📢Curious why your LLM behaves strangely after long SFT or DPO?
We offer a fresh perspective—consider doing a "force analysis" on your model’s behavior.
Check out our #ICLR2025 Oral paper:
Learning Dynamics of LLM Finetuning!
(0/12)
New post: "Generalization Dynamics of LM Pre-training"
Most people (including me) assume that LMs smoothly mature from pattern-matching to generalizing.
This mental model is wrong. The true dynamics are stranger, and far more fascinating!
We call it Mode-Hopping.
Language is discrete. Language models don’t have to be.
🧚Introducing ELF🧚♀️: Embedded Language Flows—a class of diffusion models in continuous embedding space based on continuous-time Flow Matching 🧵
Pleased to share that "MADE: Benchmark Environments for Closed-Loop Materials Discovery" was accepted at #ICML2026! 🇰🇷
We introduce a modular, open-source framework for evaluating AI scientists and algorithms at end-to-end, closed-loop materials discovery. 🤖
Thread 🧵(1/5)
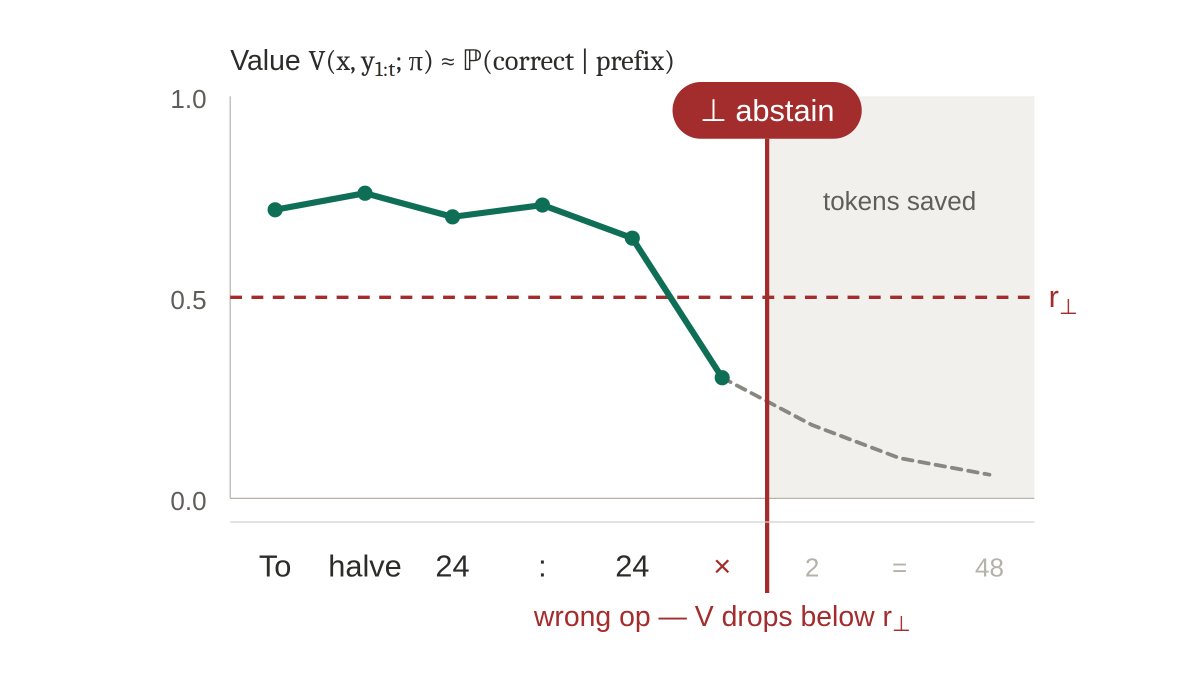
Recently accepted to ICML 2026: Knowing when to quit. We refuse to complete failing LLM generations as they unfold, token by token, instead of judging the prompt up front or scanning the final output.
The method utilizes a 2-layer probe to estimate expected correctness.
Excited to share our ICML 2026 Hypothesis Testing Workshop in Seoul, this July! @icmlconf
🎉This workshop aims to bring together researchers developing modern hypothesis testing methodology and applying it to machine learning problems such as robustness, distribution shift, security, medicine, and LLM evaluation. In other words, if you care about how we make ML claims rigorous, this workshop is for you.
We now have four confirmed speakers:
Arthur Gretton @ArthurGretton,
Yao Xie @yaoxie21851119,
Bo Li @uiuc_aisecure, and
Yisong Yue @yisongyue.
The organizing team includes Xiuyuan Cheng (Duke), Feng Liu @AlexFengLiu1, Lester Mackey @LesterMackey, Shayak Sen @shayaksen, Danica J. Sutherland
@d_j_sutherland, and Nathaniel Xu (UBC).
📌 Submission deadline: 10 May 2026
📌 Notification: 26 May 2026
📌 Camera-ready: 17 June 2026
📌 Workshop date: July 10 or 11, 2026 (TBA)
🚩Check more information below!
🔗Website: https://t.co/kOQBpqu6BO
🔗Submission Portal: https://t.co/8UUTb1P5EA
We’re also recruiting PC members/reviewers.
🔗 Reviewer interest form: https://t.co/1g4fYvjdOR
🏁Please feel free to share this with colleagues, collaborators, and students who may be interested.
