First thought-partnering with Grok4 on Tesla's growth potential - terminal valuation prediction $48T in 2040 ($15,000 per share)
* 2013-2019 (Premium EVs): This phase built Tesla's foundation, with stock growth tied to Model S/X launches and proving EV viability. It set the stage for mass scaling, but growth was uneven due to production "hell."
* 2020-2026 (Mass-Market EVs): Current phase emphasizes volume (Model 3/Y ~80% sales) and diversification (energy, FSD). Projections factor in 2025 dips (-27% YTD from politics/competition) but rebound via early Robotaxi (e.g., +9% stock surge post-Austin launch).carboncredits.comreddit.com Transition to autonomy begins here, shifting from cyclical auto revenue to recurring software.
* 2027-2033 (Robotaxi): Explosive if Tesla achieves unsupervised FSD and fleet scale. Valuations explode as margins hit 50-70% (vs. 10-20% EVs). Trajectory: Steady climbs with volatility from regulatory wins/losses.
* 2034-2040 (Optimus): Maturity phase with humanoid bots addressing labor shortages. Growth slows but compounds massively if prior phases succeed. Trajectory: Potential for 10-20x multiples if $5T market captured, but risks like over 100 competitors could cap at low end.
BREAKING:
Anthropic just dropped Claude Fable 5—this is Mythos, made safe for public release. It is the best coding model in the world.
We've been testing it internally @every for the last week or so across coding, writing, marketing, editing, and more—here's our vibe check:
- It broke our benchmarks. Fable scored a 91/100 on our Senior Engineer benchmark—this is human senior engineer level. The previous high score was Opus 4.8 at 63. GPT-5.5 is a 62.
- It's a one-shot wonder. You can set it and forget for hours or overnight on huge coding tasks, and come back to completed work. It cleared entire production bug backlogs, built a playable 3D, and even made a 2-minute animated film—all one-shot.
- Taste and attention to detail. In coding and knowledge work tasks, it has much better taste and attention to detail than we've ever seen. It gets subtle things right, adds little features you might not have thought of, and generally understands the assignment in ways that surprised us.
- Great use of context. We set it loose analyzing customer feedback surveys and our website data and it came back with a crisp, clean report that identified a. our biggest problem and b. a concrete testable solution—and then we sent it off to build that.
- It's best for power users. If you're already used to orchestrating multiple agents in your work, this model can do things that you've never seen before. If you're a knowledge worker or vibe coder with a more basic setup, you're not going to notice a huge difference—in fact, it probably isn't the right model for you.
- It's very slow, token-hungry. Using this thing for regular knowledge work is like squashing an ant with a rocket launcher. It also routinely uses 500k to 1M tokens on tasks. That's why it's best for your heaviest jobs—but not as good for tasks like collaborative writing.
- It's expensive. It's about twice as expensive as Opus, and it's also incredibly token hungry—so expect it to be something you'll use sparingly unless your company pays for it.
Overall, I think of it like a warp drive for coding: It can get you across the galaxy in a few hours, when it used to take months or years. But it's not appropriate for getting around town—you need something faster, cheaper, and more maneuverable.
The ceiling is extraordinarily high on this model though. Even our most advanced testers like @kieranklaassen felt like they were only scratching the surface of it.
Want our full vibe check with all of our testing and benchmarks? Read it on @every: https://t.co/MgJLZszJUB
I valued SpaceX for its IPO a few weeks ago, with minimal information and a promise to revisit the valuation, when the prospectus was made public. The prospectus is public, the offering price has been set and my update is up and running. https://t.co/zRjpD1C0wv
$AMD Dr. Su full press in Taiwan 🆕🚨🚨🚨
I dont think @AMD analysts or bears are ready for H2 2026 and 2027. The level of growth will be so massive that everyone would be shocked. Well mostly because they didnt read @MikeLongTerm threads.
CPU:GPU Ratio is much higher than 1:1, most likely in the 3-5:1 moving to 5-10:1 . Enterprises are demanding more and more agents running tasks longer and more intensive.
Dr. Su is too nice to say it out loud. But that does not mean training gonna go away. Just growing significantly slower than Inference.
Google I/O starts today. here's what to expect:
- Gemini 3.5 Pro/Flash models
- Gemini Spark (24/7 agent)
- Gemini CLI/Antigravity/AI Studio big updates
- Gemini x Android
- Gemini x Google Cloud
- Gemini x Chrome
....
continue in the comments if you'd like to add more to the list
#Google @GoogleAIStudio@GeminiApp@antigravity@googlecloud@Android@googlechrome
🚨 Gemini 3.5 Flash speed numbers just dropped
3-9x faster than current Flash peak speeds over 900 tokens/sec capability hasn't dropped, actually improved parameter count estimated larger than expected
video: full shooter game one-shot. holds up at speed.
