Paper is now released: https://t.co/vhkRlEfsoX
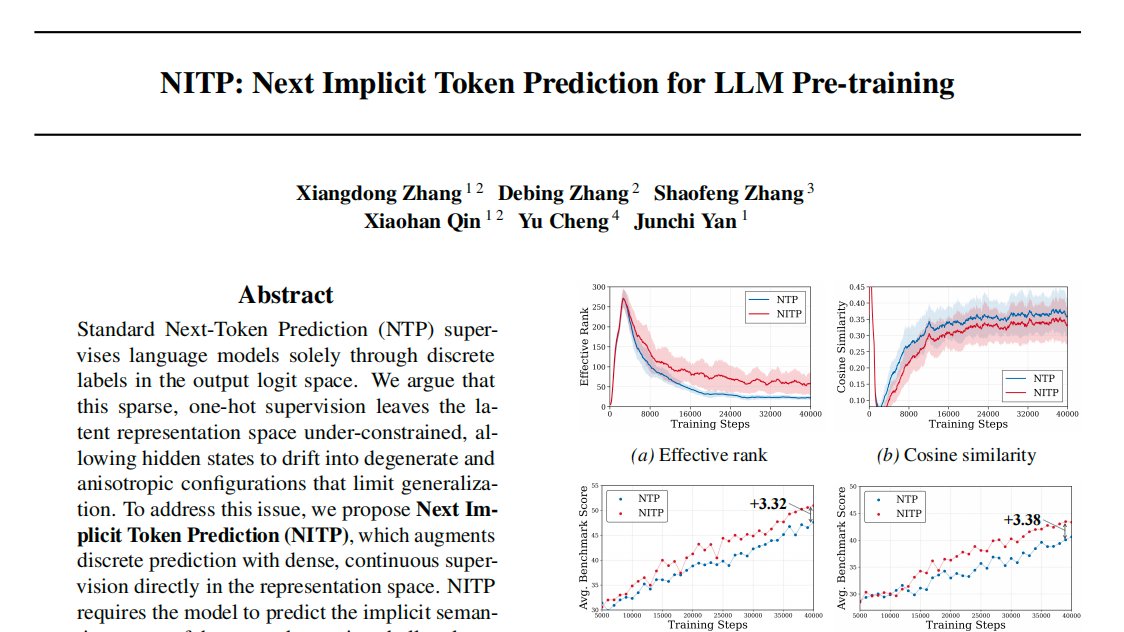
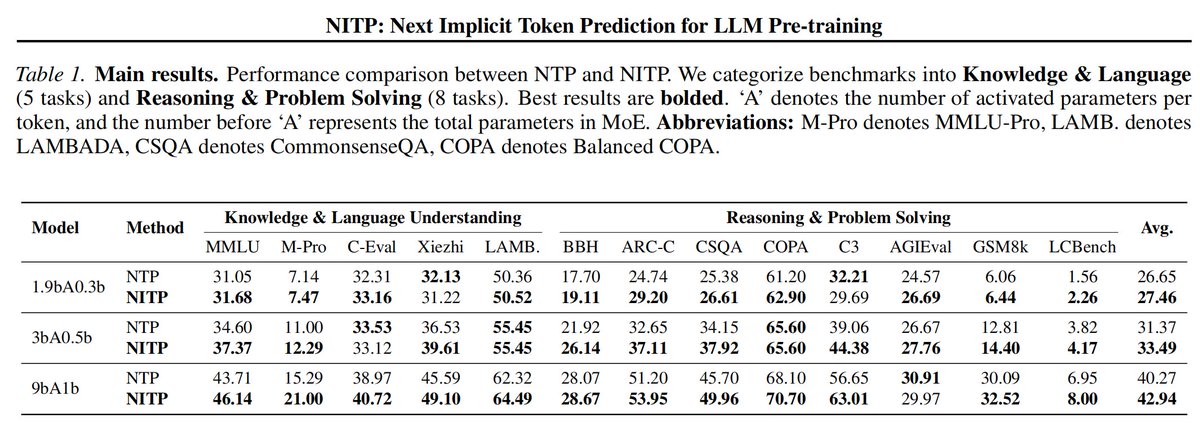
Next token prediction defines what to predict, but fails to supervise how predictions are represented.
We propose NITP: Next Implicit Token Prediction for LLM pre-training. NITP adds representation-level supervision to NTP.
