和@sainingxie 一起挑战7小时播客!他刚和Yann LeCun踏上“世界模型”的创业旅程(AMI Labs)。这是他第一次Podcast、第一次访谈。
2026年2月雪后的一天,我们在纽约布鲁克林,从下午2点,开启了一场始料未及的马拉松式访谈,直到凌晨时分散去。
这篇访谈的中文标题叫做《逃出硅谷》,但他又不厌其烦地枚举了影响他学术生涯的每一个人,并反反复复口头描摹这些人的人物特征(侯晓迪、何恺明、杨立昆、李飞飞…)正是这些,让这篇“逃出硅谷”的对话充斥着人性的温度。
By the way, 下面是访谈的YouTube版本,我们提供了中英字幕。
And yes, 我们是在用播客给这个世界建模😎
A 7-hour podcast with Saining Xie. He has just begun a new journey on world models with Yann LeCun at AMI Labs.
This was his first podcast appearance and his first long-form interview.
A day after the snowfall in February 2026, in Brooklyn, New York, we started recording at 2 p.m. What followed became an unexpected marathon conversation that lasted until the early hours of the morning.
The Chinese title of the interview is “Escaping Silicon Valley.” Yet throughout the conversation, he patiently listed the people who shaped his academic life, repeatedly sketching their personalities in vivid detail: Hou Xiaodi, Kaiming He, Yann LeCun, Fei-Fei Li, and others. These portraits are what give this “escape from Silicon Valley” conversation its human warmth.
By the way, the YouTube version of the interview is below, with Chinese and English subtitles.
And yes, we are using podcasts to model the world 😎
A 7-hour marathon interview with Saining Xie: World Models, AMI Labs, Ya... https://t.co/3rTwdTGkJI 来自 @YouTube
@zzlccc While training Qwen2.5-VL (SFT/GRPO), I noticed bfloat16-trained models yield garbled or mixed Chinese-English output when inferred in float32, whereas float16-trained ones work fine.
This training-inference dtype mismatch is critical—thanks for highlighting it!
Introducing Qwen3!
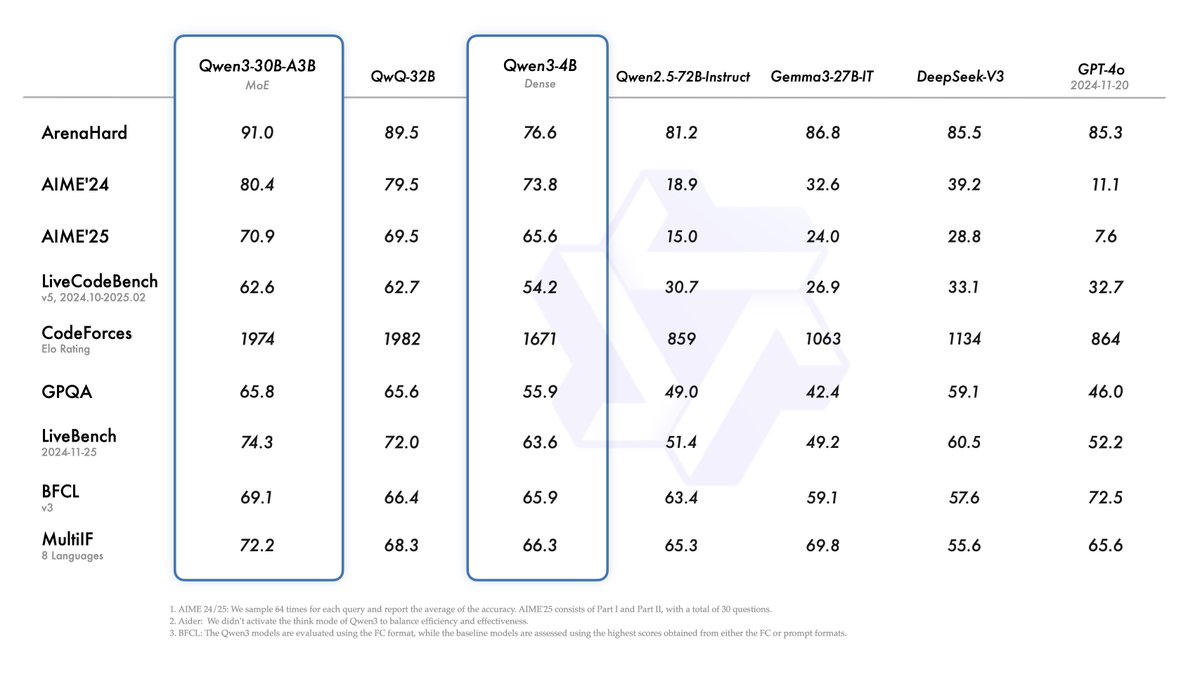
We release and open-weight Qwen3, our latest large language models, including 2 MoE models and 6 dense models, ranging from 0.6B to 235B. Our flagship model, Qwen3-235B-A22B, achieves competitive results in benchmark evaluations of coding, math, general capabilities, etc., when compared to other top-tier models such as DeepSeek-R1, o1, o3-mini, Grok-3, and Gemini-2.5-Pro. Additionally, the small MoE model, Qwen3-30B-A3B, outcompetes QwQ-32B with 10 times of activated parameters, and even a tiny model like Qwen3-4B can rival the performance of Qwen2.5-72B-Instruct.
For more information, feel free to try them out in Qwen Chat Web (https://t.co/bg4tAU1p74) and APP and visit our GitHub, HF, ModelScope, etc.
Blog: https://t.co/Z8YgHerTXz
GitHub: https://t.co/Ij0Vne5b5K
Hugging Face: https://t.co/V1WxhQ0fad
ModelScope: https://t.co/Z9Z37FODVN
