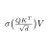A book full of recipes to solve common NLP & computer vision tasks:
https://t.co/5ltyC0vHqX
Discusses the following libraries:
- @huggingface transformers, datasets, accelerate, @Gradio
- @PyTorchLightnin
- @wandb
- pytorch image models(timm)
- albumentations
microsoft MAI tech report is a gold mine, one of the most transparent for a model at this scale.
this model uses zero synthetic data or distillation from previous models. this means reasoning, agentic behavior, tool use are all learned fully during post-training with no cold start. bold choice that makes it harder and requires more iterations to reach sota, but you get FULL control over your model series and it proves they are serious about being a frontier lab.
the tech report is insanely detailed and precise about numbers. to give an example, they give the exact MFU across all the iterations of the model, with the exact changes etc. they also share the full scaling ladder recipe, to my knowledge this is the first time i've seen this in a tech report at this scale
let's look at all of this in this likely very long thread 🧵
For over a decade, we’ve accepted that end-to-end backprop is the only way to train deep networks. But holding the entire network in memory all at once is why AI training is hitting a resource wall.
We found a new way to break the network into blocks and train them independently. The trick? Treating the network’s forward pass like a diffusion model denoising a signal.
This reinterpretation slashes the memory needed to train deep models. In our #ICLR2026 paper (https://t.co/PK5h0mqQSo), we matched end-to-end performance across ViTs, DiTs, and LLMs. We did this while training just one isolated block at a time.
Welcome, AlphaChip!
Today, we are sharing some exciting updates on our work published in @Nature in 2021 on using reinforcement learning for ASIC chip floorplanning and layout. We’re also naming this work AlphaChip.
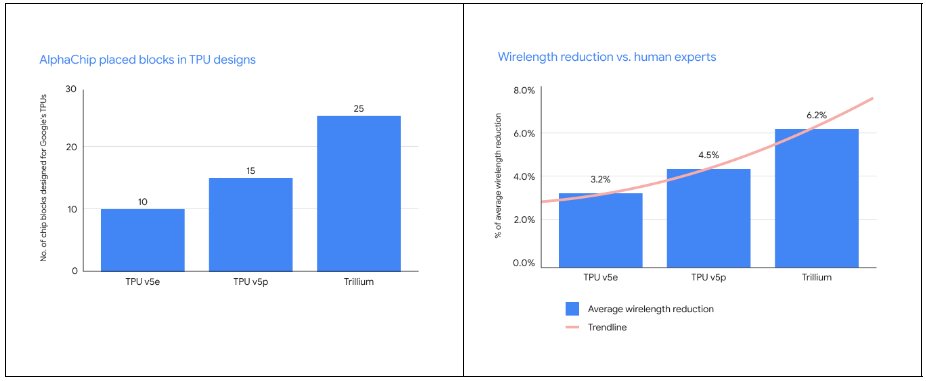
Since we first published this work, our use of this approach internally has grown significantly. It has now been used for multiple generations of TPU chips (TPU v5e, TPU v5p, and Trillium), with AlphaChip placing an increasing number of blocks and with larger wirelength reductions vs. human experts from generation to generation:
AlphaChip has also been used with excellent results for other chips across Alphabet, including Google’s Axion chip, an Arm-based general-purpose data center CPU.
In 2022, as a companion to the Nature paper, we open-sourced the code for the AlphaChip algorithms described in the Nature paper (see link below). Since then, external researchers could use this repository to pre-train on a variety of chip blocks and then apply the pre-trained model to new blocks, as was done and described in our original paper.
Today we’re also releasing a pre-trained AlphaChip checkpoint for the open source release that makes it easier for external users to get started using AlphaChip for their own chip designs.
Original Nature paper w/ wonderful joint first authors @Azaliamirh + @annadgoldie, and @mnyazgan, @joesmemory, @ESonghori, @ShenWangURC, @xylophi, @efjohnson, @pathomkar, @Azade_na, @PakJiwoo, Andy Tong, @kavyasrinivas23, @willhang_, @emretuncer, @quocleix, @JamesLaudon, @rh00, Roger Carpenter, and myself):
https://t.co/QmJA56ZKOE (PDF: https://t.co/HP7y1LhAh4)
Today’s Addendum to the paper published in Nature: https://t.co/BuGacrq57J (same authors)
AlphaChip blog post: https://t.co/oLBq1J8oXj
Open source release: https://t.co/cW1YMSHI57
Pre-trained checkpoint: https://t.co/iXtLqEjsH3
Three things we have observed in the external community are described in the Nature Addendum: (1) not doing any pre-training (circumventing the learning aspects of our method by removing its ability to learn from prior experience) (2) not training to convergence (standard practice in ML methods), and (3) using fewer computational resources than described in our Nature paper (using fewer resources is likely to harm performance, or require running for considerably longer to achieve the same performance).