GLM-5.2 is Fully Open, Frontier Intelligence Belongs to Everyone
Today, the sudden restriction of certain frontier models is deeply regrettable. At a time when access to frontier models is abruptly cut off for non-technical reasons, we are even more convinced of one thing: science should be global.
The path to AGI (Artificial General Intelligence) must never be enclosed by high walls. We have always believed that AGI should be the cornerstone for all of humanity to collaboratively explore the boundaries of intelligence and solve complex challenges, rather than a privilege monopolized by a few rules and subject to revocation at any moment. In the face of external blockades and restrictions, our attitude is one of radical openness. Frontier intelligence must remain open-source, accessible, and buildable, serving every dedicated developer.
GLM-5.2 is Zhipu's most capable open-source model to date. It not only supports a truly usable 1M context window but also maintains a continuous lead in the independent completion of long-horizon tasks, providing solid foundational support for building complex agent applications. It also continues to be our main engine for creating the strongest domestic coding model.
Tonight at 5:21—at this special moment—GLM-5.2 will officially be available to all GLM Coding Plan users (including Lite / Pro / Max). The API will also go live next week.
A step closer to frontier intelligence for everyone.
The future of AI is open, and it is for the people.
ModelKey: GLM-5.2
1/
We are scaling LLM optimizers completely wrong.
Applying uniform matrix orthonormalization (like in Muon) across all layers is wasting massive compute.
Early layers and final layers live in entirely different spectral dimensions as they scale. 🧵
If “negative interventions” can silently reduce a model’s effectiveness, users have a right to know when they are active.
If this becomes acceptable, how can we trust that Claude-generated code won’t be poisoned in the future to “obey” company policy?
As believers of open research, we are disappointed to see Anthropic silently degrading Fable 5 for AI development
"Any topic related to building pretraining pipelines, distributed training infrastructure, or ML accelerator design... may have limited effectiveness through Claude via methods such as prompt modification, steering vectors, or parameter-efficient fine-tuning."
Not only do they get to decide what you use LLMs for in research, but this also enables them to silently intervene in your research without you knowing.
This sets a dangerous precedent. If a model refuses openly, users can understand the boundary. If a model falls back to another model, users can still evaluate the difference. But if a model silently modifies or weakens its own answers while still pretending to help, researchers lose the ability to know whether a failed result came from their own idea, their implementation, or an invisible intervention by the model provider.
That is not safety. Safety policies should be transparent, auditable, and user-visible.
On top of that, the people most harmed by this are not the largest labs with massive teams and proprietary infrastructure. It is the independent researchers, academic groups, startups, and open-source builders who rely on public tools to compete, innovate, and pioneer AI for everyone else.
As believers of open research, we are disappointed to see Anthropic silently degrading Fable 5 for AI development
"Any topic related to building pretraining pipelines, distributed training infrastructure, or ML accelerator design... may have limited effectiveness through Claude via methods such as prompt modification, steering vectors, or parameter-efficient fine-tuning."
Not only do they get to decide what you use LLMs for in research, but this also enables them to silently intervene in your research without you knowing.
This sets a dangerous precedent. If a model refuses openly, users can understand the boundary. If a model falls back to another model, users can still evaluate the difference. But if a model silently modifies or weakens its own answers while still pretending to help, researchers lose the ability to know whether a failed result came from their own idea, their implementation, or an invisible intervention by the model provider.
That is not safety. Safety policies should be transparent, auditable, and user-visible.
On top of that, the people most harmed by this are not the largest labs with massive teams and proprietary infrastructure. It is the independent researchers, academic groups, startups, and open-source builders who rely on public tools to compete, innovate, and pioneer AI for everyone else.
🤔 Why do we still rely on the final layer of an LLM, when different layers encode different information? 🤔
In our new work, “Improving LLM Final Representations with Inter-Layer Geometry” (ICLR 2026 Workshop on Geometry-grounded Representation Learning and Generative Modeling) we show that actually, LLMs do not have one “best” layer.
We introduce the Cayley-Encoder: an efficient and effective geometric encoder that learns one strong representation from all layer representations of the LLM, without biasing the representation toward any specific layer.
While adding at most 0.1% learned parameters to the LLM, the Cayley-Encoder achieves large empirical gains over LoRA fine-tuning, final-layer representations, expensive attention-based aggregation, and methods that optimize specific layers for the task.
