At COMPUTEX 2026, the industry got its first look at the Marvell Teralynx T100: the industry's first 102.4 Tbps switch purpose-built for AI data centers, delivering up to 25% lower power than competitive solutions.
Meta has earned the right to invest in AI.
Best in class gross margins at 82%, ahead of every other Mag 7 name.
Best in class growth, +33% YoY, behind only Nvidia. And the growth itself is enabled by their AI initiatives. Better targeting, better ranking, better creative. AI is literally why the top line is accelerating.
And then there's distribution. 3.56 billion people use a Meta product every day. Roughly 43% of the planet.
Margin, growth, distribution. Nobody else in the basket runs the table.
$META
If you hold $MRVL, Coherent, or Lumentum, this one changes a risk input.
China controls indium phosphate - the mineral in every data center's optical networking. They restricted it earlier this year, similar to the rare earth playbook.
@jvisserlabs on The Pomp Podcast: Coherent's CEO went to China with Trump during the Xi state visit. The CEO is not taking that trip for tourism.
The implication: US-China trade negotiations now affect data center deployment timelines directly - not just chip access. A stall in talks is a build constraint no one is pricing into optical networking names.
Full minerals bottleneck analysis: https://t.co/sC4T7uAKCw
Source: The Pomp Podcast - https://t.co/ehw2PIa3sa
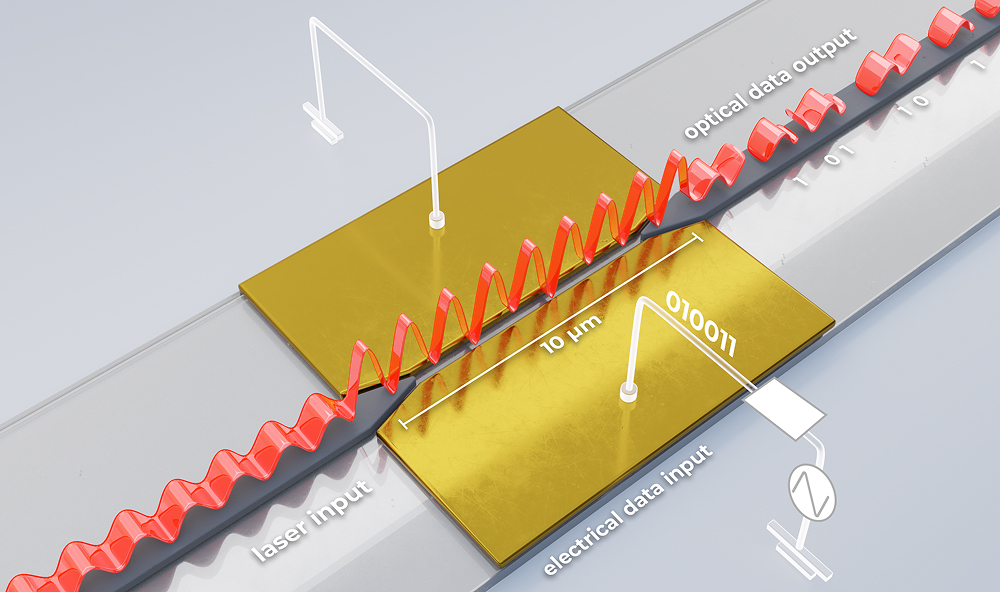
Contemporary silicon photonics modulators are constrained by the diffraction limit of light, restricting their ability to scale efficiently to the bandwidths AI infrastructure will require. Plasmonics offers a path forward.
By compressing light below the diffraction limit at a metal-dielectric interface, plasmonic modulators can operate at speeds exceeding 1 THz, more than 10x faster than conventional photonic modulators, while measuring approximately 10 microns in length, 300x to 500x shorter. The result is exponentially higher bandwidth density within the same silicon photonics platform, without requiring a shift to new material systems.
Marvell Senior Director Claudia Hoessbacher and Director Wolfgang Heni of Optical Engineering detail the technology, its applications across scale-up and scale-across networks, and where development stands today.
Read more: https://t.co/3z9yPJxzac
This is a major tailwind for $DOCN.
@digitalocean is built for exactly this world - affordable GPU hosting, open-weights models (Llama, DeepSeek, etc.), self-hosted inference and sovereign AI.
Developers & enterprises fleeing lock-in risk will flock here.
Open era = $DOCN's moment.
In an exclusive interview with DIGITIMES at Computex 2026, Marvell President and Chief Operating Officer Chris Koopmans covered a lot of ground: the company's decade-long transformation into a data infrastructure leader, why securing supply chain capacity is ultimately about trust, and how the transition from copper to optical will unfold over the next five years in scale-up networks.
On the copper wall: "The copper wall will eventually fall." On the ASIC business: it is fundamentally an I/O business, not an XPU business. And on supply constraints: the current environment may actually be healthier for the long-term trajectory of the AI industry than unconstrained growth would be.
A substantive read for anyone tracking where AI infrastructure is headed: https://t.co/FbpoMeJhwL
$MRVL Marvell CEO Matt Murphy: Data center growth continues accelerating despite already massive scale
"Data center last year grew 46%. It will be like 50% this year. And then we signaled our current indication for next year would be like 55%"
As relevant as ever.
$NBIS and $CRWV depend on the big labs + hyperscaler (temporary) excess demand vs own supply.