The post-trained models, such as Qwen3-30B-A3B, along with their pre-trained counterparts (e.g., Qwen3-30B-A3B-Base), are now available on platforms like Hugging Face, ModelScope, and Kaggle. For deployment, we recommend using frameworks like SGLang and vLLM. For local usage, tools such as Ollama, LMStudio, MLX, llama.cpp, and KTransformers are highly recommended. These options ensure that users can easily integrate Qwen3 into their workflows, whether in research, development, or production environments.
Hope you enjoy our new models!
My nuanced views on AI alignment are still often caricatured, so perhaps its a good time to repost this 15-minute talk in which I presented them directly: https://t.co/dxgnaXaisp
The short version is that I don't agree with AI-safety folks about what question we should be asking. Rather than asking how we can control the goals of the AIs, I think we should be asking how we can have a good future without controlling their goals (just as we have a pretty good present without controlling other peoples' goals). @steve47285
Thrilled to know that our paper, `Safety Alignment Should be Made More Than Just a Few Tokens Deep`, received the ICLR 2025 Outstanding Paper Award.
We sincerely thank the ICLR committee for awarding one of this year's Outstanding Paper Awards to AI Safety / Adversarial ML. Special thanks go to the reviewers and area chairs for their strong support and recommendations. Throughout the rebuttal period, the reviewers remained deeply engaged, raising thoughtful questions that helped enhance the rigor of our experiments and manuscript. I am also profoundly grateful to my collaborators (@PandaAshwinee@vfleaking@infoxiao@sroy_subhrajit@abeirami) for their joint efforts and my advisors (@prateekmittal_@PeterHndrsn) for their invaluable guidance and support.
+ On a personal note, I also defended my PhD at Princeton in February and joined OpenAI last month, where I will continue working on AI safety and adversarial robustness. I'm looking forward to catching up with old friends and meeting new friends around the Bay!)
------
Below are some of my reflections and thoughts on our awarded paper:
Adversarial robustness has been an ongoing topic since the early rise of deep learning in 2013 (https://t.co/Squ5sX8GCz). Over the years, we've observed the community swing from pessimism—epitomized by Nicholas Carlini's adaptive attacks (https://t.co/EE9O5aLcRd) systematically dismantling various defenses, fostering the sentiment "adversarial examples are hard"—to skepticism, as adversarial examples appeared to have limited impact on practical AI applications for a while, prompting the notion "adversarial examples are not even important."