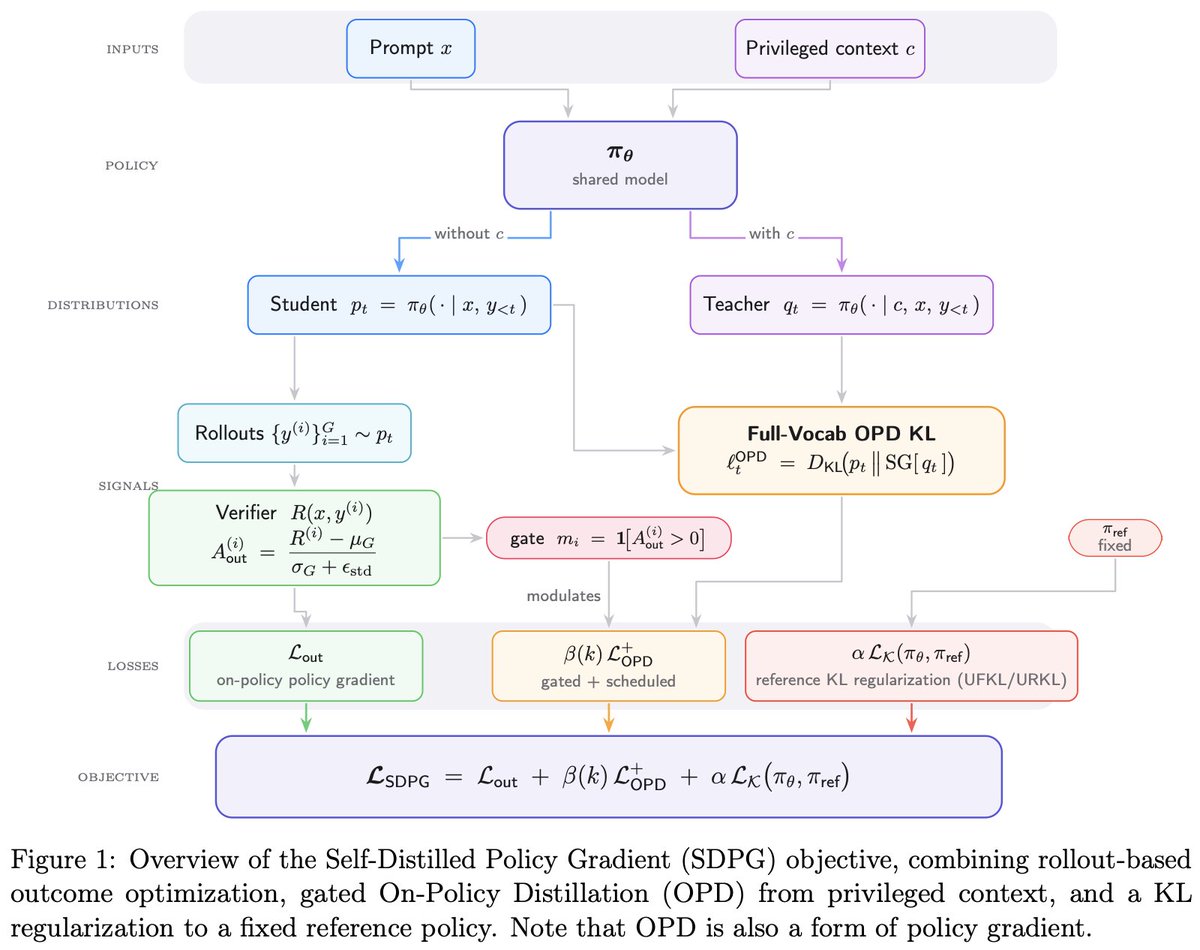
Introducing Self-Distilled Policy Gradient.
Token-level rewards, credit assignment, self-distillation.
RL and distillation are converging toward the same idea:
Policy gradients, it always has been, it always will be.
https://t.co/RJeRFUTeyz
Quoting @dlwh : we are at risk of losing the reputation of spiky loss runs!
This run incorporates some stability techniques from my past projects: Hyperball, Gated Norm, and Gated Attention. Excited to see the next run from Marin!