Fable’s debacle might just be a wobble for Anthropic & Co. but we sleep much better owning a company that needs to fill just a couple of hundred MWs of inference demand from non frontier labs to keep working through this cycle.
$DOCN is among the best model routers out there with as broad a coverage as you can get.
Might get punished with the others on Monday, but this is medium-long term very positive for the NYC team.
New business formation is inflecting with AI. These businesses need tech and it’s also becoming easier than ever to build applications and we are seeing it first hand at @digitalocean’s as we are the #1 cloud for these startups !!
לא נראה לי שזה סופו של השוק השורי. המאג-7 הולכות וננעלות במרוץ חימוש, שורפות חלק גדול מתזרים המזומנים שלהן על תשתיות AI וכבר פונות לגיוס חוב והנפקת מניות כדי לממן עוד מזה. כרגיל יהיו ניעורים ותיקונים כדי לנקז קצת אופוריה מהקצוות הספקולטיבים של השוק, אבל גרוסו מודו שום דבר לא עוצר את הרכבת הזו.
Wow, Berkshire Hathaway investing $10 billion into $GOOGL in a private placement as part of a broader $80 billion equity capital raise by the company to expand its AI infrastructure
$MRVL is now +17% overnight after Jensen called it the "next $1T company"
Possible?
Analysts are forecasting ~$11.50 EPS for 2030...that's a ramp up from $1.57 in FY25 (56% CAGR).
That's a pretty insane growth probably deserving of ~50-60x EPS multiple assuming a 1x PEG and assuming markets stay hot for the next few years.
For reference, $AMD is ~58x PE for 51% CAGR. Probably the fairest comp for the growth out there.
At 60x EPS multiple on $11.50 EPS you get ~$600B market cap (~2.8x from today).
Getting there before 2030 seems potentially challenging, but this isn't to say I'd be bearish on $MRVL at all.
In fact, very bullish for a 5-7 year time frame.
Watched $MRVL CEO Matt’s keynote. Lots of interesting stuffs (in addition to Jensen’s co-stage speech) and if you want to have a good general idea of the company, go watch it. BUT one thing at the end caught my thinking. Matt said in the future, distance of transmitting data will not matter because the connectivity will be via optical/photonics. This has huge implications for how the future data centers and therefore compute is structured.
Currently, you have the compute board structured with different parts (CPUs, GPUs, memory, etc.) closely together is partly because the data transmitted between them via copper requires so. That’s one kind of limit in designing the board and how compute is carried out. What if we take out the copper and replace it with optical/photonics? Then there will likely be no need to have to place the different parts together on one board.
Use your great imagination. It probably means that in the future, we will have one rack of GPUs, one rack of CPUs, one rack of memory, etc., all of which can be easily extended as necessary. They will be called GPU pool, CPU pool, memory pool, etc. When the different parts are pulled into segregated pools, the utilization of each parts/pools can be optimized. This basically and fundamentally solve the low utilization of GPUs in the current data center structure.
We can even imagine further. Because of the segregated pools and how flexibly we can design the system and structure, computing will also be fundamentally changed. New XPUs will be designed for specific use cases, workload agents and LLM models. These XPUs may be stationed in one data center, but this data center will be part of many campuses where each of them is by itself and together holistically form a giant computer across regions. The potential of compute will be scaled to an unbelievable level because of the no limit of connectivity via optical/photonics.
Great presentation by Matt.
$MRVL $NVDA $LITE $COHR $NOK $AAOI
$DOCN @digitalocean
My view: Impact of MSFT decision to cut off Claude Code from internal devs bc cost (per token) is just too high.
*Exactly*
this is *exactly* the DOCN thesis.
The first read is obvious: more agentic coding means more inference demand.
ok, of course. Duh.
But the second read is the one that matters.
Enterprises cannot just spray every task at the most expensive frontier model forever; not even MSFT.
That is not a business model. That is a cost explosion.
The future is not open source versus closed source. It's far more nuanced.
The future is "weighted average intelligence cost." OK I made up a new phrase 😂.
Use the frontier model when it matters. Use the smaller or open model when it is good enough. Route intelligently. Keep accuracy high. Keep latency low. Collapse cost per useful output.
This is DOCN's software layer.
So what is that? It's *a lot.*
It is routing, orchestration, model selection, open source model support, closed source model integration, caching, memory, state management, data movement, database access, storage, networking, security, observability, traceability, workload scheduling, sandboxing, governance, cost controls, latency optimization, throughput optimization, kernel optimization, deployment, scaling, retries, failover, and monitoring.
That is DOCN’s opening. This is why they are suddenly growing 130%+ with $1M+ ARR companies- AI natives.
They are a full blown cloud + AI inference cloud.
This is what CEO means by "dumb tokens" versus "smart tokens."
A token generated by the wrong model at the wrong cost is waste.
A token routed to the right model, with the right accuracy, latency, and context, is margin.
So Microsoft pulling back from expensive Claude Code usage is not anti AI.
It is the beginning of AI cost discipline.
And AI cost discipline is exactly where DOCN wants to live.
Look at the benchmarks. This is about to be an "AI Native" hyperscaler.
Added to my $META position. The company is one of the clearest AI winners, both short- and long-term, yet market sentiment has turned extremely negative, with a focus on CapEx spend and a deep misunderstanding of fungibility and ROI mechanics for their AI spend.