New blog post on @huggingface!
An introdution to Trimming ✂️ a little-known but highly effective model reduction method. We achieved up to 87.24% size reduction while preserving performance 🧵
New blog post on @huggingface!
An introdution to Trimming ✂️ a little-known but highly effective model reduction method. We achieved up to 87.24% size reduction while preserving performance 🧵
Introducing a revival of PapersWithCode!
As @ilyasut said, we're back to the "age of research".
Hence, it's important to share research and build on each other's work.
> find SOTA per domain, not just LLMs
> leaderboards
> methods
> all parsed at scale using AI agents.
🌐 I've just released Sentence Transformers v5.4: we're going fully multimodal for embeddings & reranking!
Also featuring a modular CrossEncoder, and automatic Flash Attention 2 input flattening.
Highlights in 🧵
CuTeDSL is really nice
For those wishing to get into writing kernels in this language, https://t.co/7fjj26yj0F can be useful
Boris ALBAR reimplemented Flash Attention, RoPE, RMSnorm, etc.
Everything compatible with HF Transformers (tests on llama3, GLM4.7, Qwen3), TRL, PEFT/LoRA
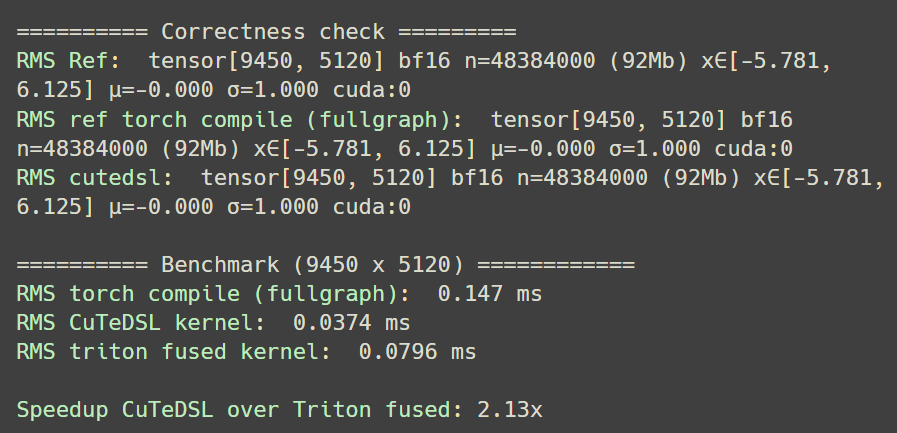
CuTeDSL is my new favourite thing: I wrote a kernel for RMS norm after learning about layouts, tiling, copying tensors, reductions and so on, especially for inference and it is about 2.13x faster than a triton fused kernel for the given shape.
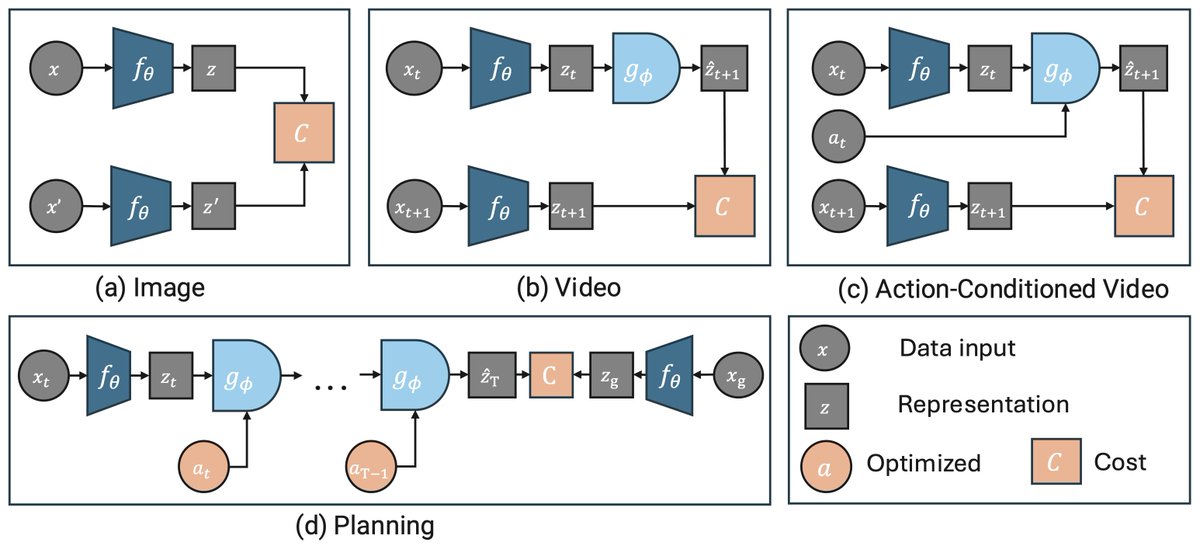
𝗜𝗻𝘁𝗿𝗼𝗱𝘂𝗰𝗶𝗻𝗴 𝗘𝗕-𝗝𝗘𝗣𝗔 ⚡
An open-source library making JEPAs accessible, trainable on a single GPU in hours! 🚀
🔗 Paper: https://t.co/7YDSt0AiiA
💻 Code: https://t.co/KWkhcoDidU