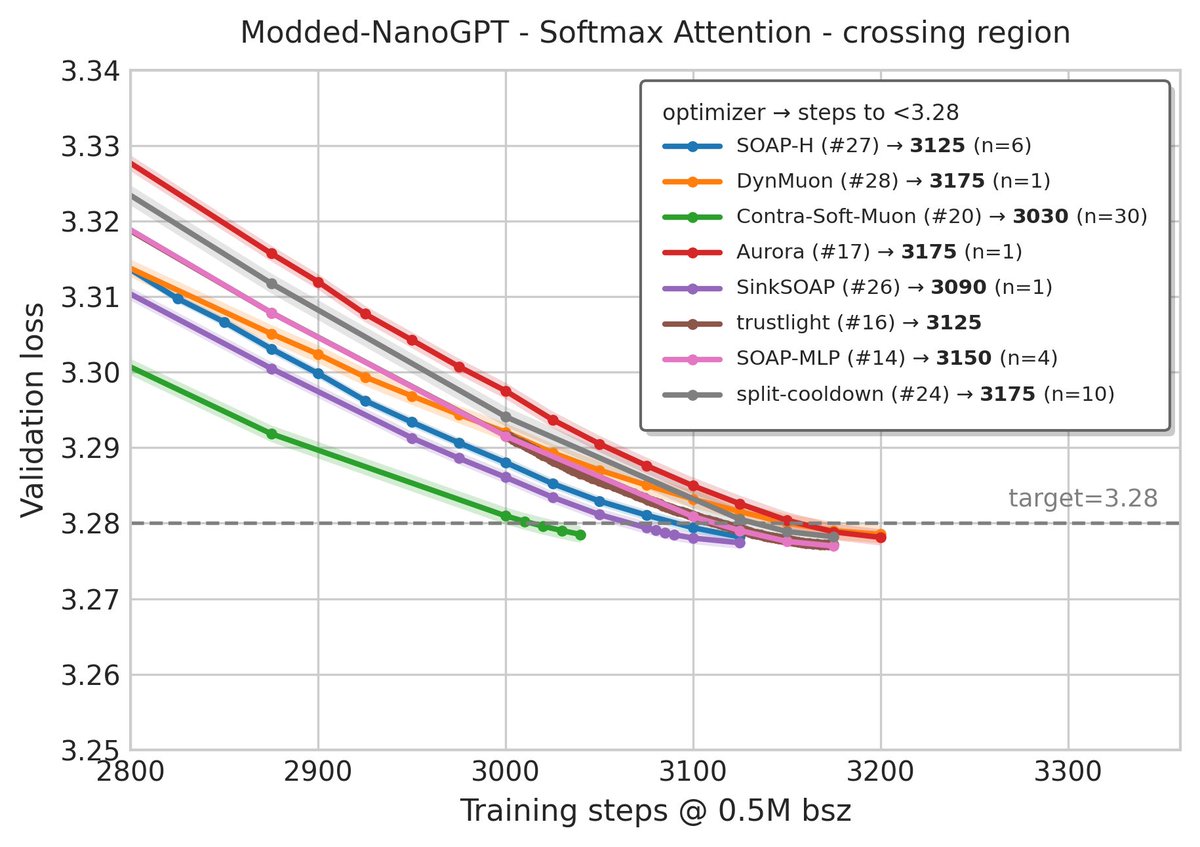
Very impressive results from Min Li and @Haoxiang__Wang: simply swapping Attention for Parallax reaches 2880 steps with the SOAP-H optimizer, beating the latest SOTA record on modded-nanogpt (@kellerjordan0) with no hyperparameter tuning.
A few observations:
- Parallax is uniformly stronger than Softmax Attention across all records.
- Optimizers don't transfer to Parallax with the same magnitude, which confirms the optimizer–architecture interaction from the Parallax paper.
- The cleanest modifications often transfer best; records built on heavy tuning transfer less reliably.
These are preliminary results, I believe both the Parallax architecture and the optimizer side have room to improve. Code is open-sourced below, give it a try.
Code: https://t.co/IINJ6MhRe0
Kernel: https://t.co/sxqGeknW4b
Paper: https://t.co/yAqClXrJUz
NITP has been submitted to HF Daily Papers😃. Upvotes and feedback are very welcome! https://t.co/mcLblkF72P
Implementation code will hopefully be released in the next two or three weeks.
By “central again,” I mean that representation quality should not just be a byproduct of next-token prediction. NITP is one attempt to make it more explicit, but the broader direction is much bigger: designing objectives that better structure the hidden space of LLMs.
