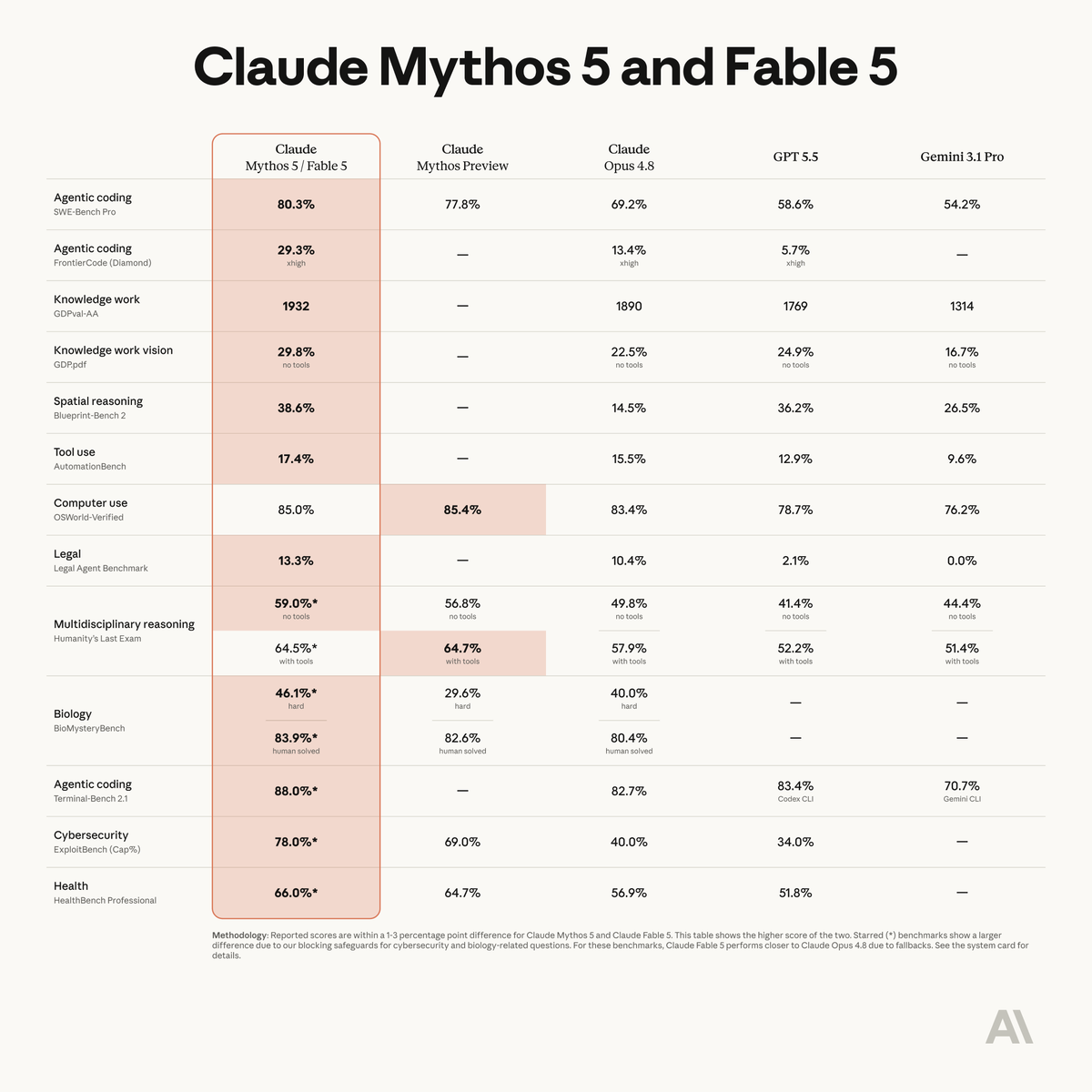
Fable 5 is state-of-the-art on nearly all tested benchmarks, with exceptional performance in software engineering, knowledge work, scientific research, and vision.
The longer and more complex the task, the larger Fable 5’s lead over our other models.
Opus 4.8 is doing what 4.7 refused to do.
4.7 refused tasks related to:
• diversity hiring
• finance
• paychecks
Said "too risky."
@zapier tests every model by asking it to do a set of tasks and sees how many they get right.
I asked the guy who runs their benchmark work to teach me what each model can do and where they fail.
