Here's the new Clicky.
It's the simplest interface in the world to talk to AI + spawn agents.
It builds Mac apps. It does research to help you find IG micro-influencers. It interacts with native Apple Notes, Calendar, Reminders.
Built for consumers, 0 setup.
Try today, free.
solid breakdown. the insight that stuck with me: users want better output, not faster. I've seen this firsthand — added a default prompt in cursor to ask clarifying questions before jumping in. takes a bit longer but the output quality jumped way up
We are hiring a bunch of Members of the Technical Staff for @GoogleAIStudio who can blend PM, design, eng, and more
If this is you, pls DM me, we will move fast for the best people.
We are hiring product engineers, enterprise product engineers, enterprise product manager, platform engineers.
If you want to build the future of agents, join us.
Retweet as a friend otherwise.
Why is no one talking about this?
@nvidia is offering around 80 AI models via hosted APIs absolutely for free.
You get access to MiniMax M2.7, GLM 5.1, Kimi 2.5, DeepSeek 3.2, GPT-OSS-120B, Sarvam-M etc.
This plugs straight into OpenClaude, OpenCode, Zed IDE, Hermes agent and even with Cursor IDE.
Setup:
– Grab API key: https://t.co/Wfdclm0hY2
– base_url = "https://t.co/VOGC10LmGP"
– api_key = "$NVIDIA_API_KEY"
– select model (e.g. minimaxai/minimax-m2.7)
If you’re building or experimenting, this is basically free inference.
Lock in and start building today anon.
Thank me later.
As coding agents have become the standard for developing software, we've transformed Sierra's engineering interview process to be AI-native. We've documented our lessons here, and very curious how others in the industry are navigating https://t.co/xbqM5bzvUg
Introducing Claude Design by Anthropic Labs: make prototypes, slides, and one-pagers by talking to Claude.
Powered by Claude Opus 4.7, our most capable vision model. Available in research preview on the Pro, Max, Team, and Enterprise plans, rolling out throughout the day.
Harness, Memory, Context Fragments, & the Bitter Lesson
this is a work in progress mental dump on interesting intersections between how we use and design a harness, implications for memory being accumulated over long timescales, and the search bitter lesson we can’t escape
this is v30+, HTML diagrams help me iteratively refine + chat to roughly “see” and alter the mental model
Harnesses & Context Fragments:
a very important job of the harness is to efficiently & correctly route data within its boundaries into the context window boundary for computation to happen
the context window is a precious artifact. Harnesses make decisions on how to populate, manage, edit, and organize it so agents can do work. Each loaded object can be thought of as a Context Fragment and represents an explicit decision by the user and harness designer of what needs a model needs to do work at any given time.
many ideas on externalizing objects + loading into the context window are pioneered and very well described by @a1zhang with RLMs
Experiential Memory:
we’re in the very early days of deploying agents and agents produce massive amounts of data in every interaction they have. this is akin to humans doing things and remembering things they did.
however agent memory has a massive advantage as it can be accumulated across all agents which are easily forked and duplicated (unlike humans). @dwarkesh_sp does a good talking about this massive benefit of artificial systems
memory can be treated as an externalized object. the harness is tasked with doing good contextualized retrieval which means pulling in the right data from accumulated memories across all agent interactions
Search & The Bitter Lesson:
As we deploy agents in our world over year timescales, there is going to be a hyper-exponential in the amount of data produced by those agents. We should want to:
1. Own that data for ourselves. Open ecosystems are important here
2. Use that data
This means that we’ll have to search over, distill, and organize massive amounts of data. Our brain is exceptional at doing this. Both contextually using prior experience and mostly committing the right stuff to memory with enough intentional practice.
Our current infrastructure systems and algorithms will be put to the test and often break as we get used to this new data regime
some open questions:
- how do we efficiently distill experiences (Traces) into higher level memory primitives that capture the important parts? How do we do this over ultra long time horizons?
- How much of the future is Search just-in-time vs Search that gets integrated into model weights?
