t.co/mYrMFVdVDW . First, you're "sucking supervision through a straw", so I think the signal/flop is very bad. RL is also very noisy because a completion might have lots of errors that might get encourages (if you happen to stumble to the right answer), and conversely brilliant insight tokens that might get discouraged (if you happen to screw up later). Process supervision and LLM judges have issues too. I think we'll see alternative learning paradigms. I am long "agentic interaction" but short "reinforcement learning" https://t.co/2L7FiaoKsw. I've seen a number of papers pop up recently that are imo barking up the right tree along the lines of what I called "system prompt learning" https://t.co/df5mJDdN3C , but I think there is also a gap between ideas on arxiv and actual, at scale implementation at an LLM frontier lab that works in a general way. I am overall quite optimistic that we'll see good progress on this dimension of remaining work quite soon, and e.g. I'd even say ChatGPT memory and so on are primordial deployed examples of new learning paradigms.
Cognitive core. My earlier post on "cognitive core": https://t.co/q2s1ihGy0T , the idea of stripping down LLMs, of making it harder for them to memorize, or actively stripping away their memory, to make them better at generalization. Otherwise they lean too hard on what they've memorized. Humans can't memorize so easily, which now looks more like a feature than a bug by contrast. Maybe the inability to memorize is a kind of regularization. Also my post from a while back on how the trend in model size is "backwards" and why "the models have to first get larger before they can get smaller" https://t.co/6k0FZRGXsb
Time travel to Yann LeCun 1989. This is the post that I did a very hasty/bad job of describing on the pod: https://t.co/fQgqaXPyp6 . Basically - how much could you improve Yann LeCun's results with the knowledge of 33 years of algorithmic progress? How constrained were the results by each of algorithms, data, and compute? Case study there of.
nanochat. My end-to-end implementation of the ChatGPT training/inference pipeline (the bare essentials) https://t.co/SIetgyoKWN
On LLM agents. My critique of the industry is more in overshooting the tooling w.r.t. present capability. I live in what I view as an intermediate world where I want to collaborate with LLMs and where our pros/cons are matched up. The industry lives in a future where fully autonomous entities collaborate in parallel to write all the code and humans are useless. For example, I don't want an Agent that goes off for 20 minutes and comes back with 1,000 lines of code. I certainly don't feel ready to supervise a team of 10 of them. I'd like to go in chunks that I can keep in my head, where an LLM explains the code that it is writing. I'd like it to prove to me that what it did is correct, I want it to pull the API docs and show me that it used things correctly. I want it to make fewer assumptions and ask/collaborate with me when not sure about something. I want to learn along the way and become better as a programmer, not just get served mountains of code that I'm told works. I just think the tools should be more realistic w.r.t. their capability and how they fit into the industry today, and I fear that if this isn't done well we might end up with mountains of slop accumulating across software, and an increase in vulnerabilities, security breaches and etc. https://t.co/8556ESSpyY
Job automation. How the radiologists are doing great https://t.co/FVUI872dkD and what jobs are more susceptible to automation and why.
Physics. Children should learn physics in early education not because they go on to do physics, but because it is the subject that best boots up a brain. Physicists are the intellectual embryonic stem cell https://t.co/p72Elk8lPV I have a longer post that has been half-written in my drafts for ~year, which I hope to finish soon.
Thanks again Dwarkesh for having me over!
The most surprising thing working on this was that RL with LoRA completely matches full training and develops the same extended reasoning patterns. I think this is a great sign for custom agent training.
Today Thinking Machines Lab is launching our research blog, Connectionism. Our first blog post is “Defeating Nondeterminism in LLM Inference”
We believe that science is better when shared. Connectionism will cover topics as varied as our research is: from kernel numerics to prompt engineering. Here we share what we are working on and connect with the research community frequently and openly.
The name Connectionism is a throwback to an earlier era of AI; it was the name of the subfield in the 1980s that studied neural networks and their similarity to biological brains.
https://t.co/lrJioBmpbT
Now some of the downsides of my experience with "vibe-coding for serious work".
First, recap the good sides I mentioned previously: it's amazing at quick prototyping things, making tiny throw-away hyper-specialized demos, taking care of boilerplate, setup, and writing tests for me.
Now the bad part: the code it generates is insanely verbose, overly defensive, bloated, and sometimes plain dumb. The models (I tried Claude code 4 and Codex Gpt5) have two big issues:
1) The model fully trusts you and takes what you say to the extreme. If you mention a requirement, it applies it to everything like a pedant, even if that forces quite insane contortion. A real good human coder would be like "ok wait, but this will make things extremely convoluted for XYZ, do you really mean this to apply here too?" and the answer is most likely "no, I didn't intend that"
2) The model never takes a step back and reconsiders/refactors things. It loves piling shit on top of more shit. A good human programmer would suddenly go "ok, that's a lot, let's simplify/unify things here for a bit". Even if you ask the model to do this, it usually sucks at simplifying.
Two concrete real-life examples I had:
1) I had some pytorch distributed issue where some gathers in a library of mine would sometimes hang or die out of sync. Claude correctly identified that the process group was not always correctly initialized. So it started writing hundreds of lines of bookkeeping boilerplate to my library to try fixing this (and eventually did fix). After I looked at its fix, I immediately notice that the real fix was just moving my library's init call after torch distributed init, not before🤦♂️ So the real fix involved not a single new line of code, but Claude loves writing more lines!
2) In another library I made rapid iterations with Codex on the design. The core of the library boils down to a kind of graph where you need to walk through the nodes and do work on a node, while stopping on loops. Codex did correctly implement it, and it works; however, it wrote very convoluted code for the core logic, about 200 lines of code with two functions recursing into each other, and a few stacks and queues for traversal bookkeeping.
After looking at it and taking a step back, I rewrote the whole thing from scratch in maybe 40 clear lines of code. It was great having Codex's extensive unit-tests to see that my rewrite is correct.
So, in conclusion, the current state of vibe-coding is good for boilerplate, rapid iteration/prototyping, or one-off throwaway tools. For code that you intend to use, keep, extend, maintain for a while, you're always better off (re)writing it by hand.
Maybe only after the LLM-assisted exploration and unit-test writing, though!
Attention is all you need - but how does it work? In our new paper, we take a big step towards understanding it. We developed a way to integrate attention into our previous circuit-tracing framework (attribution graphs), and it's already turning up fascinating stuff! 🧵