With the emergence of ChatGPT at the end of 2022, deep learning entered a new era towards AGI, shifting AI safety from theoretical speculation to mainstream practical concern. This is also when adversarial robustness again gets more attention. For example, following our 2023 demonstrations that adversarial examples pose fundamental threats to AI safety alignment (https://t.co/WZM7wfYqa3, https://t.co/g7IQA8D1nY, https://t.co/e5jOcIvFzU), adversarial examples reemerged as the "Sword of Damocles" hanging over AI safety (memorably illustrated by Zico Kolter at ICML 2023 in Hawaii, who humorously preempted his talk on the GCG attack with a Terminator slide captioned, "adversarial examples are back"). More concerningly, in the context of AI safety, disrupting safety alignment through fine-tuning is even simpler and harder to mitigate than adversarial examples (https://t.co/P9o5KGH9mM, https://t.co/2D0HYXcnCb, https://t.co/gH8wW6Nx9V, https://t.co/PK1nlICXzo, https://t.co/jrqD8XQfxB).
In 2023, conducting attack research was enjoyable—simply formulating and demonstrating the existence of vulnerabilities sufficed, as the effectiveness of an attack is inherently compelling. However, in 2024, my advisors started to heavily push me toward working on robustness defense, asserting that identifying problems without striving for solutions is not ambitious enough. While I wholeheartedly agreed, I was acutely aware of the profound challenge in achieving genuine robustness. After a lot of struggle, we eventually still developed this paper. Initially, our exploration focused on constrained supervised fine-tuning (SFT) against fine-tuning attacks. During this process, we discovered a critical bias—models exhibit substantial "first-few-tokens bias" concerning safety (here we acknowledge similar findings by https://t.co/irDKwTmsNb and https://t.co/ZceJPx37yg, despite differences in our ultimate directions). Using this bias as a technical trick, we impose strong constraints on the losses of only the initial tokens, relaxing constraints for later tokens. This achieved robustness with significantly lower utility regression. Nevertheless, we soon recognized that this bias is not merely a technical trick but represents a fundamental issue. Consequently, we shifted our focus to exploring the broader implications of this phenomenon itself, ultimately shaping the current paper. In writing this paper, I intentionally echoed the style of two seminal works: "Adversarial Examples Are Not Bugs, They Are Features" (https://t.co/lOmPqbo6B3) and "Shortcut Learning in Deep Neural Networks" (https://t.co/IdeWjpNygQ). The two papers deeply influenced my research style, and receiving the Outstanding Paper award at the culmination of my PhD journey, using a similar writing style, feels both fulfilling and like a tribute to these classics.
Frankly, our work still stands far from fully resolving adversarial robustness. In fact, during writing, we deliberately reduced/avoided using the term "defense," resulting in some critique that our paper reads more like a position paper. Rather, our contribution primarily provides just a simple yet concrete explanation (shallow alignment) for a broadly exploited class of vulnerabilities, enabling causal interventions on models to explore the counterfactual of shallow alignment—deep alignment—and demonstrating that such interventions genuinely improve robustness. Fundamentally, our intervention underscores that model alignment must span the entire generation process rather than being confined to the first few token distributions—a principle articulated explicitly in our paper's title. This concept resonates with several other studies, such as Andy Zou et al.’s Circuit Breakers (https://t.co/ul9h7tWVXC), Youliang Yuan et al.’s refusal at every position (https://t.co/DEOBQpOF3i), and Yiming Zhang et al.’s backtracking (fri). To some extent, improved robustness in reasoning models’ safety alignment (https://t.co/F4fNc7BLOu) might also be related to this principle, as large-scale reinforcement learning for reasoning spontaneously enhances self-correction and recovery.
