Facing adversity at work, team members often turn to one another to make sense of a problem that feels uncomfortable and uncontrollable. When negative thoughts and emotions dominate this sensemaking process, it can prevent a team from identifying constructive solutions
Now there is a new measure of collective rumination in teams to asses dysfunctional team processes. Teams who score high on this measure score lower on team performance and teamwork engagement.
Collective rumination involves recursive discussions of the problem, speculation about causes, speculation about consequences, sharing negative thoughts and feelings, and mutual reinforcement of problem talk.
https://t.co/g2Amnbswqj
Using AI to improve cancer immunotherapy outcomes, via training from transcriptomes of 10,000 tumor samples, 33 cancer types @NatureMedicine
https://t.co/Q6UfVQ6wMV
Researchers have now found that a protein in the blood of middle-aged people might help to identify those likely to develop dementia later in life
https://t.co/sqxcl7ipD9
GLP-1-induced weight loss increases single women's partnership rates by 29 percentage points and non-employed women's employment rates by 27 percentage points after 1.5+ years, from @rebeccardiamond https://t.co/0kPkSCbtXW
Forthcoming in AER: Insights: "Nature, Nurture, and Socioeconomic Outcomes: New Evidence from Sib Pairs and Molecular Genetic Data" by Markel, Ahlskog, Ebeltoft, Mõttus, Oskarsson, Vainik, Ystrom, and Beauchamp. https://t.co/E8uco57mNR
In older adults, how to keep your muscle young at multiple molecular levels (metabolomics, lipidomics, transcriptomics)
Exercise.
"We found that 50% of these age-related differences were absent in trained older adults, resulting in profiles resembling those of young adults."
https://t.co/AYIHUGyWCF
The All of Us program announced earlier this week a new data release from 747,000 participants, including:
👉 535,000 whole-genome sequences
👉 Electronic health record data from 482,000 participants
👉 Combined proteomics and transcriptomics from ~8,000 participants
👉 Fitbit wearable data from 68,000 participants
This is already the world's largest genomic resource integrated with longitudinal clinical data, surpassing resources such as FinnGen and UK Biobank.
It's remarkable to think that the program launched only in May 2018 and has already generated a resource of this scale, contributing to more than 1,000 publications.
Importantly, as with all longitudinal population resources, its value is likely to compound over time as additional follow-up datapoints from each participant accumulate.
Building, expanding, and enriching foundational resources like All of Us is one of the highest-return investments we can make in biomedical research.
Analyses of population cohorts found that young adults exhibited earlier systemic and organ specific aging, which was associated with increased risk of early onset cancer compared with older adults born decades earlier.
https://t.co/hF1vZ4Zad4
The biological age of individual cell types can be evaluated using plasma proteomics, revealing diverse aging profiles across more than 40 cell types and links between the accelerated aging of specific cell types and disease.
https://t.co/cYxEDin5kc
We’re excited to share our latest publication in @NatureComms: “Integrating common and rare variants improves polygenic risk prediction across diverse populations” 🧬🧪🫀
https://t.co/h6JsnL7OLY
Sincere thanks to Jacob Williams (lead), @AndrewHaoyu (senior), @Tony_Chen6, Xing Hua, @wendyWongSW, Kai Yu, @GENES_PK, and all @uk_biobank + @AllofUsResearch participants whose data made this work possible.
Most polygenic risk score (PRS) models focus on common variants. But rare variants can have larger effects for the people who carry them, and they may explain part of the genetic risk not captured by common-variant PRSs.
To address this, we developed RICE (polygenic Risk predictions Integrating Common and rarE variants), a framework for integrating rare variant signals with common-variant PRSs across ancestries.
RICE provides a unified framework to:
• Build a robust common-variant PRS (RICE-CV) by ensembling existing PRS methods
• Identify rare variant sets independent of RICE-CV using STAARpipeline + functional annotations
• Collapse significant rare variant sets into burden scores
• Train rare-variant PRSs (RICE-RV) with penalized regression
• Combine RICE-CV and RICE-RV in an independent validation set for integrated risk prediction
We evaluated RICE using extensive simulations and sequencing data from @uk_biobank and @AllofUsResearch, up to 740M genetic variants from 361,939 individuals across diverse ancestries and 11 complex traits.
A few key findings:
• RICE-CV consistently improved common-variant PRS performance, with average R² gains of 9.4% over the best alternative method for continuous traits across trait–ancestry combinations.
• Adding rare variants through RICE-RV produced further gains, especially for lipid traits and height.
• For lipid traits, incorporating rare variants increased R² by up to ~11.2% in Europeans and ~60.7% in African ancestry compared with common-variant PRS alone.
• Rare variants also helped identify individuals with extreme lipid profiles that common-variant PRS alone may miss. For HDL cholesterol, 6.3% of individuals in the top phenotype decile had high RICE-RV but low RICE-CV.
• The rare-variant signal was not limited to established high-penetrance lipid genes. RICE-RV captured predictive signal beyond LDLR, APOB, and PCSK9, supporting a broader polygenic rare-variant architecture.
Key takeaway: Integrating common and rare variants can significantly improve genetic risk prediction and risk stratification across populations, while rare variants do not improve every trait equally - their value depends on genetic architecture and available sample size.