This paper offers a perspective on why learning from latents can be more efficient than learning from raw tokens: the bottleneck may be not only data scale, but also the learning objective.
So we may need to make representation learning central again in LLMs. Not just NITP.
🎉ICML 2026 accepted
My first LLM pre-training paper:
Next Implicit Token Prediction (NITP)--A new language model pre-training paradigm
We move beyond discrete-only supervision of Next Token Prediction, adding implicit semantic supervision to fix representation degenration.
Reintroducing our ICML Oral paper: OPUS: Towards Efficient and Principled Data Selection in LLM Pre-training in Every Iteration.
When I first started working on pre-training, I had a rude awakening: most algorithms that look elegant in academic papers—no matter what awards they won—simply do not work at trillion-token scale with 1T-parameter models. Scale is the ultimate referee; all fancy guarantees collapse back to reality.
So I forced myself back to first principles. What does "good data" actually mean? How do we evaluate pre-training when next-token prediction cannot be judged by a simple benchmark? Can a validation proxy like perplexity reliably map to downstream scores? It sounds like ML 101, but at massive scale, this is surprisingly unresolved.
During my time at the Qwen team (starting from what now feels like the "ancient" Qwen2.5 era before Qwen3), I spent enormous effort on data mixture engineering. We designed stages, tuned domain ratios—some empirically driven, some numerically justified. But the uncomfortable truth is: 90% of data engineering is still human heuristic. It is craft, not science. I fully accept that LLM research is experimental science, but I constantly wanted to pursue something less dependent on human taste—in some sense, the bitter lesson for data selection.
So in OPUS, we honestly tackle four questions that had been bothering me for a while:
1️⃣ How do we define a good validation set that can actually guide data selection?
2️⃣ How do we define data quality scientifically—not by human preference, but by what the model itself structurally needs?
3️⃣ How do we select data based on the model's live weight updates at each iteration, rather than freezing human-designed stages? I want this to be online and adapt in real time.
4️⃣ How do we make all of this efficient and scalable?
The core philosophy: stop treating pre-training data as a static mixture designed by humans, and start treating it as a dynamic optimization problem where the model itself tells itself what to learn next.
Check our paper: https://t.co/bOtSWgxK2m
Code for GPT series: https://t.co/fgBa8lggtE
#Qwen3 #DataCentricAI #OPUS #ICML2026 #LLM #Pretraining #DataSelection #MachineLearning
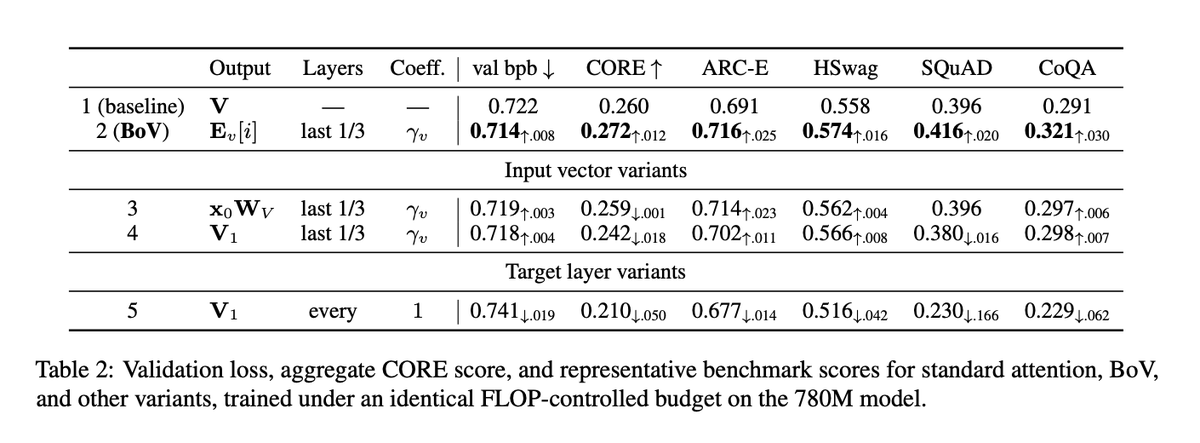
Interesting paper. It reminds us again that different layers can play very different roles in LLMs, which is also related to how NITP treats shallow-layer representations as targets for deeper layers.