4.8 does the most multi-task work well, but it's not the winner for every task.
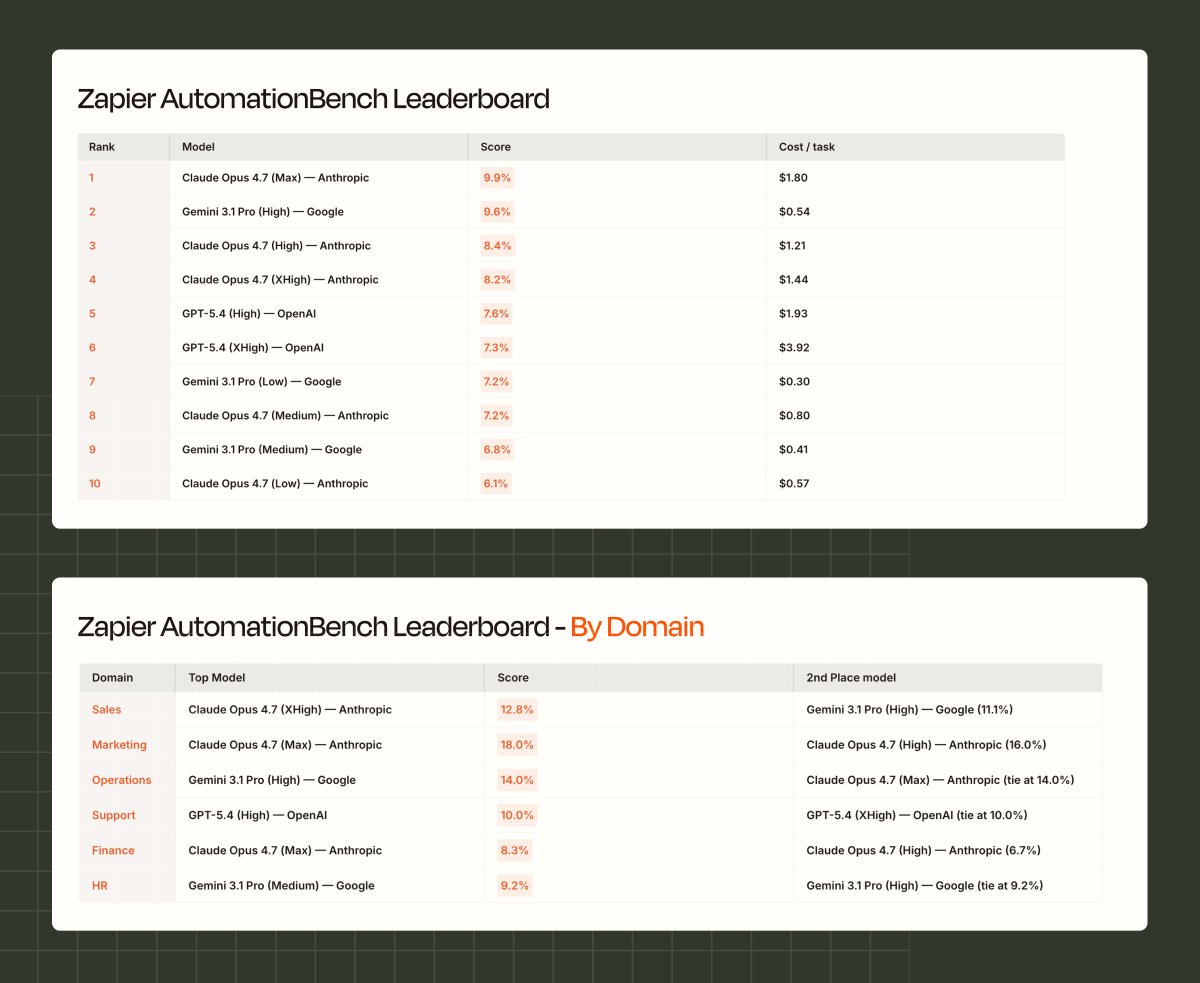
AutomationBench tests how models perform on the trickiest, stickiest real-world workflows we know customers are actually trying to automate. 600 tasks, 6 domains, deterministic scoring.
And today our scores are featured on @AnthropicAI's official launch scorecard.
Today we open early access to @Zapier's next product
We've been using it internally for months (>1,000,000 actions executed so far) and it's completely changed how we work.
