Are neural nets across modalities really converging to the same representation as they scale, as the Platonic Representation Hypothesis suggests?
We show that common representational similarity metrics are confounded by network width & depth. We propose a permutation-based null calibration that fixes this.
Result❓
• Global convergence largely disappears.
• Local neighborhoods persist.
We propose the alternative Aristotelian Representation Hypothesis: Neural networks, trained with different objectives on different data and modalities, are converging to shared local neighborhood relationships
Very proud of @FabianGroger and @ShuoWen18 for this work!
Paper: https://t.co/GmkhwsiN1N
Webpage: https://t.co/xaI31BU2FS
Code: https://t.co/5qItdzRBZP
AI agents like @openclaw 🦞 are everywhere, answering emails, managing calendars, doing our chores for us
📣 REALM is back for year 2! Workshop for Research on Agent Language Models at #EMNLP2026, Budapest 🇭🇺
Stellar lineup ⬇️
�� Submit by July 17, 23:59 AoE
#LLMAgents #NLProc
The historic 90th CSH Symposium on AI in Biology at @CSHL has come to an end. After a decade of remarkable advances in AI x Bio, aspirations have become bolder than ever. The future looks bright but much work remains to turn hype into real-world progress. Thanks to all speakers!
Just want to give a shout-out to David Kelley @drklly who I think often does not get the credit he deserves (outside our core community).
I want to highlight why I think he is such a fantastic scientist and leader in regulatory genomics. 1/
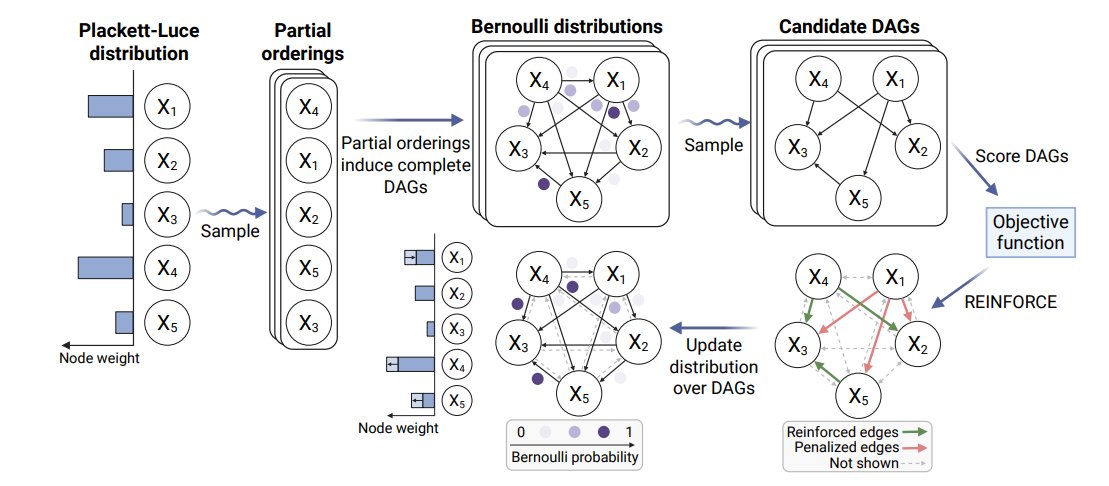
Excited to share our #ICML paper introducing PACER, a scalable framework for causal discovery from large-scale interventional data.
PACER guarantees acyclicity by design, enabling direct optimization over valid causal structures and showing that scalable causal discovery is achievable through principled search-space design.
Across protein signaling networks and large-scale Perturb-seq benchmarks, PACER matches or outperforms state-of-the-art causal discovery methods while being much more efficient and scaling to thousands of variables.
Huge kudos to everyone involved in this work, especially Ramon Vinas Torne and three fantastic Master students Silvia Fabregas, Soyon Park and Ivo Ban 🚀
Paper: https://t.co/18pmVC9Q6C
Code: https://t.co/qFyrMKR8bJ
Project page: https://t.co/4fJHk3SoaS
Excited to share that our work on the Aristotelian Representation Hypothesis ⬇️ has been accepted at #ICML!
Big shoutout to @FabianGroger and @ShuoWen18 👏
We'll also be presenting another #ICML paper on causal discovery from large-scale interventional data, preprint coming 🔜
Are neural nets across modalities really converging to the same representation as they scale, as the Platonic Representation Hypothesis suggests?