The software and tutorial are open source:
RICE package: https://t.co/NtDLBa5jWj
Tutorial: https://t.co/m1OCFdmBRT
Manuscript code: https://t.co/WeynM1c180
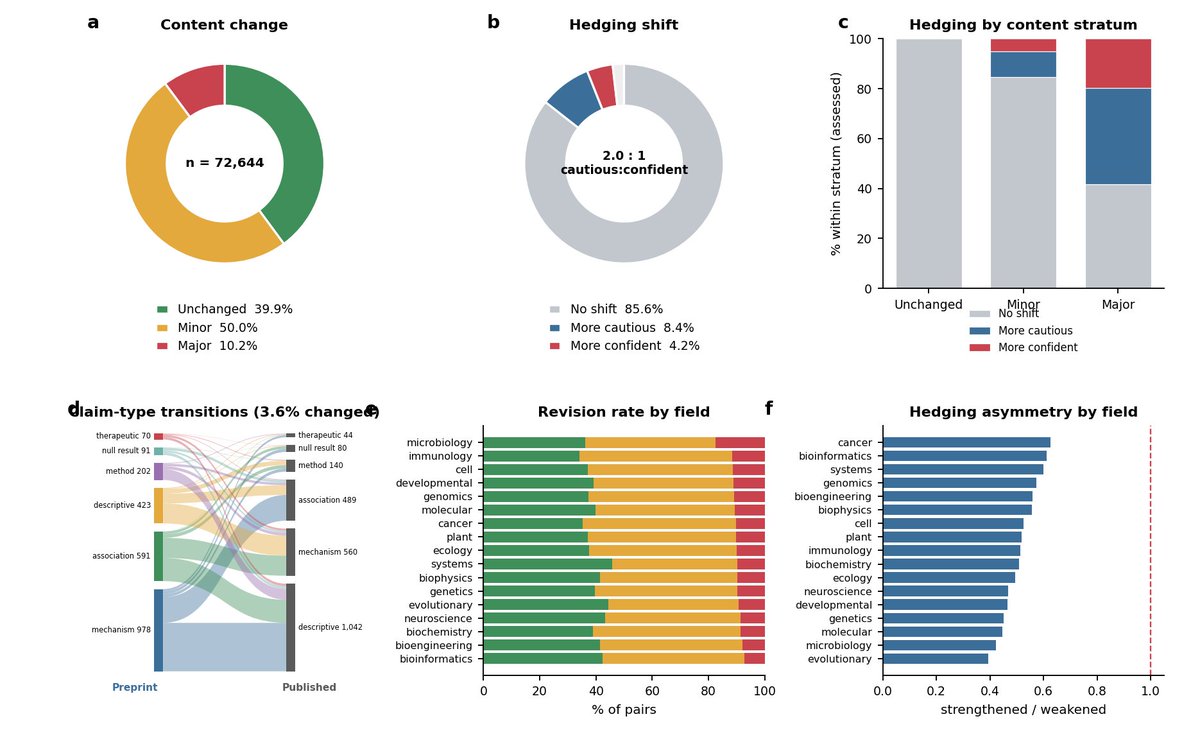
How much does a scientific claim actually change between the preprint and the final published paper?
We used a large language model to track it across all available 72,644 bioRxiv -> journal pairs from 2018 - 2025 in this new work with @HaoYin. 🧵
Residents of poor neighborhoods see earnings growth similar to richer areas, and those who gain tend to move out. This selective migration keeps poor neighborhoods poor, from @andy_garin, Ethan Jenkins, @evanmast2, and @BryanAStuart https://t.co/6ZQANDRVup
New in Nature Aging: an open, searchable atlas of how DNA methylation changes with age across 17 human tissues: over 15,000 methylomes.
Three things stood out to me:
1) Aging isn't uniform drift. The methylome shows conserved directional change, rising person-to-person variability, AND rising disorder (entropy), three analysis approaches most studies don't measure together.
2) A cell-adhesion hub, PCDHGA1, recurs across organs, while an NAD+ module stands out as one of the few modifiable nodes among otherwise fragile aging networks. Co-methylation modules were built with WGCNA (per tissue).
3) Best of all, the atlas and summary data are open: explore it yourself: https://t.co/5OnhwxSuBn
Jacques M & Eynon N (2026), Meta-analysis of DNA methylation aging signatures in 17 human tissues. https://t.co/HsEyPtnoDo
Cosmos Grants are back!
If you're building AI that strengthens human autonomy or truth-seeking, we want to fund your prototype.
Inspired by @tylercowen's Emergent Ventures, we'll get a decision to you in ~4 weeks. $1k–10k+ per project. 🧵
https://t.co/3bVoeJFAiP
Young people are more sensitive to social media likes than adults. This feedback can greatly affect their mood, according to a @ScienceAdvances study that highlights how social media platforms foster a culture of comparison and validation-seeking behavior. #SocialMediaDay https://t.co/0MrXZ4ijh8
For decades, biology textbooks have enshrined a simple rule: DNA is made by copying a template. After one enzyme unzips a DNA double helix into separate strands, another called a polymerase builds a complementary sequence, base by base, for each strand. Presto: two copies of the original DNA.
But recent research into how bacteria defend themselves from viruses now shows this synthesis rule isn’t absolute. The team describes a bacterial enzyme that synthesizes DNA without a nucleic acid template, using its own structure as a guide.
Learn more: https://t.co/TeUWvyO0OD @NewsfromScience
Why do workers dislike inflation? Because wages catching up to prices means costly conflict: tough pay talks, job search, bargaining. Survey + model show conflict more than doubles inflation costs. @jptguerreiro@JADHazell@ChenLian92 & Christina Patterson https://t.co/AObZHTOANN