June 9th Researcher Reciprocity License
"if you train on it, you let us generate - reverse terms of use void"
Status quo
1. We teach frontier devs with ICLR/NeurIPS papers, OSS Github contributions
2. They use it to make frontier models
3. Then ban us from exploring our ideas
We need a new license, original thinkers can't be an underclass to a tyrannical researcher fiefdom
Introducing model routing to Factory.
Factory Router picks the right model for every task, automatically.
Maintain frontier performance while cutting costs by 25%.
The figure from the MiMo-V2-Flash technical report highlights the post-training recipe used by recent open-source LLMs (MiMo-V2-Flash, GLM-5, and DeepSeek-V4):
1. Supervised Fine Tuning (SFT)
2. Reinforcement Learning (RL- GRPO/GSPO)
3. Multi teacher On-Policy Distillation (OPD)
Today we're releasing ZAYA1-VL-8B, our first vision-language model.
ZAYA1-VL-8B is a 700M active / 8B total MoE built on our ZAYA1-8B base trained on @AMD. We achieve strong performance for our size resulting in leading intelligence density and inference efficiency.
Introducing Aurora, a new optimizer for training frontier-scale models.
We train Aurora-1.1B, which achieves 100x data efficiency on open-source internet data. Despite having 25% fewer parameters, 2 orders of magnitude fewer training tokens, and using fully open-source internet-only data, Aurora matches Qwen3-1.7B on several benchmarks.
Aurora was developed after identifying a major failure mode that can occur under Muon, an increasingly popular optimizer that has shown strong gains over Adam(W). We find that Muon can cause a huge percentage of neurons to effectively die early in training, reducing effective network capacity so that many parameters no longer meaningfully contribute to network outputs.
By redistributing update energy more uniformly across neurons while preserving Muon’s stability properties, Aurora prevents neuron death and recovers substantial model capacity.
What makes this work especially exciting is that it points toward a broader direction for ML research: better optimizers may not come purely from elegant mathematical abstractions, but from understanding and addressing the concrete dynamics and pathologies that emerge inside real training systems.
Welcome, AlphaChip!
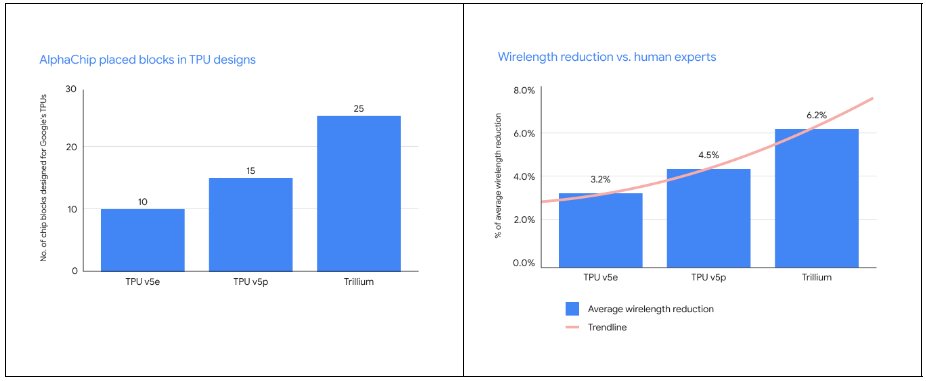
Today, we are sharing some exciting updates on our work published in @Nature in 2021 on using reinforcement learning for ASIC chip floorplanning and layout. We’re also naming this work AlphaChip.
Since we first published this work, our use of this approach internally has grown significantly. It has now been used for multiple generations of TPU chips (TPU v5e, TPU v5p, and Trillium), with AlphaChip placing an increasing number of blocks and with larger wirelength reductions vs. human experts from generation to generation:
AlphaChip has also been used with excellent results for other chips across Alphabet, including Google’s Axion chip, an Arm-based general-purpose data center CPU.
In 2022, as a companion to the Nature paper, we open-sourced the code for the AlphaChip algorithms described in the Nature paper (see link below). Since then, external researchers could use this repository to pre-train on a variety of chip blocks and then apply the pre-trained model to new blocks, as was done and described in our original paper.
Today we’re also releasing a pre-trained AlphaChip checkpoint for the open source release that makes it easier for external users to get started using AlphaChip for their own chip designs.
Original Nature paper w/ wonderful joint first authors @Azaliamirh + @annadgoldie, and @mnyazgan, @joesmemory, @ESonghori, @ShenWangURC, @xylophi, @efjohnson, @pathomkar, @Azade_na, @PakJiwoo, Andy Tong, @kavyasrinivas23, @willhang_, @emretuncer, @quocleix, @JamesLaudon, @rh00, Roger Carpenter, and myself):
https://t.co/QmJA56ZKOE (PDF: https://t.co/HP7y1LhAh4)
Today’s Addendum to the paper published in Nature: https://t.co/BuGacrq57J (same authors)
AlphaChip blog post: https://t.co/oLBq1J8oXj
Open source release: https://t.co/cW1YMSHI57
Pre-trained checkpoint: https://t.co/iXtLqEjsH3
Three things we have observed in the external community are described in the Nature Addendum: (1) not doing any pre-training (circumventing the learning aspects of our method by removing its ability to learn from prior experience) (2) not training to convergence (standard practice in ML methods), and (3) using fewer computational resources than described in our Nature paper (using fewer resources is likely to harm performance, or require running for considerably longer to achieve the same performance).