- How do we make models much better at self-managing their context window? How do we reduce error rates in recursively allowing agents to operate over external objects?
i’ll be expanding on, altering, and adjusting these mental models but these feel like an important subset to me on the future of designing agents practically
Judging by my tl there is a growing gap in understanding of AI capability.
The first issue I think is around recency and tier of use. I think a lot of people tried the free tier of ChatGPT somewhere last year and allowed it to inform their views on AI a little too much. This is a group of reactions laughing at various quirks of the models, hallucinations, etc. Yes I also saw the viral videos of OpenAI's Advanced Voice mode fumbling simple queries like "should I drive or walk to the carwash". The thing is that these free and old/deprecated models don't reflect the capability in the latest round of state of the art agentic models of this year, especially OpenAI Codex and Claude Code.
But that brings me to the second issue. Even if people paid $200/month to use the state of the art models, a lot of the capabilities are relatively "peaky" in highly technical areas. Typical queries around search, writing, advice, etc. are *not* the domain that has made the most noticeable and dramatic strides in capability. Partly, this is due to the technical details of reinforcement learning and its use of verifiable rewards. But partly, it's also because these use cases are not sufficiently prioritized by the companies in their hillclimbing because they don't lead to as much $$$ value. The goldmines are elsewhere, and the focus comes along.
So that brings me to the second group of people, who *both* 1) pay for and use the state of the art frontier agentic models (OpenAI Codex / Claude Code) and 2) do so professionally in technical domains like programming, math and research. This group of people is subject to the highest amount of "AI Psychosis" because the recent improvements in these domains as of this year have been nothing short of staggering. When you hand a computer terminal to one of these models, you can now watch them melt programming problems that you'd normally expect to take days/weeks of work. It's this second group of people that assigns a much greater gravity to the capabilities, their slope, and various cyber-related repercussions.
