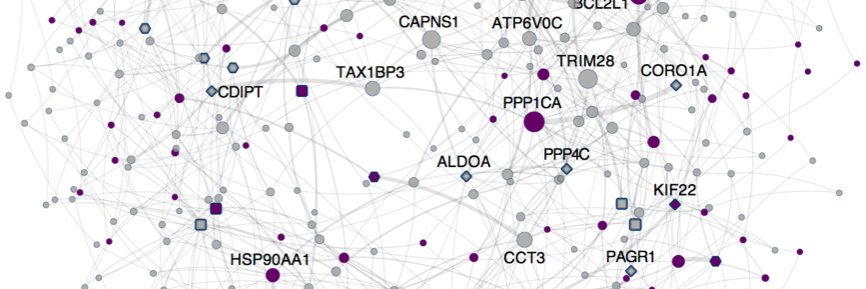
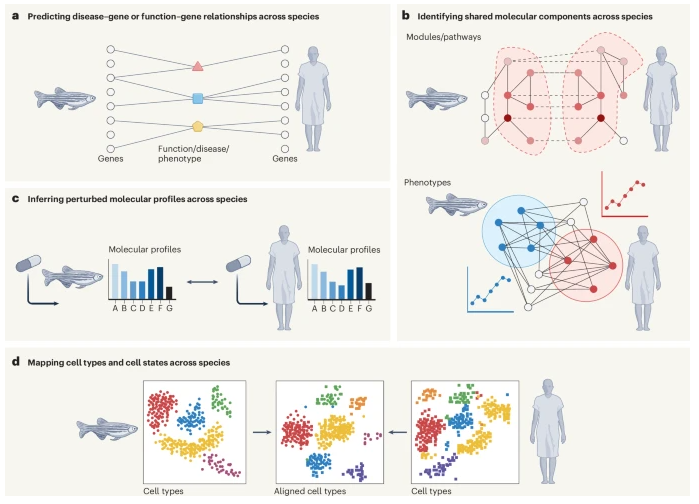
ML & data-driven discovery; Complex traits & diseases; Data reuse & open science.
Associate Professor | Group leader @KrishnanLab | @compbiologist everywhere
Preprint 🚨
A review state-of-the-art computational strategies for cross-species knowledge transfer in biomedicine
💻👩🦰🐭🐟🪰🪱🧬🫁⚕️
Led by an excellent team at @KrishnanLab: @yhbioinfo, @ChrisAMancuso, & @kaylainbio in collab w/ @FishEvoDevoGeno 🧵
https://t.co/nbVdKALnXm
Thanks for the link, interesting post by @blekhman, lots of good points!
@compbiologist: "the best model is usually the one that is consistently number 2 in benchmarks across the literature." - Yes, it's Goodhart's curse, overoptimization for narrow targets will fail. (Though in more general GenAI domains, the problem is even harder because all the benchmarks are getting saturated as well!)
On the importance of evaluations, the newer work on improving eval practices and reporting - @EvalConsensusAI / @evaluatingevals - seems likely to be relevant, though it needs to be adapted to bio models. Seems like a good place to continue exploring; both Noga Aharony and Reut Danino are separately interested in related issues; we should put something together on this!
There are also a number of points in our RAND report that I think are touched upon, especially about prediction vs. validation, and about metadata (i.e. our discussion of the problem of multimodal data and integrating data;) https://t.co/JyPFL66MhH
And one last point - "a recurring theme... was that ignoring theory and history is a mistake" - that sounds like the bitter lesson isn't supposed to apply here; I remain skeptical. But as the Delphi explored, there may be fundamentally too little data in this domain to brute force answers; @alexijielu's approaches with self-supervision seem to be trying to address this. (And given that he's working to characterize limitations of current AI methods, I really wish we had gotten him into the Delphi Panel for our study!)
@curiouswavefn@lpachter Absolutely!
Expanded thoughts are here:
Build expertise first: why PhD training must sequence AI use after foundational skill development
https://t.co/XfwAjhr34y
Peer review reliability is shockingly low. Meta-analyses show reviewer agreement barely above chance, and grant outcomes often depend more on who reviews than what's proposed. Our new preprint: https://t.co/kpp30e7mDY 🧵 1/
Excited to share this work. A huge effort from many team members, led by former @CUHMGGP PhD student and current @CrnicInstitute Post-doc, Dr. Lauren Dunn!
