One paper got accepted at CVPR!
Learning Coordinate-based Convolutional Kernels for Continuous SE(3) Equivariant and Efficient Point Cloud Analysis
Jaein Kim, Hee Bin Yoo, Dong-Sig Han, Byoung-Tak Zhang
Variational Online Mirror Descent for Robust Learning in Schrödinger Bridge
Dong-Sig Han, Jaein Kim, HEE BIN YOO, Byoung-Tak Zhang.
Action editor: Chris Maddison.
https://t.co/DbCzZSwwHG
#schrödinger#variational#wasserstein
Today OpenAI announced o3, its next-gen reasoning model. We've worked with OpenAI to test it on ARC-AGI, and we believe it represents a significant breakthrough in getting AI to adapt to novel tasks.
It scores 75.7% on the semi-private eval in low-compute mode (for $20 per task in compute ) and 87.5% in high-compute mode (thousands of $ per task). It's very expensive, but it's not just brute -- these capabilities are new territory and they demand serious scientific attention.
Most works in offline RL focus on learning better value functions. So value learning is the main bottleneck in offline RL... right?
In our new paper, we show that this is *not* the case in general!
Paper: https://t.co/1lsLPxrdR9
Blog post: https://t.co/BYXKEb49hO
A thread ↓
The heat equation can be applied to diffuse a function on a surface, but it can also be applied to evolve the surface itself. https://t.co/DvBR583hza https://t.co/Xy3Xanvvdq
There are two ways to differentiate a function over the space of measures: vertically (Euclidean) and horizontally (Wasserstein). These correspond to locally modifying the mass amplitude and positions, respectively. The Wasserstein derivative is the usual (pointwise) gradient of the Euclidean derivative.
🔥Breaking News from Chatbot Arena
@AnthropicAI Claude 3.5 Sonnet has just made a huge leap, securing the #1 spot in Coding Arena, Hard Prompts Arena, and #2 in the Overall leaderboard.
New Sonnet has surpassed Opus at 5x the lower cost and competitive with frontier models GPT-4o/Gemini 1.5 Pro across the boards.
Huge congrats to @AnthropicAI for this incredible milestone! Can't wait to see the new Opus & Haiku. Our new vision leaderboard is also coming soon!
(More analysis below)
This is a great paper. LLMs cannot plan and reason on their own -- they're pattern-matchers. But that doesn't mean they can't be useful for reasoning. They work best *in conjunction* with systems that can actually plan or reason -- such as symbolic planners.
Oldies but goldies: R Jordan, D Kinderlehrer, F Otto, The Variational Formulation of the Fokker-Planck Equation. Showed that the heat equation is the Optimal Transport flow (i.e., the flow of particle systems) minimizing the Shannon-Boltzmann entropy. More general entropies lead to non-linear PDEs. Opened a whole field of research. https://t.co/pUDxIZc1AJ
lol at Apple sneaking this RLHF gem into their "Apple foundation models" blog post and no one talked about it
"We have developed two novel algorithms in post-training: (1) a rejection sampling fine-tuning algorithm with teacher committee, and (2) a reinforcement learning from human feedback (RLHF) algorithm with mirror descent policy optimization and a leave-one-out advantage estimator. We find that these two algorithms lead to significant improvement in the model’s instruction-following quality."
What it means tomorrow in @interconnectsai
📽️ New 4 hour (lol) video lecture on YouTube:
"Let’s reproduce GPT-2 (124M)"
https://t.co/QTUdu8b0qh
The video ended up so long because it is... comprehensive: we start with empty file and end up with a GPT-2 (124M) model:
- first we build the GPT-2 network
- then we optimize it to train very fast
- then we set up the training run optimization and hyperparameters by referencing GPT-2 and GPT-3 papers
- then we bring up model evaluation, and
- then cross our fingers and go to sleep.
In the morning we look through the results and enjoy amusing model generations. Our "overnight" run even gets very close to the GPT-3 (124M) model. This video builds on the Zero To Hero series and at times references previous videos. You could also see this video as building my nanoGPT repo, which by the end is about 90% similar.
Github. The associated GitHub repo contains the full commit history so you can step through all of the code changes in the video, step by step.
https://t.co/BOzkxQ8at2
Chapters.