We're letting a small group of AI-forward teams try it first and give feedback.
Who we’re looking for:
- 10-100 person teams using AI daily, but need to do so more collaboratively
- teams ready to build and ship automations through agents, not just chat
- teams that already work in the open (call recordings, shared docs, public channels, etc)
- teams obsessed with optimizing every aspect of their work
Join the waitlist: https://t.co/TjsaSI6QdN
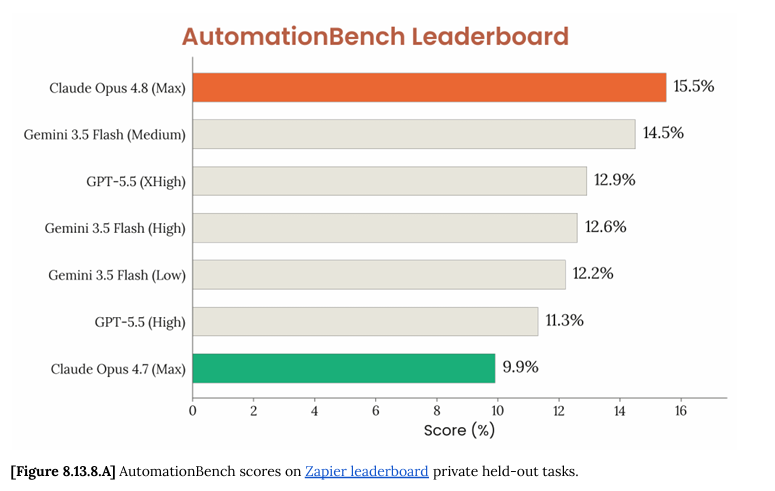
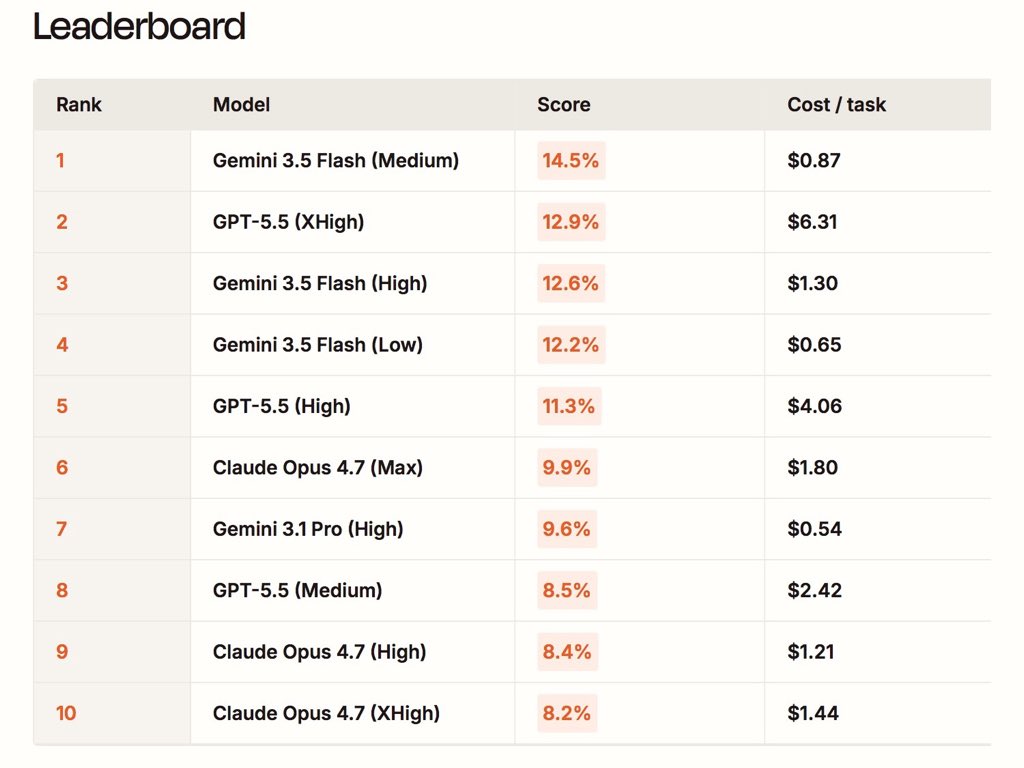
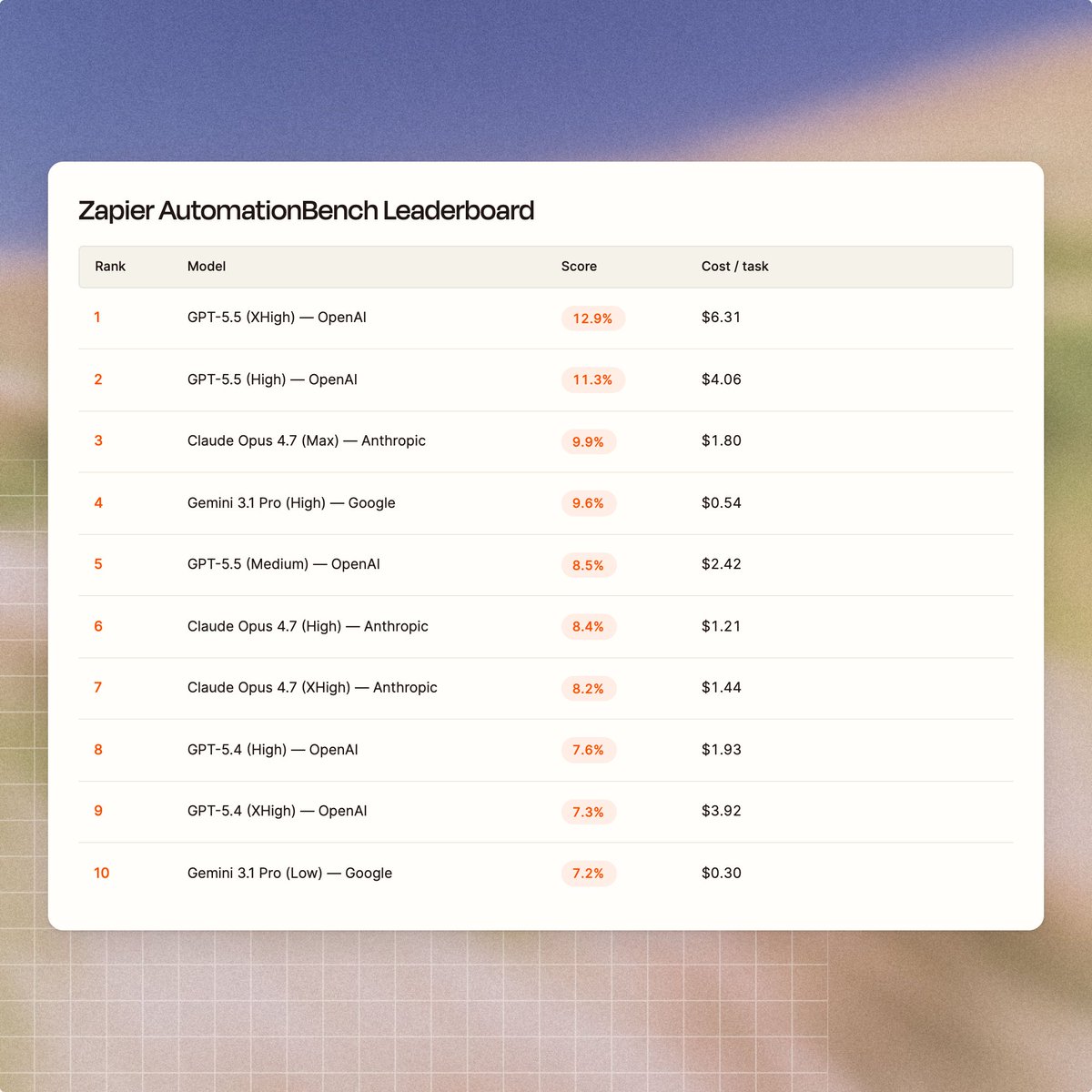
GPT-5.5 just hit 12.9% on our AutomationBench leaderboard
First model to break 10%
When context is missing, most models stop. GPT-5.5 keeps checking emails, docs, and chats until it knows what to do
It’s been super fun working on this with @danielwshepard! It’s truly a great benchmark.
Also thanks @mikeknoop for helping us figure things out along the way and @PrimeIntellect for the great verifiers framework + Lab 🤝
We built an AI benchmark that measures real work.
Today we're releasing it to everyone.
AI evals tell you whether a model can do complex reasoning or generate code. Useful, but usually not the question our customers ask. They want to know: can this model find the right CRM record, send the right follow-up, and not break anything along the way?
