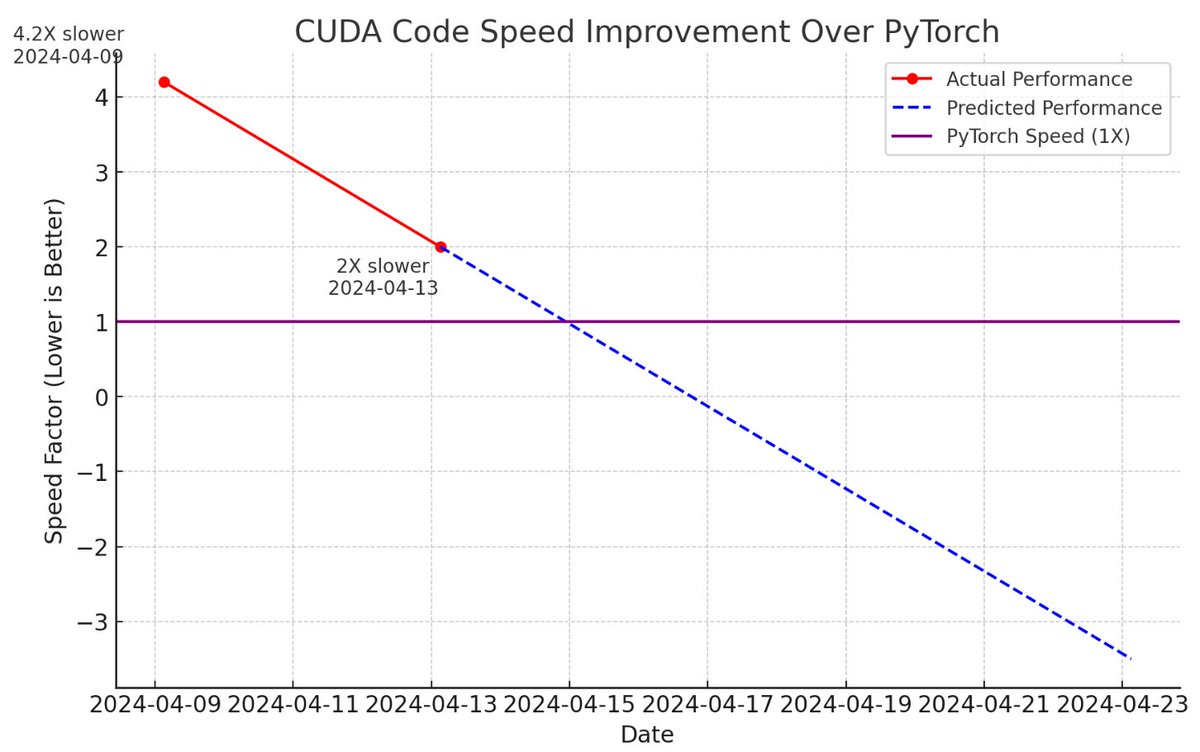
A few new CUDA hacker friends joined the effort and now llm.c is only 2X slower than PyTorch (fp32, forward pass) compared to 4 days ago, when it was at 4.2X slower 📈
The biggest improvements were:
- turn on TF32 (NVIDIA TensorFLoat-32) instead of FP32 for matmuls. This is a new mathmode in GPUs starting with Ampere+. This is a very nice, ~free optimization that sacrifices a little bit of precision for a large increase in performance, by running the matmuls on tensor cores, while chopping off the mantissa to only 10 bits (the least significant 19 bits of the float get lost). So the inputs, outputs and internal accumulates remain in fp32, but the multiplies are lower precision. Equivalent to PyTorch `torch.set_float32_matmul_precision('high')`
- call cuBLASLt API instead of cuBLAS for the sGEMM (fp32 matrix multiply), as this allows you to also fuse the bias into the matmul and deletes the need for a separate add_bias kernel, which caused a silly round trip to global memory for one addition.
- a more efficient attention kernel that uses 1) cooperative_groups reductions that look much cleaner and I only just learned about (they are not covered by the CUDA PMP book...), 2) the online softmax algorithm used in flash attention, 3) fused attention scaling factor multiply, 4) "built in" autoregressive mask bounds.
(big thanks to ademeure, ngc92, lancerts on GitHub for writing / helping with these kernels!)
Finally, ChatGPT created this amazing chart to illustrate our progress. 4 days ago we were 4.6X slower, today we are 2X slower. So we are going to beat PyTorch imminently 😂
Now (personally) going to focus on the backward pass, so we have the full training loop in CUDA.
This is me as a little pup, aged 5. My little sister is almost 3.
It’s January 1991, and we are in Vilnius, Lithuania 🇱🇹
Something scary is about to happen on this day.
Walk with me on this journey through old memories… 🧵
Introducing 𝐌𝐨𝐛𝐢𝐥𝐞 𝐀𝐋𝐎𝐇𝐀🏄 -- Hardware!
A low-cost, open-source, mobile manipulator.
One of the most high-effort projects in my past 5yrs! Not possible without co-lead @zipengfu and @chelseabfinn.
At the end, what's better than cooking yourself a meal with the 🤖🧑🍳
The Rabin-Scott theorem is one of the (philosophically) deepest mathematical results I know. When properly understood, I claim that it can't help but alter your view of reality in a fairly foundational way. Yet its typical textbook presentation obscures much of this depth. (1/8)
On @elonmusk’s claim that everybody does it, actually in 2014 Erdoğan made the same demands of Twitter. Twitter refused and he did briefly ban the site. But the whole thing backfired on Erdoğan. Twitter also told Turkish users ways to evade the ban. https://t.co/h7tbENNDK0
According to the 1926 all-Soviet census 55%-67,5% (depending on definition) of the Kuban Region's (today part of russia) population identified as Ukrainians. In 2021 only 0,5% identified as such.