TLDR the people in these two groups are speaking past each other. It really is simultaneously the case that OpenAI's free and I think slightly orphaned (?) "Advanced Voice Mode" will fumble the dumbest questions in your Instagram's reels and *at the same time*, OpenAI's highest-tier and paid Codex model will go off for 1 hour to coherently restructure an entire code base, or find and exploit vulnerabilities in computer systems. This part really works and has made dramatic strides because 2 properties: 1) these domains offer explicit reward functions that are verifiable meaning they are easily amenable to reinforcement learning training (e.g. unit tests passed yes or no, in contrast to writing, which is much harder to explicitly judge), but also 2) they are a lot more valuable in b2b settings, meaning that the biggest fraction of the team is focused on improving them. So here we are.
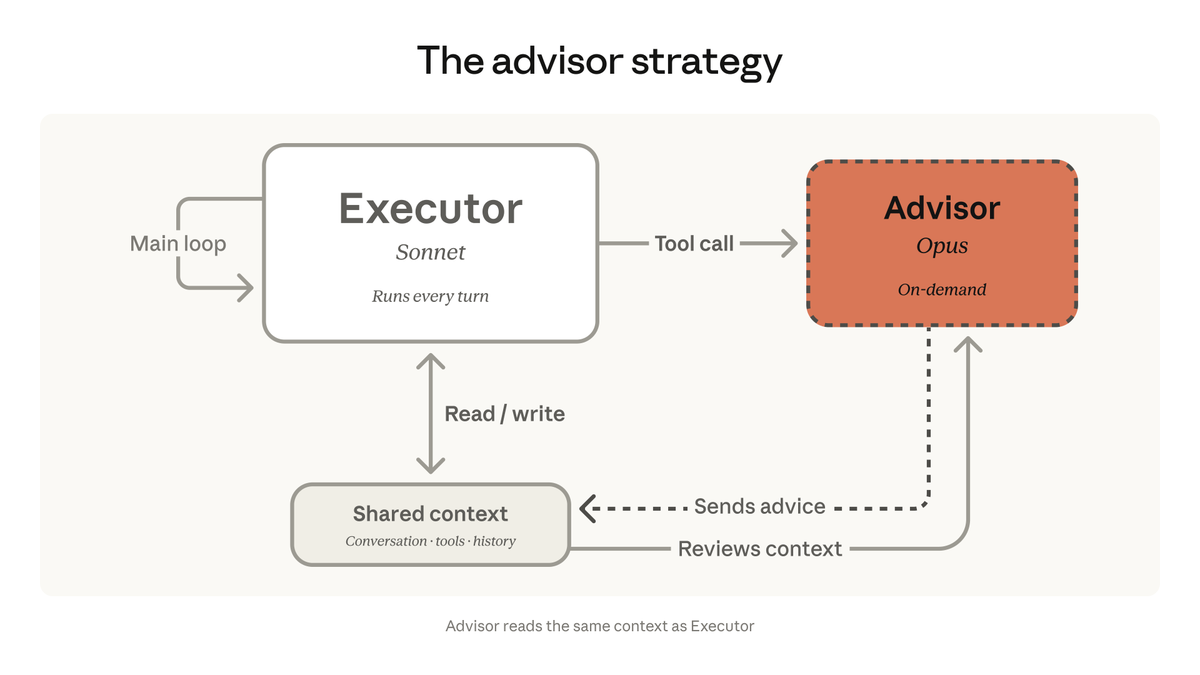
We're bringing the advisor strategy to the Claude Platform.
Pair Opus as an advisor with Sonnet or Haiku as an executor, and get near Opus-level intelligence in your agents at a fraction of the cost.
Just got a nice DM from a big enterprise customer using Claude Code in one of the world's biggest codebases
Here's how we made @-mentions 3x faster in large enterprise codebases 🧵
Hey, I'm open-sourcing Clicky.
Go forth into the wild and build the future of education and the future of AI interfaces, my friends. I'm happy to have given a spark.
Enjoy!
https://t.co/x1gR0dib1p
- Chinese o/w models are the stealth story in Indian enterprise
- Marketing is the 2nd biggest AI use case after coding
- Everyone is doing a re-org, but it's not what you think
- Customer Support ROI is already proven
- Accuracy beats cost as the #1 blocker to scale
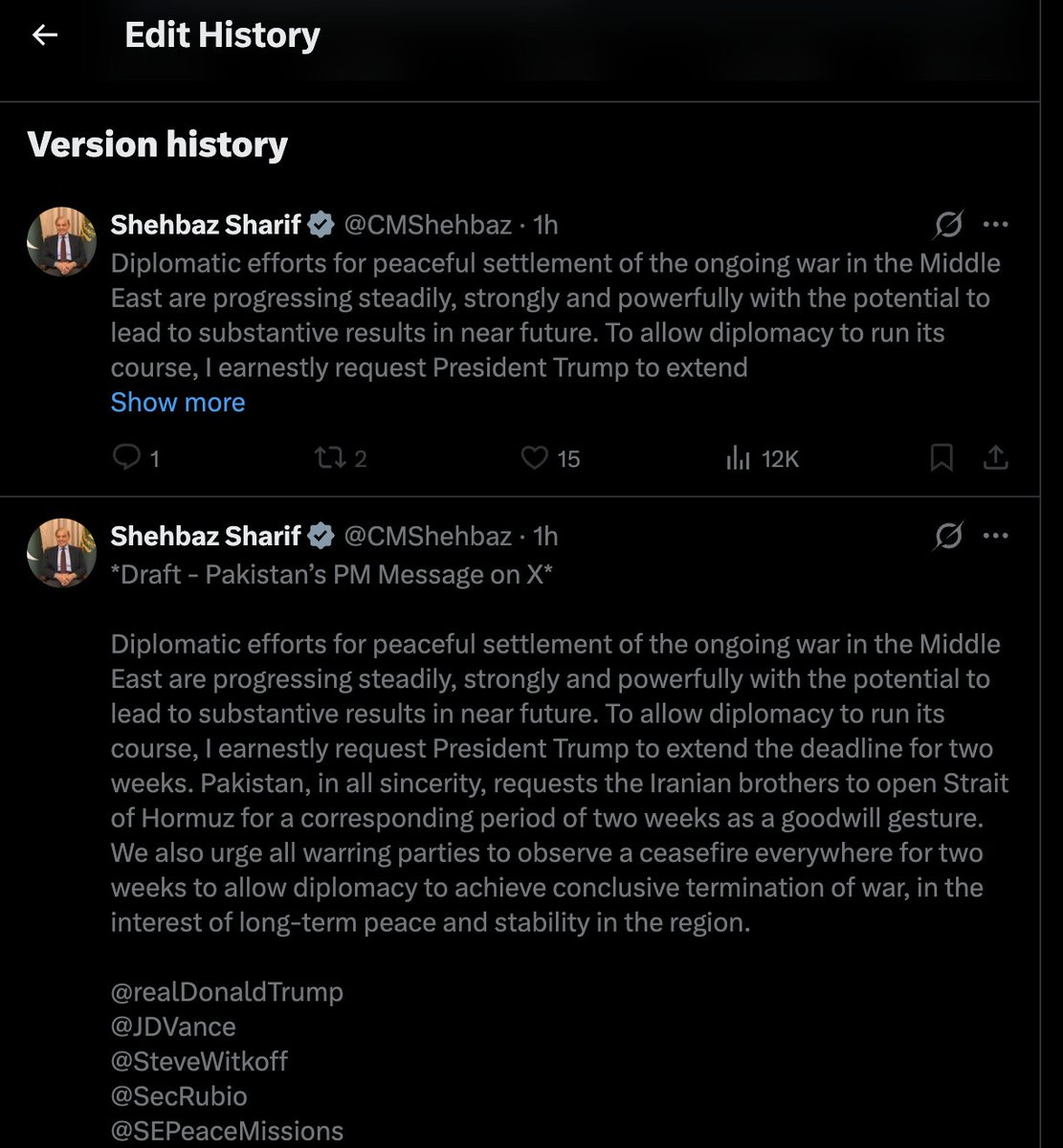
Oh, this is unbelievable. The edit history on this tweet shows that Pakistan Prime Minister Shehbaz Sharif originally copied and pasted everything he was sent, including:
"*Draft - Pakistan's PM Message on X*"