Altered hepatic metabolism in Down syndrome: Cell Reports https://t.co/StnYBOO8Sz
The call for poster abstracts for the 6th International Conference of the Trisomy 21 Research Society is now open! Conference registration for the conference, to be held June 17-20 2026 in Denver, CO, USA, is open as well.
https://t.co/cOSZYDiHiw
Preprint 🚨
A review state-of-the-art computational strategies for cross-species knowledge transfer in biomedicine
💻👩🦰🐭🐟🪰🪱🧬🫁⚕️
Led by an excellent team at @KrishnanLab: @yhbioinfo, @ChrisAMancuso, & @kaylainbio in collab w/ @FishEvoDevoGeno 🧵
https://t.co/nbVdKALnXm
@baym I actively tell students in my class that we're never going to use those terms, just FP, FN, TP, TN, & their rates, and for good measure, show @drob's tweet: https://t.co/L20MWlhIdD
As a fan of the super @nightsciencepod (highly recommend it!), I enjoyed listening to the latest episode of another favorite — Work Life — where @AdamMGrant talks to @nathanmyhrvold about invention & creativity!
https://t.co/hmP4RAIiLX
#ASHG24 Interested in comparing & transferring data & knowledge across species for translational biomedicine? This review is for you!
We take a deep dive into methods & highlight gaps/challenges.
Details on implementation, data, & benchmarks: https://t.co/iEWv1LvPmp
Preprint 🚨
A review state-of-the-art computational strategies for cross-species knowledge transfer in biomedicine
💻👩🦰🐭🐟🪰🪱🧬🫁⚕️
Led by an excellent team at @KrishnanLab: @yhbioinfo, @ChrisAMancuso, & @kaylainbio in collab w/ @FishEvoDevoGeno 🧵
https://t.co/nbVdKALnXm
#ASHG2024#ASHG24 If you’re interested in effectively reusing public omics data and/or passionate about data discovery, data reuse, metadata, etc., do ping me!
Annotating Publicly-Available Samples and Studies Using Interpretable Modeling of Unstructured Metadata
1. This study introduces txt2onto 2.0, an improved NLP and ML-based tool that automates the annotation of unstructured biomedical metadata, linking samples and studies to controlled disease and tissue vocabularies without manual intervention .
2. By using a TF-IDF-based feature extraction approach instead of averaging word embeddings, txt2onto 2.0 offers more interpretable results, allowing it to accurately identify key predictive terms within sample and study metadata .
3. The model outperforms its predecessor in both tissue and disease annotation tasks, excelling particularly in scenarios with limited training data, thus making it ideal for infrequent or rare biomedical terms .
4. A notable strength of txt2onto 2.0 is its ability to work across different biomedical text sources (e.g., GEO, PRIDE, ClinicalTrials), providing consistent annotations by capturing meaningful semantic relationships even with unseen terms .
5. The interpretability of txt2onto 2.0 is highlighted through word clouds of predictive terms, where it captures domain-specific keywords without requiring explicit mentions of target terms, showcasing its robustness and potential to adapt to new datasets .
6. This tool’s transparent prediction process and scalability support its application across various data repositories, advancing the FAIR data principles (Findable, Accessible, Interoperable, Reusable) in biomedical research .
@compbiologist
💻Code: https://t.co/EUNVrFR7i8
📜Paper: https://t.co/JypfYqF4QA
#BiomedicalNLP #DataAnnotation #MachineLearning #FAIRdata #ComputationalBiology
Our preprint 'Chemical Language Model Linker: blending text and molecules with modular adapters' is now out on arXiv, led by @Dengyifan1012. ChemLML is a method for text-based conditional molecule generation that uses pretrained text models like SciBERT, Galactica, or T5. 1/
Have you ever wondered what it takes to complete a postdoc? @compbiologist, PhD, from the @krishnanlab kicked off our Bytes to Bedside Seminar Series with a workshop exploring how to have an effective postdoc. Discover more about his insights ▶️ https://t.co/r1ZSGhzLXk
Today, @compbiologist, PhD, joined us for Bytes to Bedside. To celebrate #NPAW2024, he led a workshop offering valuable tips for planning a successful postdoc that emphasized the importance of not putting your life on hold, learning new skills, and following through on projects.
🙏Thank you, SfN (@SfNtweets). I am humbled and honored to receive this award, which has recognized many excellent scientists in recent years. Special thanks to my postdoc mentor, Erin (@erin_schuman), for the nomination.@MPFNeuro@maxplanckpress
🌟Celebrating #WomeninMedicineMonth with @JRegensteiner, a trailblazer in women's health research! As Director of the Ludeman Family Center, her groundbreaking work and BIRCWH award highlight her commitment to advancing women's health. Thank you for inspiring the next generation!
Pls share:
Our lab is hiring for multiple statistical genetics/genomics roles @CUMedicalSchool@CUBiomedInfo@CUAnschutz
Assistant Research Prof: https://t.co/N0fFdTaji8
Post-doc: https://t.co/rDAzpwBFiR
Program Manager: https://t.co/YEz51CjNtu
Reach out for more info!
🎉 Happy National Postdoc Appreciation Week 🎉 To celebrate, this week's "Bytes to Bedside" seminar features @compbiologist, PhD, who will explore planning and executing an effective postdoc. Thank you, #DBMI postdocs, for your contributions to research and discovery.