So what happened?
Instead of finding the perfect prompt for an LLM (let's think step by step), you can ask LLMs to critique their outputs and immediately fix their own mistakes. Here's a fun example:
My favourite thing on Twitter (genuinely) is people discovering the Baltic Way.
No mobiles, no social media, limited freedoms. Yet, on 23 August 1989, 2 million formed a nearly 700km chain across 3 countries demanding freedom.
However, the key context is often missed… 🧵
What is your brain doing when you are doing absolutely nothing?
A neuroscientist wanted an answer to that question.
So she conducted the first brain-imaging study of brain activity when the brain is in a "resting state"—free of inputs/free to wander.
The results are interesting...
The neuroscientist Dr. Nancy Andreasen used a positron emission tomography (PET) scan to study brain activity when the brain is at "wakeful rest"
When you are doing absolutely nothing:
"We found activations in multiple regions of the association cortex," Dr. Andreasen wrote. "We were not [seeing] a passive silent brain during the ‘resting state,’ but rather a brain that was actively connecting thoughts and experiences.”
Essentially, Dr. Andreasen demonstrated that the brain defaults to creativity.
When you are doing absolutely nothing, the brain engages in what the researchers termed "random episodic silent thought" or REST.
And during REST, the brain "uses its most human & complex parts."
Takeaway 1: Doing nothing promotes creativity.
Raymond Chandler, Neil Gaiman, Dr. Suess, George Lucas, and many other writers all have/had a similar habit.
They gave themselves two options:
a) You don’t have to write.
b) You can’t do anything else.
@neilhimself explains:
"I go down to my lovely little gazebo at the bottom of the garden, sit down, and I’m absolutely allowed not to do anything...I'm not allowed to do a crossword, read a book, phone a friend...all I’m allowed to do is absolutely nothing, or write. But writing is actually more interesting than doing nothing after a while."
Takeaway 2: REST
Resting, Dr. Andreasen wrote, “allows the association cortices of the brain to converse in a free & uncensored manner.”
This is why ideas come to us in the shower, on walks, and when daydreaming.
A favorite example of this: @Lin_Manuel had the idea for “Hamilton” on vacation:
"I was on a pool float with a margarita in my hand and had a moment when my brain could unplug. [It was his first vacation in 7 years]. The moment my brain got a moment's rest, the best idea I've ever had in my life walked into it."
---
“If a plant only gets sunlight, it’s very harmful. It needs darkness too…In the darkness, it converts oxygen into carbon dioxide. We are like that too. We need periods of doing & periods of non-doing.” — Robert Pirsig
Follow me @bpoppenheimer for more content like this!
After 2 years, Practical Deep Learning for Coders v5 is finally ready! 🎊
This is a from-scratch rewrite of our most popular course. It has a focus on interactive explorations, & covers @PyTorch, @huggingface, DeBERTa, ConvNeXt, @Gradio & other goodies 🧵
https://t.co/nzv7pek0iq
GPT-4 and its ilk are awesome for rapid prototyping and one-offs, but at the end of the day, enterprises will deploy far smaller distilled models in production. Here's my contrarian take -































![bpoppenheimer's tweet photo. What is your brain doing when you are doing absolutely nothing?
A neuroscientist wanted an answer to that question.
So she conducted the first brain-imaging study of brain activity when the brain is in a "resting state"—free of inputs/free to wander.
The results are interesting...
The neuroscientist Dr. Nancy Andreasen used a positron emission tomography (PET) scan to study brain activity when the brain is at "wakeful rest"
When you are doing absolutely nothing:
"We found activations in multiple regions of the association cortex," Dr. Andreasen wrote. "We were not [seeing] a passive silent brain during the ‘resting state,’ but rather a brain that was actively connecting thoughts and experiences.”
Essentially, Dr. Andreasen demonstrated that the brain defaults to creativity.
When you are doing absolutely nothing, the brain engages in what the researchers termed "random episodic silent thought" or REST.
And during REST, the brain "uses its most human & complex parts."
Takeaway 1: Doing nothing promotes creativity.
Raymond Chandler, Neil Gaiman, Dr. Suess, George Lucas, and many other writers all have/had a similar habit.
They gave themselves two options:
a) You don’t have to write.
b) You can’t do anything else.
@neilhimself explains:
"I go down to my lovely little gazebo at the bottom of the garden, sit down, and I’m absolutely allowed not to do anything...I'm not allowed to do a crossword, read a book, phone a friend...all I’m allowed to do is absolutely nothing, or write. But writing is actually more interesting than doing nothing after a while."
Takeaway 2: REST
Resting, Dr. Andreasen wrote, “allows the association cortices of the brain to converse in a free & uncensored manner.”
This is why ideas come to us in the shower, on walks, and when daydreaming.
A favorite example of this: @Lin_Manuel had the idea for “Hamilton” on vacation:
"I was on a pool float with a margarita in my hand and had a moment when my brain could unplug. [It was his first vacation in 7 years]. The moment my brain got a moment's rest, the best idea I've ever had in my life walked into it."
---
“If a plant only gets sunlight, it’s very harmful. It needs darkness too…In the darkness, it converts oxygen into carbon dioxide. We are like that too. We need periods of doing & periods of non-doing.” — Robert Pirsig
Follow me @bpoppenheimer for more content like this!](https://pbs.twimg.com/media/Fr_l8F9WwAAyaFB.jpg)






