Now, obviously, Sharif's own staff don't call him "Pakistan's PM," they would just call him prime minister. The U.S. and Israel, of course, would call him "Pakistan's PM."
Would be funny if the fate of the world wasn't hanging in the balance.
Wow, this tweet went very viral!
I wanted share a possibly slightly improved version of the tweet in an "idea file". The idea of the idea file is that in this era of LLM agents, there is less of a point/need of sharing the specific code/app, you just share the idea, then the other person's agent customizes & builds it for your specific needs.
So here's the idea in a gist format: https://t.co/NlAfEJjtJV
You can give this to your agent and it can build you your own LLM wiki and guide you on how to use it etc. It's intentionally kept a little bit abstract/vague because there are so many directions to take this in. And ofc, people can adjust the idea or contribute their own in the Discussion which is cool.
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
When @karpathy built MenuGen (https://t.co/2OjrUJ3aLS), he said:
"Vibe coding menugen was exhilarating and fun escapade as a local demo, but a bit of a painful slog as a deployed, real app. Building a modern app is a bit like assembling IKEA future. There are all these services, docs, API keys, configurations, dev/prod deployments, team and security features, rate limits, pricing tiers."
We've all run into this issue when building with agents: you have to scurry off to establish accounts, clicking things in the browser as though it's the antediluvian days of 2023, in order to unblock its superintelligent progress.
So we decided to build Stripe Projects to help agents instantly provision services from the CLI.
For example, simply run:
$ stripe projects add posthog/analytics
And it'll create a PostHog account, get an API key, and (as needed) set up billing.
Projects is launching today as a developer preview. You can register for access (we'll make it available to everyone soon) at https://t.co/1tSgGbSLxM. We're also rolling out support for many new providers over the coming weeks. (Get in touch if you'd like to make your service available.)
https://t.co/vjRymcVCKI