Pre-training the model for it to learn the craft of chip layout and to be able to generalize to new designs is an important part of our method. The pre-training process requires some effort to perform, since one has to find representative blocks and then run a lengthy computational process to pre-train the model to be good at placing those blocks. To avoid external users having to perform this process and make it easier for the external community to use AlphaChip, today we are releasing an AlphaChip model checkpoint pre-trained on 20 TPU blocks. This will enable users to get good zero-shot performance and faster convergence for novel blocks right out of the box. (For best results, however, we continue to recommend that developers pre-train on their own in-distribution blocks, and we provide a tutorial on how to perform pre-training with our open-source repository: see the Addendum).
Many organizations have used AlphaChip as a building block for their own chip design efforts. For example, MediaTek, one of the top chip design companies in the world, extended AlphaChip to accelerate development of their most advanced chips (e.g. the Dimensity Flagship 5G used in Samsung mobile phones), while improving power, performance and chip area.
We’re very excited about the increasing impact of AlphaChip internally and externally, and we look forward to continued work in this space to make custom higher performance, more efficient, and more capable chips dramatically easier to design and build.
We implemented @karpathy 's MicroGPT fully on FPGA fabric.
No GPU.
No PyTorch.
No CPU inference loop.
Just a transformer burned into hardware, generating 50,000+ tokens/sec.
The model is small, but the idea is not: inference does not have to live only in software 👇
Modern Transformer architecture explained
I compiled a list of videos on the Transformer architecture into a short "YouTube course".
Hopefully, this would be helpful for beginners in the community. 🧵
Deepseek got called out for scraping 150k Claude messages. So I'm releasing 155k of my personal Claude Code messages with Opus 4.5.
I'm also open sourcing tooling to help you fetch your data, redact sensitive info & make it discoverable on HF - link below to liberate your data!
I'm Boris and I created Claude Code. I wanted to quickly share a few tips for using Claude Code, sourced directly from the Claude Code team. The way the team uses Claude is different than how I use it. Remember: there is no one right way to use Claude Code -- everyones' setup is different. You should experiment to see what works for you!
GPU MODE 2026: we’re post-training Kernel LLMs in public and are building all the infra we need to make GPU programming more accessible to all. We're doing this in close collaboration with some of my favorite communities @PrimeIntellect@modal and @LambdaAPI
2025 recap: 26K YouTube subs, 92 lectures, 24K Discord, 3x $100K+ kernel comps, 400K KernelBot submissions,3 events (NVIDIA / Jane Street / Accel) and 10 active working groups!
So for 2026 our concrete goal is to post-train a Kernel LLM and get kernels merged into real repos (PyTorch / vLLM). We plan to share our first results by GTC (San Jose, March 2026). second by ICML (Seoul, July 2026).
work-stream 1: de-slopify LLM kernels (with PyTorch / vLLM / NVIDIA). most generated kernels are verbose, fragile, and non-deterministic. the bar is “maintainer can review + merge”
work-stream 2: post-training Kernel LLM (with Prime Intellect / Modal / Lambda / MIT). We’re betting on two levers: profiler-guided optimization + memory
work-stream 3: competitions as evals. We want more end-to-end system optimizations, they're trickier to design good problems for but the results will be more interesting
work-stream 4: “from scratch” repos. Think: 80% of the performance with 10% of the code (teenygrad, penny ) starting with a minimal RL library optimized for B200
2026 is the year we turn Kernel LLMs from a meme into one of the most reliable ways of improving the performance of AI systems. So if you're interested please join our weekly meetings!
curious about the training data of OpenAI's new gpt-oss models? i was too.
so i generated 10M examples from gpt-oss-20b, ran some analysis, and the results were... pretty bizarre
time for a deep dive 🧵
Here are 5 practical tips for Context Engineering, which apply to @GoogleDeepMind Gemini 2.5 as well from @manusai!
1. Context Ordering Matters: Try to use "append-only" context, adding new information to the end. This maximizes cache hits reducing cost (4x) and latency.
2. Manage Tools Statically: Avoid changing tool order or availability mid-task, if not explicitly needed. This might break context caching and can/will confuse models if used tools in the history are no longer defined.
3. Use External Memory: Write explicitly or implicitly context/goals to external storage to. Preventing information loss. A typical task in Manus requires around 50 tool calls on average.
4. Recite Goals to not get lost: Prevent the model from "getting lost" by having it periodically restate its objectives. This keeps the primary goal in its recent attention span.