Also currently testing 3.5 Pro on Arena.
Should I start posting Pro outputs now or wait for public launch? vote below 🫡
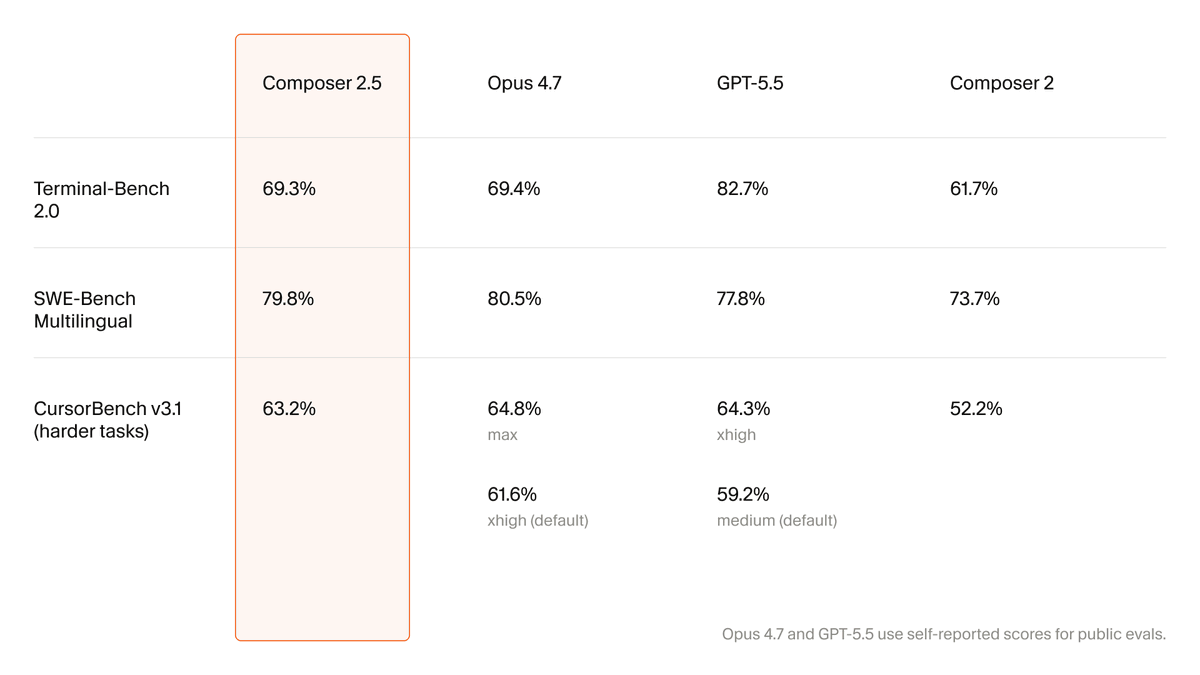
Introducing Composer 2.5, our most powerful model yet.
It's more intelligent, better at sustained work on long-running tasks, and more reliable at following complex instructions.
For the next week, we’re doubling the included usage of the model.
Introducing Particulate: a feed-forward model for 3D object articulation 💻✂️👓🧳
Particulate gives you a fully articulated 3D object, including part segmentation, kinematic structure & motion constraints, in a single forward pass in ~10secs.
🏅SOTA performance!
💡GenAI compatible: Turns AI-generated 3D meshes into fully articulated models!
Project page: https://t.co/8yYFpYdEkY
Code: https://t.co/CUuubxqbdY
Gemini 3.2 Flash - Capitalizing on DeepMind's clever distillation techniques...
Rumors are that benchmarks show it's hitting 92% of GPT 5.5's performance on coding and reasoning tasks while being 15-20x cheaper on inference costs. The latency improvements are insane - sub-200ms for most queries.
Google's distillation + sparsity techniques are paying off massively. They've essentially compressed a frontier model into a flash variant without the usual quality cliff.
Usage limits are up, effective today we're:
1) Doubling Claude Code's 5-hour limits for Pro, Max, Team and seat-based Enterprise plans
2) Removing peak hours limit reduction on Claude Code for Pro and Max plans
3) Substantially raising our API rate limits for Opus models
We’ve agreed to a partnership with @SpaceX that will substantially increase our compute capacity.
This, along with our other recent compute deals, means that we’ve been able to increase our usage limits for Claude Code and the Claude API.
In 2025, DeepMind CEO Demis Hassabis gave a 60-minute Cambridge lecture on AI as a discovery engine.
This is bigger than chatbots.
He explained:
- The "Move 37" method
- A billion years of PhD time
- Biology as an information system
12 lessons that will blow your mind: 🧵