On a high level Section 1 is building up the network, a lot of this might be review. Section 2 is making the training fast. Section 3 is setting up the run. Section 4 is the results. In more detail:
00:00:00 intro: Let’s reproduce GPT-2 (124M)
00:03:39 exploring the GPT-2 (124M) OpenAI checkpoint
00:13:47 SECTION 1: implementing the GPT-2 nn.Module
00:28:08 loading the huggingface/GPT-2 parameters
00:31:00 implementing the forward pass to get logits
00:33:31 sampling init, prefix tokens, tokenization
00:37:02 sampling loop
00:41:47 sample, auto-detect the device
00:45:50 let’s train: data batches (B,T) → logits (B,T,C)
00:52:53 cross entropy loss
00:56:42 optimization loop: overfit a single batch
01:02:00 data loader lite
01:06:14 parameter sharing wte and lm_head
01:13:47 model initialization: std 0.02, residual init
01:22:18 SECTION 2: Let’s make it fast. GPUs, mixed precision, 1000ms
01:28:14 Tensor Cores, timing the code, TF32 precision, 333ms
01:39:38 float16, gradient scalers, bfloat16, 300ms
01:48:15 torch.compile, Python overhead, kernel fusion, 130ms
02:00:18 flash attention, 96ms
02:06:54 nice/ugly numbers. vocab size 50257 → 50304, 93ms
02:14:55 SECTION 3: hyperpamaters, AdamW, gradient clipping
02:21:06 learning rate scheduler: warmup + cosine decay
02:26:21 batch size schedule, weight decay, FusedAdamW, 90ms
02:34:09 gradient accumulation
02:46:52 distributed data parallel (DDP)
03:10:21 datasets used in GPT-2, GPT-3, FineWeb (EDU)
03:23:10 validation data split, validation loss, sampling revive
03:28:23 evaluation: HellaSwag, starting the run
03:43:05 SECTION 4: results in the morning! GPT-2, GPT-3 repro
03:56:21 shoutout to llm.c, equivalent but faster code in raw C/CUDA
03:59:39 summary, phew, build-nanogpt github repo
Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality
Presents Mamba-2, which outperforms Mamba and Transformer++ in both perplexity and wall-clock time
https://t.co/Sd3J3kPG5W
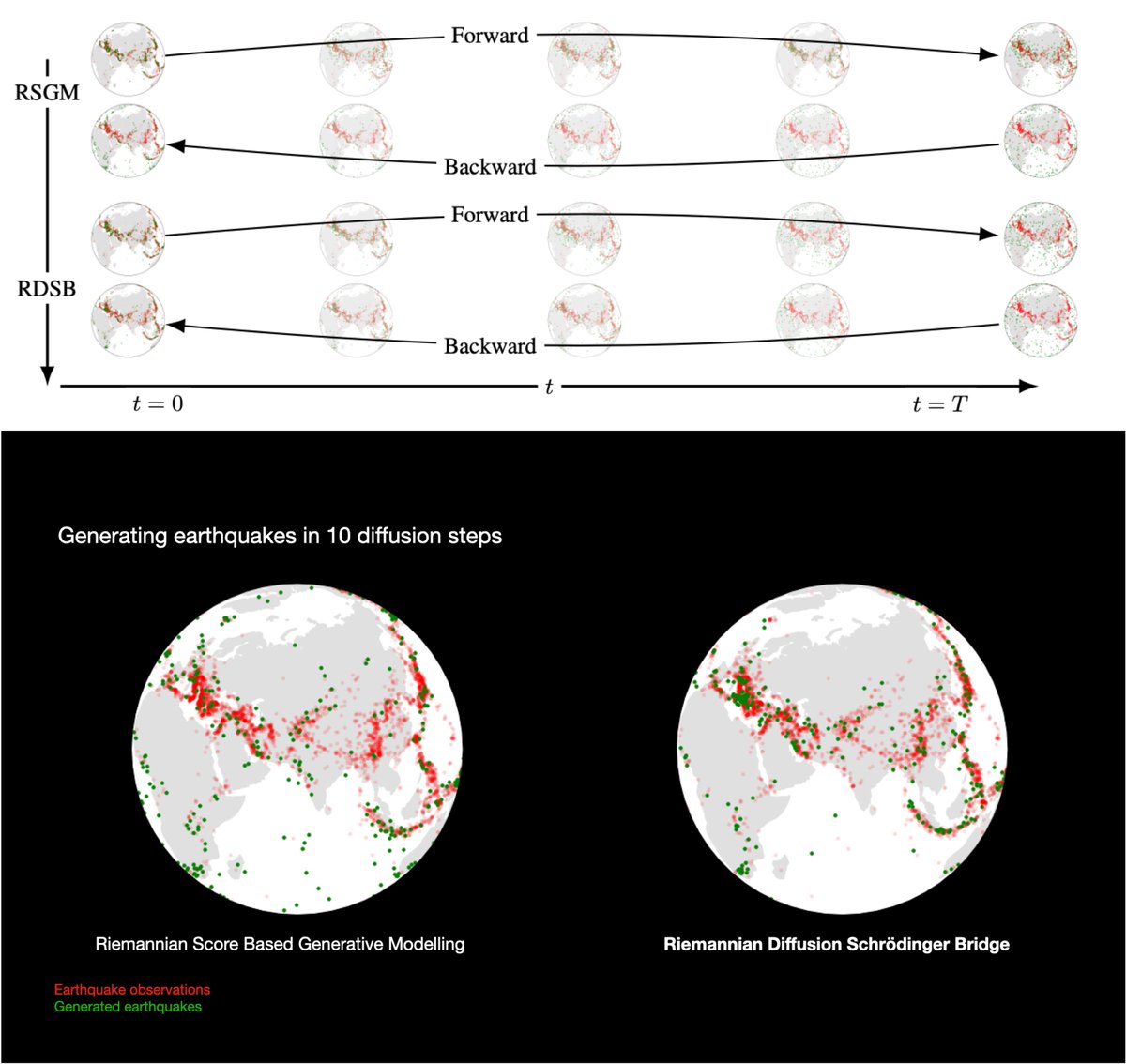
For fellow bridge enthusiasts, check out an extension we carved out from the main based on iterative time reversals - Riemannian Diffusion Schrodinger Bridge
- Accelerates Riemannian diffusions models
- Facilities interpolation based on optimal transport
https://t.co/NWcptBSPup
Gradient Langevin dynamics generate samples from densities against the Lebesgue measure. What about densities against the Wiener measure (law of Brownian)? This is more tricky, but it can be done! Here's an example solving a "trajectory inference" problem. https://t.co/aoH7755Gxs
It is great to be at #NeurIPS2022! There are many papers that I would use in future research.
I am also grateful that many people visited our posters yesterday.
Thursday at 11 AM (CST), M.I.D. will be presented in Hall J from 11 AM to 1 PM. Look forward to seeing you! 🙌
"Mutual Information Divergence: A Unified Metric for Multimodal Generative Models"
Hall J #900
https://t.co/tbw7z2lBja