We show that common representational similarity metrics are confounded by network width & depth. We propose a permutation-based null calibration that fixes this.
Result❓
• Global convergence largely disappears.
• Local neighborhoods persist.
We propose the alternative Aristotelian Representation Hypothesis: Neural networks, trained with different objectives on different data and modalities, are converging to shared local neighborhood relationships
Very proud of @FabianGroger and @ShuoWen18 for this work!
Paper: https://t.co/GmkhwsiN1N
Webpage: https://t.co/xaI31BU2FS
Code: https://t.co/5qItdzRBZP
It was fun to write a Journal Club for @NatureRevGenet on DeepSEA and the moment regulatory genomics started learning its own “vocabulary” 🧬
A short reflection on the shift from hand-engineered features to learned sequence representations and how it reshaped thinking across the field
https://t.co/j5a27nE2K3
🇧🇷 Heading to #ICLR2026 in Rio this week to present HeurekaBench at the main conference!
1️⃣ HeurekaBench: A Benchmarking Framework for AI Co-scientist
We propose a framework to create benchmarks for AI Co-Scientists that takes existing publications and code repositories to generate and evaluate open-ended questions.
📍 Poster #1115, Pavilion 3
🗓️April 23, 10:30 AM - 1:00 PM
🔗https://t.co/b0FQep3Kws
Exciting news for the AI and Biomedicine community! 🧬💻
Join the 2nd MMFM-BIOMED Workshop at @CVPR in Denver! We’re bringing together experts to tackle the challenges and opportunities of Multimodal Foundation Models for Biomedicine.
Call for Papers is OPEN! 📝
We’re looking for short papers (max 4 pages) on:
🔹 Challenges in current modeling, such as multimodal alignment, data curation, benchmarking, and agentic systems
🔹 New opportunities in drug discovery & surgery
Important Dates:
⏰ Submission Deadline: May 1, 2026
📣 Notification: May 10, 2026
📅 Workshop: June 3-4, 2026
Featuring incredible speakers from @Stanford, @Princeton, @EPFL, and the University of Strasbourg!
Submit your work here: https://t.co/CjqffR2OCX
#CVPR #BiomedicalAI #FoundationModels #MachineLearning #HealthTech #AI
We've seen how "predict the average" is a surprisingly hard benchmark to beat in perturbation biology.
Two papers Systema, Miller et al. show our standard metrics are often too weak to detect actual biological learning.
Wrote on both and their importance👇
https://t.co/c7helxSywy
Good questions. I don't think calibration hides global structure. It just removes confounders (width-dependent null baselines + depth/search inflation). We show that the calibrated test still detects true alignment when it's there. It's not a signal-destroyer, it's a baseline correction.
On local -> global: not necessarily. The local convergence concerns neighborhood relations ("who is near whom"), whereas global concerns the full geometry / distances / spectrum. You can match kNN graphs without matching global distances or a single global isometry. So local agreement doesn't imply a hidden global emergence that metrics fail to see.
On modalities: Our results suggest the most robust cross-setting commonality is local/relational. Stronger "one global geometry up to an orthogonal map" seems to hold with extra structure/assumptions (e.g., specific multimodal contrastive families like shown in this paper). So: shared latent structure is plausible, but what's reliably recoverable across broad settings is often local rather than fully global.
In our recent work, we show that representational similarity metrics can “converge” just because models get wider/deeper. After calibration, we show that the global/spectral scaling trend largely vanishes and propose the alternative Aristotelian Representation Hypothesis: models converge in local neighborhoods
https://t.co/mGtcHS0kgb
Join IICD for a virtual seminar with @mariabrbic, from @EPFL_en on March 11. Don’t miss her presentation on how AI can facilitate discoveries in life sciences >> https://t.co/LWdvgy5acn #AI#AIResearch#CancerDynamics
Amazing work, congrats @montsgarg@sharut_gupta@phillip_isola!
@sannaan_k This is complementary to our ARH hypothesis. In ARH, after calibration, increasing model scale strengthens local neighborhood alignment but doesn't show robust global/spectral trend. This paper studies specific multimodal contrastive models and shows shared orthogonal alignment under similarity kernel agreement assumption. These can coexist. ARH-like local agreement may even help explain why such stronger alignment appears in that family.