@DrJimFan Impressive progress and vision! Just wondering if the robot needs to look like humans. If the endgame is for robot to iterate by themselves. How about let them design beyond human morphology? I’m always amazed how the octopuses have a vision of 360 & physical flexibility. :)
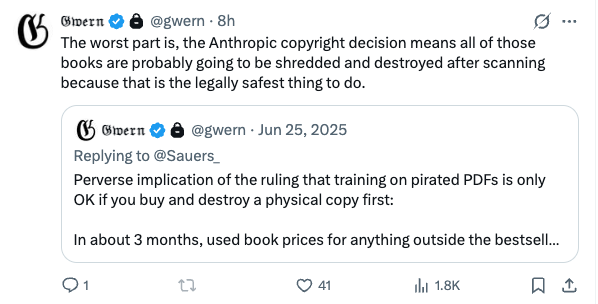
Anthropic is buying millions of rare books, scanning and destroying them because legally destruction is the safest option. This was a plot element in the Vernor Vinge novel, "The Rainbow's End", which I read 20 years ago.
Only one chance in this lifetime…
Like watching sunset at the beach from the most foreign seat in the cosmos, I couldn’t resist a cell phone video of Earthset. You can hear the shutter on the Nikon as @Astro_Christina is hammering away on 3-shot brackets and capturing those exceptional Earthset photos through the 400mm lens. @AstroVicGlover was in window 3 watching with @Astro_Jeremy next to him.
I could barely see the Moon through the docking hatch window but the iPhone was the perfect size to catch the view…this is uncropped, uncut with 8x zoom which is quite comparable to the view of the human eye. Enjoy.
This 30-min workshop by the creator of Claude Code will teach you more about vibe-coding than 100 YouTube video guides.
Bookmark it & give it 30 minutes today. This video will change the way you use Claude forever.
Introducing 𝑨𝒕𝒕𝒆𝒏𝒕𝒊𝒐𝒏 𝑹𝒆𝒔𝒊𝒅𝒖𝒂𝒍𝒔: Rethinking depth-wise aggregation.
Residual connections have long relied on fixed, uniform accumulation. Inspired by the duality of time and depth, we introduce Attention Residuals, replacing standard depth-wise recurrence with learned, input-dependent attention over preceding layers.
🔹 Enables networks to selectively retrieve past representations, naturally mitigating dilution and hidden-state growth.
🔹 Introduces Block AttnRes, partitioning layers into compressed blocks to make cross-layer attention practical at scale.
🔹 Serves as an efficient drop-in replacement, demonstrating a 1.25x compute advantage with negligible (<2%) inference latency overhead.
🔹 Validated on the Kimi Linear architecture (48B total, 3B activated parameters), delivering consistent downstream performance gains.
🔗Full report:
https://t.co/u3EHICG05h
24 dedicated people.
$30M spent on development.
Extreme specialization, speed, and power efficiency.
Today we launch Taalas’ first product. Check it out:
Details: https://t.co/88CA0XAL71
Demo chatbot: https://t.co/ec4ladcKnw
API: https://t.co/M3EkaxEqPj
SpaceX has developed a novel Space Situational Awareness (SSA) system, called Stargaze → https://t.co/dZUIfl2xmx
To maximize safety for all satellites in space, @SpaceX will be making Stargaze conjunction data available to all operators, free of charge. By providing this ephemeris sharing and conjunction screening service free of charge, we hope to motivate operators to take similar steps towards ephemeris sharing and safe flight.
256 Tb/s data rates over 200 km distance have been demonstrated on single mode fiber optic, which works out to 32 GB of data in flight, “stored” in the fiber, with 32 TB/s bandwidth. Neural network inference and training can have deterministic weight reference patterns, so it is amusing to consider a system with no DRAM, and weights continuously streamed into an L2 cache by a recycling fiber loop. The modern equivalent of the ancient mercury echo tube memories. You would need to pipeline a bunch of them to implement modern trillion parameter models, but fiber transmission may have a better growth trajectory than DRAM does today, so it might someday become viable.
Much more practically, you should be able to gang cheap flash memory together to provide almost any read bandwidth you require, as long as it is done a page at a time and pipelined well ahead. That should be viable for inference serving today if flash and accelerator vendors could agree on a high speed interface.