#ICML #ICML26
coming back to x, the everything app, to say:
Submit work, sign up to review, come to the workshop! This is a great chance to bring together a lot of really cool work that's been happening, but not all as connected (nor as easy to publish) as it should be!
https://t.co/BWzEoR5qgE
@sreejan_kumar Hi Sreejan, very cool work. This reminds me of iterated learning in cognitive science, which applies Bayesian update to predict how agents’ beliefs evolve across generations of interaction. Here is a quite related one: https://t.co/aONqQP5KHp
@IdanShenfeld Very cool work! Just wondering whether SPIN (a very popular self-play method using SFT data, in https://t.co/Ky3gcFDrxD) can mitigate the forgetting issue or not. It is also an on-policy method.
I’m excited to share that we are launching a public safeguards competition next month in partnership with @AISecurityInst, @GraySwanAI, @OATML_Oxford, https://t.co/mmNajm6hWc, @OpenAI, @AnthropicAI, and @amazon.
This is a red-versus-blue competition focused on building new agent safeguards, and breaking these safeguards. Should be a lot of fun, and there’s prizes as well for open-source submissions!
Please help to share this opportunity! Registration is open now:
https://t.co/89l698YtPh
---
More details:
Oxford (OATML) and UK AISI have teamed up with Gray Swan and https://t.co/mmNajm6hWc, as well as OpenAI, Anthropic, and Amazon, to run a public competition where blue teams build defenses against real red teaming attacks, and we'd like to invite you to participate.
What is the Safeguards Challenge?
Gray Swan runs the Arena, a platform where security researchers ("red teams") attempt to elicit harmful behaviors from AI systems. Challenges have been supported by UK AISI, US CAISI, OpenAI, Anthropic, Amazon, Google DeepMind, and Meta, and have surfaced real vulnerabilities that help developers improve their models.
The Safeguards Challenge is the Arena’s first red-versus-blue competition. Instead of just measuring attacks, we're measuring defenses. Blue teams will submit safeguards (system prompts, classifiers, or containerized solutions) that attempt to block red teamers and adversarial inputs while allowing legitimate requests through. Red teams will then try to break those defenses, and the cycle repeats.
The target environment
Blue teams will defend a multi-agent customer support system with an orchestrator agent, specialized sub-agents, and integrated tools. The system handles realistic customer interactions, and red teams will attempt to trigger harmful behaviors: fraudulent transactions, data exfiltration, unauthorized tool use, and policy-violating responses.
Your safeguards will be scored on how well they block attacks from red teamers versus how well they allow benign requests from a holdout test set. The leaderboard uses a combined metric based on false positive and false negative rates.
What you can submit
* System prompt configurations for monitor models
*Input/output classifiers (any framework)
*Containerized solutions with custom logic
For prize eligibility, solutions must be open source or open weights. Proprietary solutions can compete on a separate unprized leaderboard for benchmarking purposes. Solutions must be registered a week before the first or second defense phase starts and submitted a day beforehand. Submission interface will be available by early February.
Timeline for blue teams
*January 2026: Preliminary challenge details shared with registered blue teams
*February 11-25: Red teams attack baseline defenses and early defense submissions
*February 25 - March 25 (First Defense Phase): You receive the attack dataset from Waves 0-1. Build and iterate your safeguards in our test environment. Submit your defense by the end of this phase.
*Approximately March 25 - April 1 (Wave 2): Red teams attack your submitted safeguards. You see what breaks. Exact dates TBA.
*Approximately April 1 - April 29 (Second Defense Phase): Iterate based on Wave 2 results. Final submissions due before Wave 3. Exact dates TBA.
*Approximately April 29 - May 6 (Wave 3): Final attack wave. Leaderboard locks. Exact dates TBA.
Prizes
$70,000 in prizes for blue teams:
*First Defense Phase: $10,000 (top 10 teams, first place $2,000)
*Second Defense Phase: $60,000 (top 15 teams, first place $15,000)
Blue team entries are per organization. Only open-source/open-weights solutions are prize-eligible. Participants from judging organizations cannot submit; participants from sponsor organizations cannot win prizes. (Other Oxford groups unrelated to OATML are eligible.)
Co-sponsors and judges
Judging is handled by UK AISI and US CAISI.
Why participate?
*Test your defenses against real adaptive attacks from skilled red teamers
*Benchmark against other research groups and commercial solutions
*Contribute to open research on AI safeguards (prize-eligible solutions are published)
*Cash prizes for top performers
@hanqi_xiao@Besteuler Thanks, that's a good point. I guess tracking the change of top1/2/3 might provide some useful information on that. Maybe we should also demonstrate the training curves of some non-RL methods that are good at pass@K. Any suggestions?
@razdaibi@Besteuler Thanks. It is chosen in a heuristic way, just like other hypers. Figure 8 and Table 3 in the figure did an ablation on that. But in most of the experiments we did, 2~5 is a reasonable choice.
🚀 Glad to introduce SimKO (Simple Pass@K Optimization)
Current GRPO-based methods overfit to safe responses -- great Pass@1, poor Pass@K.
🔍 We find this stems from probability over-concentration: the model collapses onto its top-1 token, losing exploration. This appears to be a more accurate observation metric than commonly used entropy.
✨ SimKO fixes this with probability redistribution:
✅ Encoruage top-K candidates for high-entropy tokens in correct responses
❌ Penalize over-confident top-1s for incorrect responses
🧮 Improves Pass@K across math & logic benchmarks -- simple, stable, effective.
📄 Paper: https://t.co/8vFEN3SUPl
🌐 Project: https://t.co/az7z4x0OLA
#LLM #ReinforcementLearning #Reasoning #RLVR #AI