On-Policy Distillation is the most active new research direction being explored in RL for LLMs. Had the chance to discuss how it works with Dwarkesh and why it fits so nicely into large-scale pipelines.
We are releasing Carbon: a crazy fast DNA model
Carbon is 275x faster than the next best model. So fast you can process the whole human genome on a single GPU in <2 days.
Here are the tricks we used:
When modelling DNA sequences a lot of the performance comes down to tokenizing the sequences in a smart way. BPE tokenizer struggle because there are no whitespaces and character (called base in DNA) level tokenizers waste a lot of compute on too many tokens.
Carbon is built with a unique tokenizer: we split sequences in chunks of 6 bases, but during both training and inference we can work with single base resolution. That's similar to having word tokens but resolving them at the character level. All possible thanks to the DNA tokens unique structure.
The architecture combined with the tokenizer makes the model 275x faster than the previous SoTA (Evo2) at this size.
We built an interactive demo so you can explore how the model can generate DNA sequences, investigate the structure of genes, predict the effect of mutations, generate and fold proteins and even reconstruct parts of the tree of life.
https://t.co/OWEUoxAFjG
People talk, listen, watch, think, and collaborate at the same time, in real time. We've designed an AI that works with people the same way.
We share our approach, early results, and a quick look at our model in action.
https://t.co/AFJZ5kH7Ku
go to bed
right now
i know the build is almost finished
the eval can wait til morning
the agent will still be failing tomorrow
you won't figure out why it's hallucinating
yes your coworker ships on 4 hrs of sleep
they also hallucinate a lot
off you go
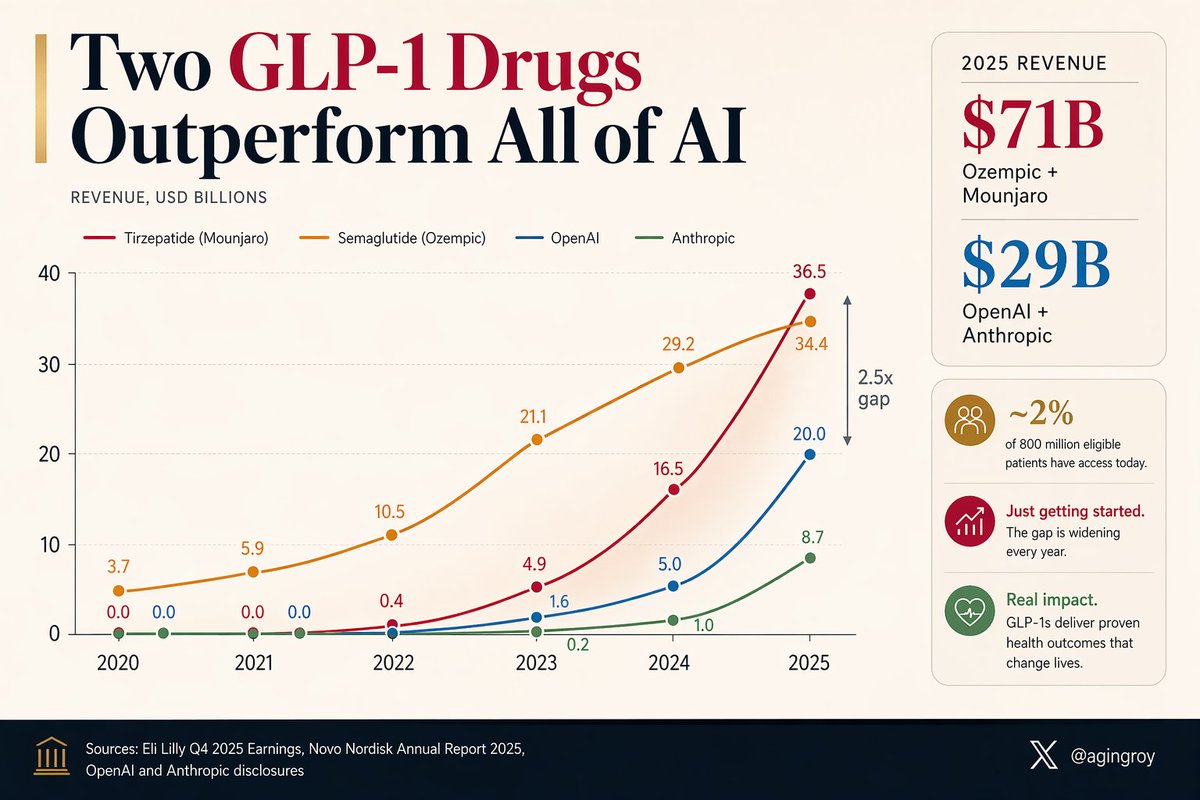
A weekly jab in the belly is generating more revenue than the entire AI industry.
Ozempic + Mounjaro: $71B in 2025.
OpenAI + Anthropic: $29B.
And they've barely started. ~2% of the 800 million eligible patients can currently access them.
h/t @DrSamuelBHume
Excited to share Orthrus is now published in Nature Methods! This was a work from our PhDs in which we showed 3 things:
- There's lots of room for new biologically grounded self-supervised objectives
- The "y - intercept" in scaling is important! We show that representations from 10 million parameter Orthrus outperform a 7 billion parameter model, 700 its size.
- Orthrus works in the low-data regime where data acquisition is especially expensive: low throughput experimental data and clinical trials
Ian and I are now building BlankBio to apply these ideas at a bigger scale. I'm going to be at AACR get in touch if you want to chat!
What if AI could explain why a protein is a kinase, not just tell you it is?
We built just that.
BioReason-Pro is a multimodal LLM that reasons about protein function — walking through domains, interactions, and biological context to make predictions you can actually evaluate.
1/7 First of all, big shoutout to co-authors on modeling (@MKarimzade, @neal_ravindra, @RexMa9, @HAOTIANCUI1, @LeeTaliq), huge appreciation to data generation (Lexi, @alerasool, Adam) and bioinformatics team (@_annhuang), and leadership for vision and direction (@BoWang87, @inCiChu)!
Preprint is now live on bioRxiv: https://t.co/31ei4v8huk
All models start from high-quality data.
2026 may be the year AI starts to truly reason about biology.
AlphaFold helped close the sequence → structure gap.
The next frontier is sequence → functions.
Today, together with @genophoria and the team at @arcinstitute , we’re releasing BioReason-Pro — the first multimodal reasoning model for protein function prediction.
Over 250 million protein sequences are known, but fewer than 0.1% have confirmed functions. Today, @genophoria, @BoWang87 & team introduce BioReason-Pro, a multimodal reasoning model that predicts protein function and explains its reasoning like an expert would.
1/ So excited to have had the opportunity of contributing to this magnificent effort! Foundation models of observational transcriptome often memorize gene co-expression networks without understanding the underlying logic. Genetic perturbation datasets make it possible to
Today we’re announcing X-Cell — Xaira’s first step toward a virtual cell. 🧬
A foundation model that predicts how gene expression changes under causal perturbations — across cell types, conditions, and even unseen biology.
This is not trained on observational atlases.
It is trained on interventions.
🧵👇