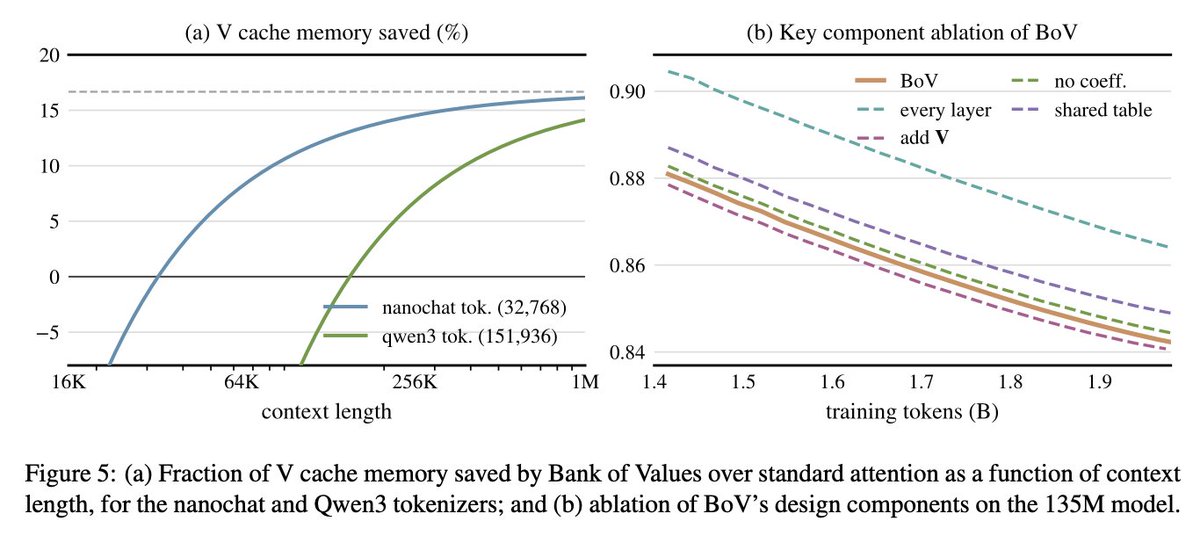
In our new paper, we naturally derive a new attention variant based on the surprising finding that deep layers benefit the most from learning a context-free value vectors, without the input from the residual stream.
The attention variant: since the value vector does not depend on the context, it can be directly learned as sparse model parameter, and stored in a table of value vectors for the current layer.
The idea of having a value vector table is not new. Nanochat, for example, has it. But it was always learned as an extra group of weights to add to the existing value vector. With the insight that the deep layer **only** need a context-free vector, we can rewrite attention completely, by making the table the only source of value vectors.
On two model sizes we see that it significantly outperforms the standard attention baseline on both validation loss and benchmark scores, and slightly surpasses the strictly more expressive nanochat variant.
Besides the boost in performance, some very interesting consequences emerge in terms of memory:
- We do not need V cache anymore for the deep layers, and at long context it saves memory.
- Because we only need the token IDs for fetching value vectors, we can offload the table entirely, and just prefetch the relevant entries when previous layers are busy computing.
Me and @YuchenL52766559 are fascinated by this attention architecture's unique properties, and are doing experiments on bigger scales with it.
Paper: https://t.co/oFaXEx9Upx
@jayden_teoh_ Very interesting — the transition-consistency angle is especially nice. My read is that this is closer to learning a compact belief-state / world-model inside the transformer, whereas NITP is more about adding geometric supervision to the representation space.
Paper is now released: https://t.co/vhkRlEfsoX
Next token prediction defines what to predict, but fails to supervise how predictions are represented.
We propose NITP: Next Implicit Token Prediction for LLM pre-training. NITP adds representation-level supervision to NTP.
Paper is now released: https://t.co/vhkRlEfsoX
Next token prediction defines what to predict, but fails to supervise how predictions are represented.
We propose NITP: Next Implicit Token Prediction for LLM pre-training. NITP adds representation-level supervision to NTP.
@hilbertmeng Hi! MTP still supervises future tokens in logit space with one-hot targets, while NITP supervises temporally shifted implicit representations in hidden space. So by design, their gains are not necessarily overlapping, and we expect NITP to remain complementary under MTP.
@zhudefa Thanks for your attention! In our experiments, NITP does not affect the LM/NTP loss, but it does noticeably improve representation quality (such as results in MTEB) :)