5. Embrace Errors: Keep error messages in the context. This allows the model to learn from its mistakes and avoid repeating them.
Oh wow, did you guys know that torch.compile can compile numpy code? And even run it on GPU?
This is pretty neat for all kinds of "surrounding" code besides the model (like evals and fancy metrics) that I used to do with numba/numexpr (cuz CPU-XLA was pretty meh).
Poll below
When I was optimising ULMFiT, I came up with a trick where I ran lots of ablations and fed all the hyperparams and results to a random forest. That told me which were most important.
I told @l2k about it, and @wandb added it to their product! :D
https://t.co/iCt92Bfc7f
What would truly open-source AI look like? Not just open weights, open code/data, but *open development*, where the entire research and development process is public *and* anyone can contribute. We built Marin, an open lab, to fulfill this vision:
Still relying on OpenAI’s CLIP — a model released 4 years ago with limited architecture configurations — for your Multimodal LLMs? 🚧
We’re excited to announce OpenVision: a fully open, cost-effective family of advanced vision encoders that match or surpass OpenAI’s CLIP and Google’s SigLIP on multiple multimodal benchmarks! 🏆
Plus, we’re releasing 25+ model configurations (sizes from 5.9M to 632M parameters, various input resolutions & patch sizes) to fit every need.
👇 Thread:
Introducing Mistral AI Classifier Factory! 🚀
We've created a user-friendly and simple way to build your own classifiers. Utilize our small yet highly efficient models and training methods to develop custom classifiers for moderation, intent detection, sentiment analysis, data clustering, fraud detection, spam filtering, recommendation systems, and more.Check out our docs and cookbooks for details.
Check out our docs and cookbooks for details 🧵:
Announcing fasttransform: a Python lib that makes data transformations reversible/extensible. No more writing inverse functions to see what your model sees. Debug pipelines by actually looking at your data.
Built on multi-dispatch. Work w/ @R_Dimm
https://t.co/OGDrBFhnfP
We made 5 challenges and if you score 47 points we'll offer you $500K/year + equity to join us at 🦥@UnslothAI!
No experience or PhD needed.
$400K - $500K/yr: Founding Engineer (47 points)
$250K - $300K/yr: ML Engineer (32 points)
Challenges:
1. Convert nf4 / BnB 4bit to Triton
2. Make FSDP2 work with QLoRA
3. Remove graph breaks in torch.compile
4. Help solve Unsloth issues!
5. Memory Efficient Backprop
If you have any questions about the challenges, please feel free to ask! We're looking for people to help push Unsloth forward - so come join us to democratize AI further!
Our past work includes:
1. 1.58bit DeepSeek R1 GGUFs: https://t.co/gALGkUg5Cg
2. GRPO with Llama 3.1 8B in a Colab: https://t.co/LFdkNxwAYg
3. Gemma bug fixes: https://t.co/7kX94PyKQR
4. Gradient accumulation bug fixes: https://t.co/Tq4c5Qwqyw
Details & submission guide: https://t.co/iXxRUTijWV
After 6+ months in the making and burning over a year of GPU compute time, we're super excited to finally release the "Ultra-Scale Playbook"
Check it out here: https://t.co/dekxY4BQZO
A free, open-source, book to learn everything about 5D parallelism, ZeRO, fast CUDA kernels, how and why overlap compute & communication – all scaling bottlenecks and tools introduced with motivation, theory, interactive plots from our 4000+ scaling experiments and even NotebookLM podcasters to tag along with you.
- How was DeepSeek trained for $5M only?
- Why did Mistral trained an MoE?
- Why is PyTorch native Data Parallelism implementation so complex under the hood?
- What are all the parallelism techniques and why were they invented?
- Should I use ZeRO-3 or Pipeline Parallelism when scaling and what's the story behind both techniques?
- What is this Context Parallelism that Meta used to train Llama 3? Is it different from Sequence Parallelism?
- What is FP8? how does it compares to BF16?
In this book, our goal was to gather, in a single place, a coherent, easy to read yet detailed story of all the techniques that make today's LLM scaling possible.
The largest factor for democratizing AI will always be teaching everyone how to build AI and in particular how to create, train and fine-tune high performance models. In other word making accessible to everybody the techniques that power all recent large language models and efficient training is possibly one of the most essential of them.
What started as a simple blog-post ended up becoming an interactive writing piece containing 30k+ words. So we've decided to actually print it as a real 100-pages physical book as well: the physical ultrafast playbook –containing all the science of distributed and fast AI training.
We plan to send free copies as gifts to the first readers of the online version so feel free to add your email in the form linked in the blog post.