1/ Thrilled to share our new paper, out today in @Nature: "Non-invasive profiling of the tumour microenvironment with spatial ecotypes".
Paper (open access): https://t.co/EujZFqU7wi
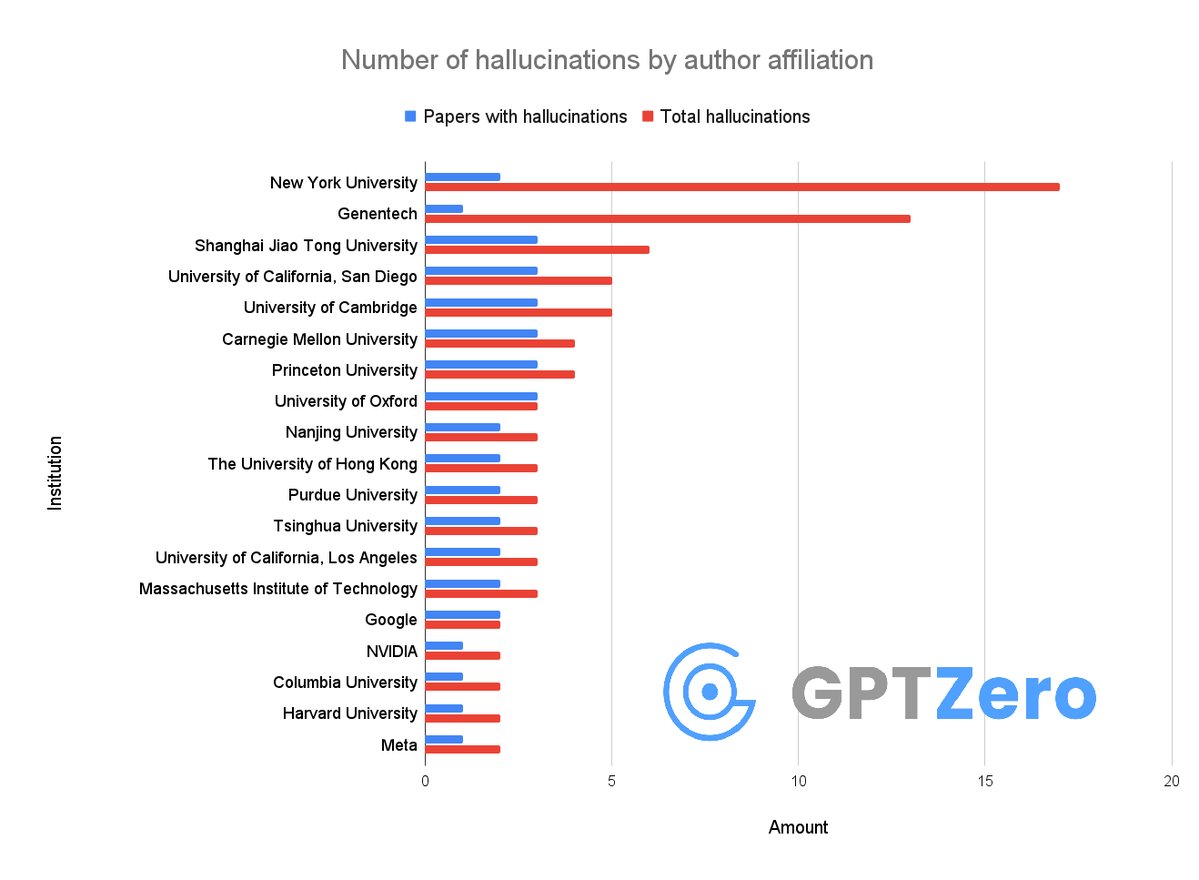
Okay so, we just found that over 50 papers published at @Neurips 2025 have AI hallucinations
I don't think people realize how bad the slop is right now
It's not just that researchers from @GoogleDeepMind, @Meta, @MIT, @Cambridge_Uni are using AI - they allowed LLMs to generate hallucinations in their papers and didn't notice at all.
It's insane that these made it through peer review👇
Mapping 3.4 billion gene circuit designs with AI
Designing synthetic gene circuits is like tuning a complex instrument in the dark. You have dozens of genetic parts—promoters, transcription factors, binding motifs—that must work together precisely, yet each combination behaves unpredictably due to context-dependent molecular interactions. Traditional approaches test circuits one at a time, making optimization painfully slow.
Kshitij Rai and coauthors just changed the rules of the game. Their platform, CLASSIC (Combining Long- And Short-range Sequencing to Investigate genetic Complexity), combines Nanopore and Illumina sequencing to profile over 100,000 multi-kilobase gene circuit designs in a single experiment—then uses machine learning to predict the behavior of billions more.
The workflow is elegant: pooled DNA assembly with barcodes, long-read sequencing to index composition-to-barcode mappings, phenotypic sorting in human cells, and short-read sequencing to link barcodes to function. The result? Quantitative expression data for 121,000 single-input circuits and 128,000 dual-input circuits, used to train neural networks that predict circuit behavior with r² values of 0.86–0.90.
The insights are remarkable. High-fold-change circuits don't emerge from a single "optimal" design but from multiple balanced combinations of medium-activity components. AND-gate logic requires clustered transcription factor binding sites; OR-gates need interspersed patterns. These rules were invisible before—now they're learnable from data.