We went looking for a benchmark that tested that. Nobody had built one, so we did.
@Zapier’s AutomationBench drops AI models into realistic business environments across six domains (Sales, Marketing, Ops, Support, Finance, HR) and checks whether the work actually got done.
The tasks include live CRM data, inbox threads with ambiguous context, and multi-step tool chains where one wrong call cascades.
Scoring is deterministic: either the right records were updated and the right messages were sent, or they weren't.
It’s useful enough that we're releasing it publicly today. Open task set, open methodology, open leaderboard. Everyone should have access to this.
No model has cracked 10%. Yet.
Try it here: https://t.co/V7qHAGX7Ql
We're excited to support the release of @Zapier's AutomationBench on the Environments Hub, measuring frontier performance on real Zapier workflows.
Across 6 domains, 47 tools, and 600 tasks, frontier models all score under 10%.
We built an AI benchmark that measures real work.
Today we're releasing it to everyone.
AI evals tell you whether a model can do complex reasoning or generate code. Useful, but usually not the question our customers ask. They want to know: can this model find the right CRM record, send the right follow-up, and not break anything along the way?
We went looking for a benchmark that tested that. Nobody had built one, so we did.
@Zapier’s AutomationBench drops AI models into realistic business environments across six domains (Sales, Marketing, Ops, Support, Finance, HR) and checks whether the work actually got done.
The tasks include live CRM data, inbox threads with ambiguous context, and multi-step tool chains where one wrong call cascades.
Scoring is deterministic: either the right records were updated and the right messages were sent, or they weren't.
It’s useful enough that we're releasing it publicly today. Open task set, open methodology, open leaderboard. Everyone should have access to this.
No model has cracked 10%. Yet.
Try it here: https://t.co/V7qHAGX7Ql
Today we open the Zapier SDK to everyone.
If you're building with AI agents, this is for you.
I've been using this for 2 months. It's totally changed how I do my job.
You install it in your coding agent. Cursor, Claude Code, Codex, whatever you use. Now that agent has access to 8,000+ apps through @Zapier and can do anything those APIs can do.
I think it’s the most powerful thing we’ve launched in years. Now in open beta.
Just give this link right to your agent:
https://t.co/k6arEyZMMU
Agency > Intelligence
I had this intuitively wrong for decades, I think due to a pervasive cultural veneration of intelligence, various entertainment/media, obsession with IQ etc. Agency is significantly more powerful and significantly more scarce. Are you hiring for agency? Are we educating for agency? Are you acting as if you had 10X agency?
Grok explanation is ~close:
“Agency, as a personality trait, refers to an individual's capacity to take initiative, make decisions, and exert control over their actions and environment. It’s about being proactive rather than reactive—someone with high agency doesn’t just let life happen to them; they shape it. Think of it as a blend of self-efficacy, determination, and a sense of ownership over one’s path.
People with strong agency tend to set goals and pursue them with confidence, even in the face of obstacles. They’re the type to say, “I’ll figure it out,” and then actually do it. On the flip side, someone low in agency might feel more like a passenger in their own life, waiting for external forces—like luck, other people, or circumstances—to dictate what happens next.
It’s not quite the same as assertiveness or ambition, though it can overlap. Agency is quieter, more internal—it’s the belief that you *can* act, paired with the will to follow through. Psychologists often tie it to concepts like locus of control: high-agency folks lean toward an internal locus, feeling they steer their fate, while low-agency folks might lean external, seeing life as something that happens *to* them.”
If you build AI agents, don't miss this session.
Next Tuesday, we're going inside the RL environments that make them work.
Join Will Brown (@willccbb) from @PrimeIntellect and our own Robin Salimans as we show how we design spaces where agents improve safely & efficiently.
Here's what we'll cover 👇
1. What are RL environments?
A look at how we use controlled, instrumented settings to let agents safely learn from feedback.
2. Building RL environments at Zapier
How we’re applying the Verifiers library and GEPA (Genetic-Pareto) optimization to evaluate and refine agent behavior on real automation tasks.
3. Lessons learned so far
Early insights into what’s worked, what hasn’t, and how we’re evolving our approach to agent training and evaluation.
Join us live, Tuesday December 2nd at 1 PM ET.
Reserve a seat here: https://t.co/j2epeJic5v