Yet, adversarial robustness remains unresolved. Adaptive attacks will continuously emerge, potentially perpetuating many cycles of a cat-and-mouse game again. Furthermore, our challenges extend beyond AI safety and jailbreak issues. As frontier models rapidly advance in agentic capabilities, we eagerly anticipate their large-scale deployment to automate numerous tasks. However, currently, robustness and prompt injection significantly hinder this vision. As AI increasingly manages critical workloads and computational systems, robustness failures could pose severe systemic security risks.
Finally, we again extend our sincere appreciation to all friends in the AI safety and AdvML research communities for their ongoing support and encouragement. Let’s continue working together to advance the research on AI safety and adversarial machine learning.
@xiangyuqi_pton Well-deserved!🎆 Additionally, thank you for providing these valuable insights, especially that the expected deep alignment can be understood as 'enabling causal interventions on models to explore the counterfactual of shallow alignment.
@natolambert I think Hinton just wants to emphasize that "standard RLHF techniques that lead to shallow/superficial alignment are not enough to ensure the safety". We indeed need to explore more robust and trustworthy alignment techniques beyond the standard RLHF.
Thanks for the interest - it was a pleasure talking at @GoogleDeepMind on Implicit PRM and PRIME. Special thanks to @ChenSun92 for hosting me!
Slides are available here:
https://t.co/vl8EYrpOwY
The DeepSeek R1 recipe, what questions we need to answer to train an o1 replication ourselves at home, and what it means for the near future of AI.
https://t.co/pDpIzlvhNi
Happy New Year! On the last day of 2024, I want to take a moment to reflect on what’s ahead in 2025. I don’t want to talk about buzzwords like "agents", instead, I’d like to summarize my thoughts with three keywords: Interactivity, Efficiency, and Humans.
- Interactivity: O1&3 are far from AGI as they only represent inner thoughts and can solve a very limited subset of real-world tasks. In contrast, most tasks require actual interaction with environments and real-time feedback. How can we make LLMs natively interactive? By natively, I mean without embedding them in an “agentic” framework. While the framework might be agentic, the LLMs themselves are not. To address this, LLMs need inner memory, inner feedback, and mechanisms to process new observations and make sequential decisions. I rarely see work addressing this. Achieving this will go beyond pre-training (which will end as we know) and instead require learning through direct interactions.
- Efficiency: While not a new direction, 2025 will be a turning point. Scaling has hit a wall—blindly increasing model and data sizes has reached the last part of the saturation curve. In addition to academia, major industry players in LLMs will (if they haven’t already) heavily invest in learning knowledge and skills more efficiently during both training and inference. This involves using higher-quality data and achieving greater results with fixed parameter sizes rather than relying on brute-force scaling. It is no longer the case we have to work on efficiency due to limited resources; it is the case we need to work on it to break the scaling bottleneck and bring LLMs to another level.
- Humans: This is not just about alignment. Aligning models with humans seems intuitive and appealing, but is it the right approach? Models and humans work very differently, even if training methods are inspired by so-called “cognitive” or “biological” ideas. On a behavioral level, aligning models to serve human purposes makes sense. However, in terms of their working mechanisms, models have their own processes, and counterintuitive ideas may be the most effective. For example, instead of feeding RGB images into self-driving cars, Tesla uses raw information, bypassing camera processing to preserve more data. Most importantly, in 2025, we need to focus on studying the differences—not just the similarities—between humans and models. This will help models better complement human abilities, or vice versa (which is more practical for new AI users). Remember, even if AGI is achieved, it will most likely differ fundamentally from human intelligence.
That’s it. I wanted to write this down after a wonderful New Year’s Eve dinner and a few drinks. I may elaborate more on these thoughts when I get the chance.
@tuzhaopeng Interesting and great Work!👍
Mitigating overthinking in reasoning is indeed important for improving the performance and efficiency of reasoning systems. We explored similar issues in our work published in EMNLP 2024.
https://t.co/KNllb7pOmL