The message: by scaling the design-build-test-learn cycle by orders of magnitude and combining it with ML, we can finally navigate genetic design spaces too vast for human intuition, accelerating everything from metabolic engineering to cell therapies.
Paper: https://t.co/d622fMqVDI
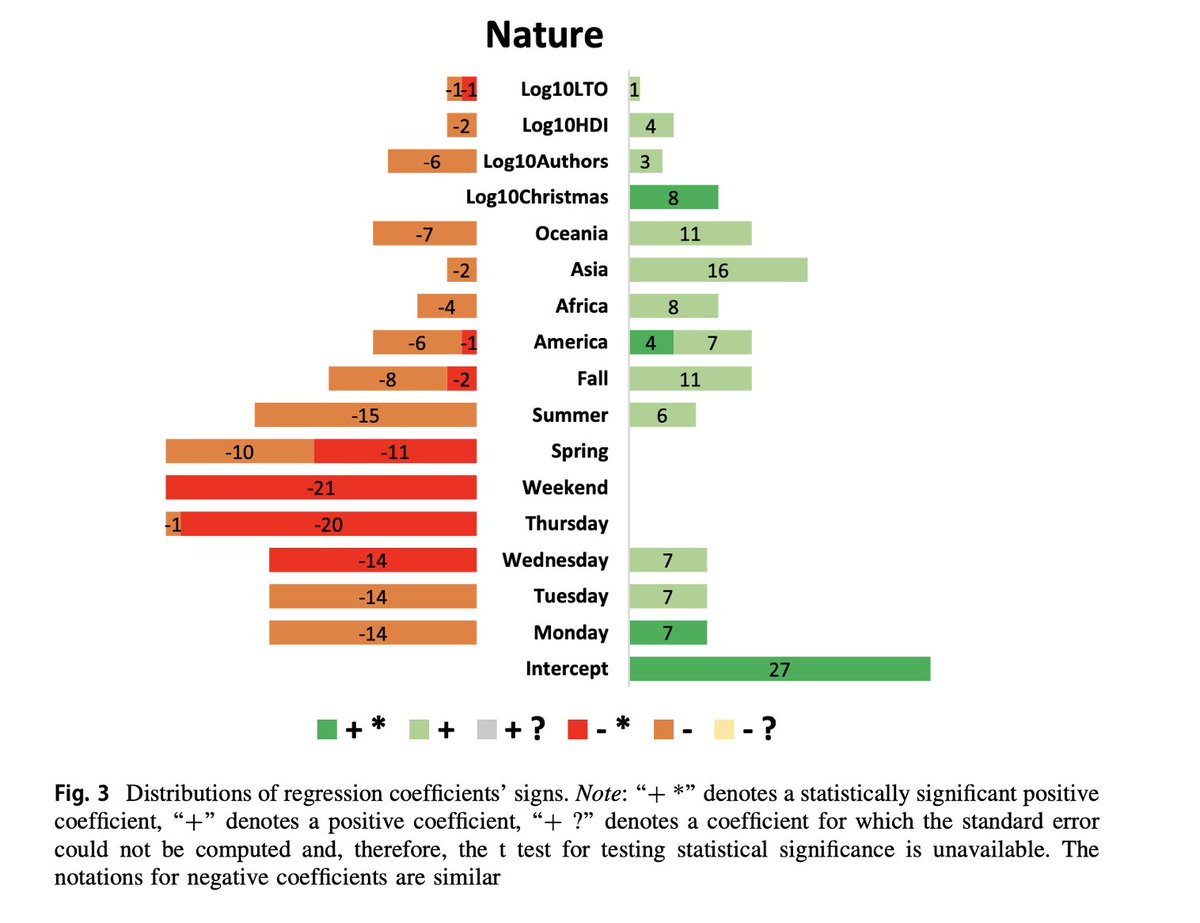
Papers submitted on Tuesdays are more likely to be accepted by Nature whereas Wednesdays seem the most likely day to submit and secure acceptance to PLOS ONE. For Cell, Mondays and Tuesdays seem the best submission days in case of accepted papers.
https://t.co/6w5AraWMzG
@tangming2005 agree with usefulness of unix/shell commands - but AI is changing this fast: can create really 'novel' (at least to me) and useful, direction commands save lots of my time tweaking the tools. I can not argue otherwise, but this scene is changing fast - using shell commands
1/ 🧬Our paper is out @JCOPO_ASCO!
We tested AlphaMissense(an AI tool for predicting the pathogenicity of missense mutations), across DNA damage repair genes in cancer.
Key finding: accuracy varies dramatically by gene
- crucial for clinical use!
➡️ https://t.co/AH6ilncTEt
🧵 Paradigm-buster just out: ATM-deficient tumors stay cold ❄️—unlike other DNA-repair defects—so PD-1 blockade alone (or with ATRi) falls flat. We mapped the biology in mice + patients. Paper in @JITCancer now (link below) -- #ImmunoOncology#DNArepair@OncoAlert (1/9)
a great insight from: https://t.co/byRzhXVsgZ "User expectations are also going to rise. Businesses that simply use the greater productivity to cut costs will lose out to companies that invest in harnessing the new capabilities to build better services."
1/ Introducing SCimilarity, a new foundation model to explore scRNAseq data across tissues and diseases! It learns a common measure of cell similarity by training a deep metric learning model on millions of cells from various human tissues and conditions. https://t.co/a6B5Ie4PeS