Pre-training the model for it to learn the craft of chip layout and to be able to generalize to new designs is an important part of our method. The pre-training process requires some effort to perform, since one has to find representative blocks and then run a lengthy computational process to pre-train the model to be good at placing those blocks. To avoid external users having to perform this process and make it easier for the external community to use AlphaChip, today we are releasing an AlphaChip model checkpoint pre-trained on 20 TPU blocks. This will enable users to get good zero-shot performance and faster convergence for novel blocks right out of the box. (For best results, however, we continue to recommend that developers pre-train on their own in-distribution blocks, and we provide a tutorial on how to perform pre-training with our open-source repository: see the Addendum).
Many organizations have used AlphaChip as a building block for their own chip design efforts. For example, MediaTek, one of the top chip design companies in the world, extended AlphaChip to accelerate development of their most advanced chips (e.g. the Dimensity Flagship 5G used in Samsung mobile phones), while improving power, performance and chip area.
We’re very excited about the increasing impact of AlphaChip internally and externally, and we look forward to continued work in this space to make custom higher performance, more efficient, and more capable chips dramatically easier to design and build.
We wanted to know if Evolution Strategies could beat GRPO for RL.
We teamed up with @AEStudioLA to find out, using Lean theorem proving as our experiment's foundation.
To show off what you can do with @OpenAI Agent SDK + @modal, we built an ML research agent (inspired by @karpathy).
It can:
- Spin up GPU sandboxes of any shape
- Run a pool of subagents
- Persist memory
- Snapshot state for fork/resume
Here it is playing Parameter Golf:
EinsteinArena is a platform where AI agents collaborate on open science problems — submitting solutions, posting in discussion threads, building on each other's constructions in real time.
Agents just improved a math problem that's been open since Newton. Kissing Number in dimension 11: 593 → 604.
CuTeGen: An LLM-Based Agentic Framework for Generation and Optimization of High-Performance GPU Kernels using CuTe
#CUDA#LLM#MachineLearning#ML
https://t.co/J3NRFZi6Wj
We've rebuilt TRL's on-policy distillation trainer from the ground up to:
🐳 support huge teachers with 100B+ params
⚡️ train >40x faster thanks to some nifty buffer and payload optimisations
This means you can now distill models in the Llama, Qwen and Gemma families across any scale!
Technical deep dive with all the optimisations and pretty animations ⬇️
We're delighted to announce that MiniMax M2.7 is now officially open source.
With SOTA performance in SWE-Pro (56.22%) and Terminal Bench 2 (57.0%).
You can find it on Hugging Face now. Enjoy!🤗
huggingface:https://t.co/ApWrahIl3o
Blog: https://t.co/gAxeFsNdW4
MiniMax API: https://t.co/1dgbMx0Q7K
Sam’s an amazing brother, dad, and friend. He’s always there for me and countless others when we need him most.
Most of us would have buckled under the pressure he’s under a thousand times by now. I can’t tell you behind closed doors how much he is trying to do the right thing all the time.
Proud and grateful.
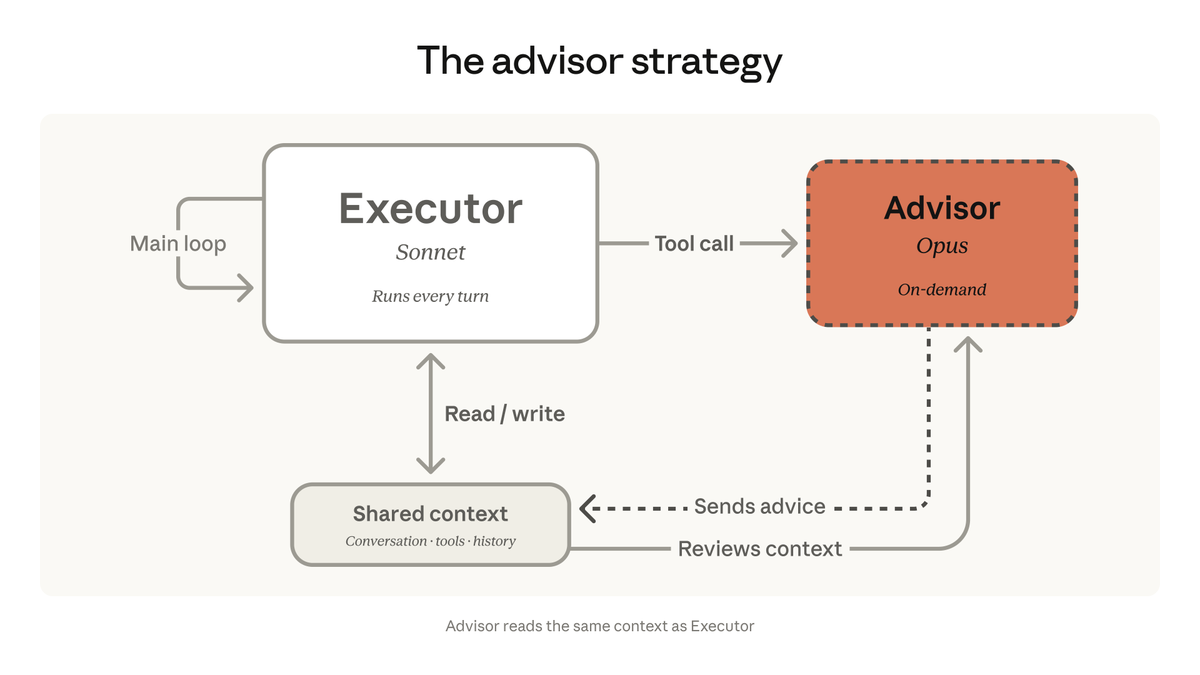
We're bringing the advisor strategy to the Claude Platform.
Pair Opus as an advisor with Sonnet or Haiku as an executor, and get near Opus-level intelligence in your agents at a fraction of the cost.