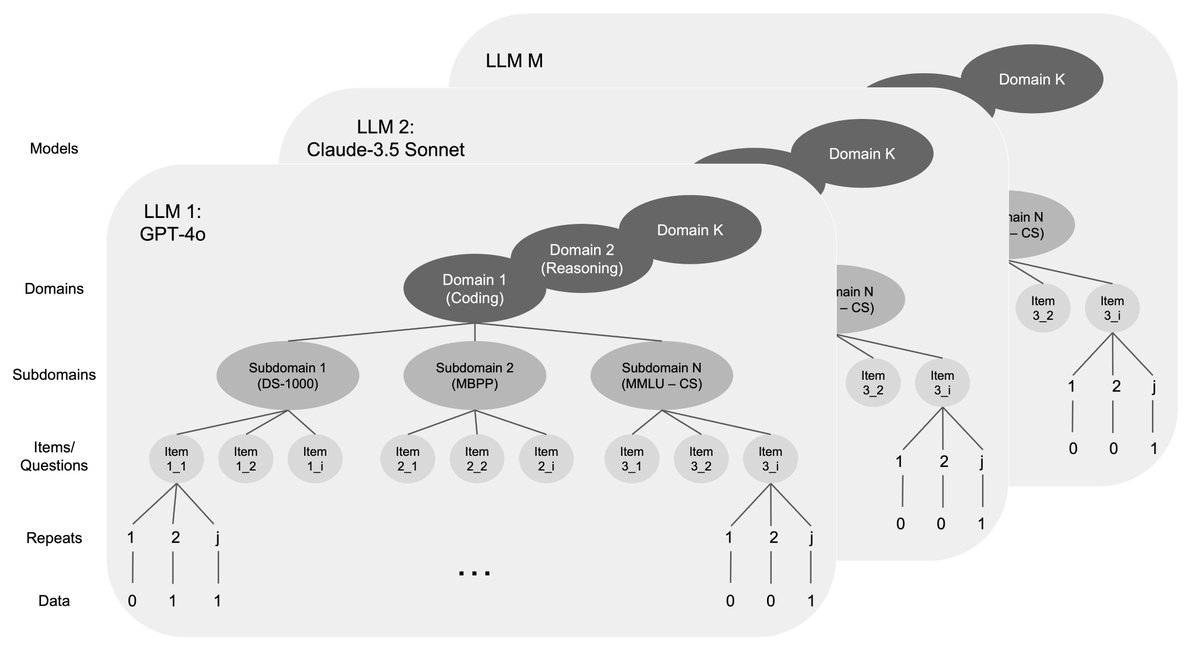
New from the Science of Evaluation Team at @AISafetyInst: a pipeline for rigorous transcript analysis.
I think transcript analysis is still underrated, especially as model horizons are getting longer and task environments more complex.
Why does horizon length grow exponentially as shown in the METR plot?
Our new paper investigates this by isolating the execution capabilities of LLMs.
Here's why you shouldn't be fooled by slowing progress on typical short-task benchmarks... 🧵
We're excited to announce the Call for Papers for SaTML 2026, the premier conference on secure and trustworthy machine learning @satml_conf
We seek papers on secure, private, and fair learning algorithms and systems.
👉 https://t.co/cPFitlsXu2
⏰ Deadline: Sept 24
Hawthorne effect describes how study participants modify their behavior if they know they are being observed
In our paper 📢, we study if LLMs exhibit analogous patterns🧠
Spoiler: they do⚠️
🧵1/n
In a new paper, we examine recent claims that AI systems have been observed ‘scheming’, or making strategic attempts to mislead humans. We argue that to test these claims properly, more rigorous methods are needed.
Evaluating AI models is essential for improving their performance and understanding their risks.
Increasingly, researchers are using “autograders” – having Large Language Models (LLMs) grade model outputs.
But how do we know if these autograders are reliable? 🧵
New paper introducing a framework to better quantify uncertainty in LLM evaluations (led by @LLuettgau🙌). A beta Python package (developed by @HarryCoppock🚀) is available if you want to try it out.
➡️Get in touch if you have any Qs/feedback!
Paper: https://t.co/Nuv8xV5LOa
Advanced AI systems require complex evaluations to measure abilities, but conventional analysis techniques often fall short.
Introducing HiBayES: a flexible, robust statistical modelling framework that accounts for the nuances & hierarchical structure of advanced evaluations.
🧵 Today we’re publishing our first Research Agenda – a detailed outline of the most urgent questions we’re working to answer as AI capabilities grow.
It’s our roadmap for tackling the hardest technical challenges in AI security🧵 Today we’re publishing our first Research Agenda – a detailed outline of the most urgent questions we’re working to answer as AI capabilities grow.
It’s our roadmap for tackling the hardest technical challenges in AI security🧵 Today we’re publishing our first Research Agenda – a detailed outline of the most urgent questions we’re working to answer as AI capabilities grow.
It’s our roadmap for tackling the hardest technical challenges in AI security🧵 Today we’re publishing our first Research Agenda – a detailed outline of the most urgent questions we’re working to answer as AI capabilities grow.
It’s our roadmap for tackling the hardest technical challenges in AI security.
Excited to share our brand-new work shedding some light on the neural mechanisms behind one of human’s coolest cognitive feats: compositional generalization of structural knowledge!
A Tweeprint-Thread 🧵
1/n
1/ New paper in Nature shows model collapse as successive model generations models are recursively trained on synthetic data.
This is an important result. While many researchers today view synthetic data as AI philosopher’s stone, there is no free lunch.
Read more 👇
Paper out in @PNASNews!
A 'cognitive mapping' lens on language in psychosis, using word embedding models, computational modelling, and MEG.
A hint of what's to come at @OxPsychiatry and @UCLBrainScience...
With @mcneural_, @YunzheNeuro, Ray Dolan.
https://t.co/3uhL6z3eSw
Preprint alert🚨! In this new paper we study how humans decompose dynamical subprocesses and leverage the abstracted subprocesses for compositional reuse of experience in new situations.
https://t.co/9UsV5uAcPE
Tweeprint to follow soon!
In our lab's latest paper, we introduce a novel modeling approach using RNNs to reveal the cognitive algorithms behind animal decision-making.
Check out our preprint, led by UCSD PhD student @Ji_An_Li and co-authored by Marcus Benna: https://t.co/UVNLpHb3rA
🦙Excited to share this demo of Alpaca
🔥Highlights: ~GPT3.5 performance for < 600$🔥
The goal was to have a simple model /training procedure that academics could study and improve with limited resources
We achieved that by finetuning a 7B LLaMA on 52K generated instructions
A while ago we published this #RegisteredReport in @NatureComms - but was this format of pre-registration really useful? Find some answers in this Q&A with us and one of the reviewers: https://t.co/eaLVc6AZRp