I'm joining OpenAI next week!🥹 The job search turned out to be really challenging but also super rewarding, so I wrote a small blog to share what I learned along the way and hopefully make the process a little less mysterious for the next person. https://t.co/6FigSBdenD
The latent-vs-pixel debate misses the point.
GPT Image 2 shows what users notice: pixel-level fidelity.
Latent models show what scales: compact semantic structure.
We connect them by replacing VAE/RAE decoders with a Pixel Diffusion Decoder.
Code and Model available: https://t.co/JjtecJzF0W
🧵(1/N)
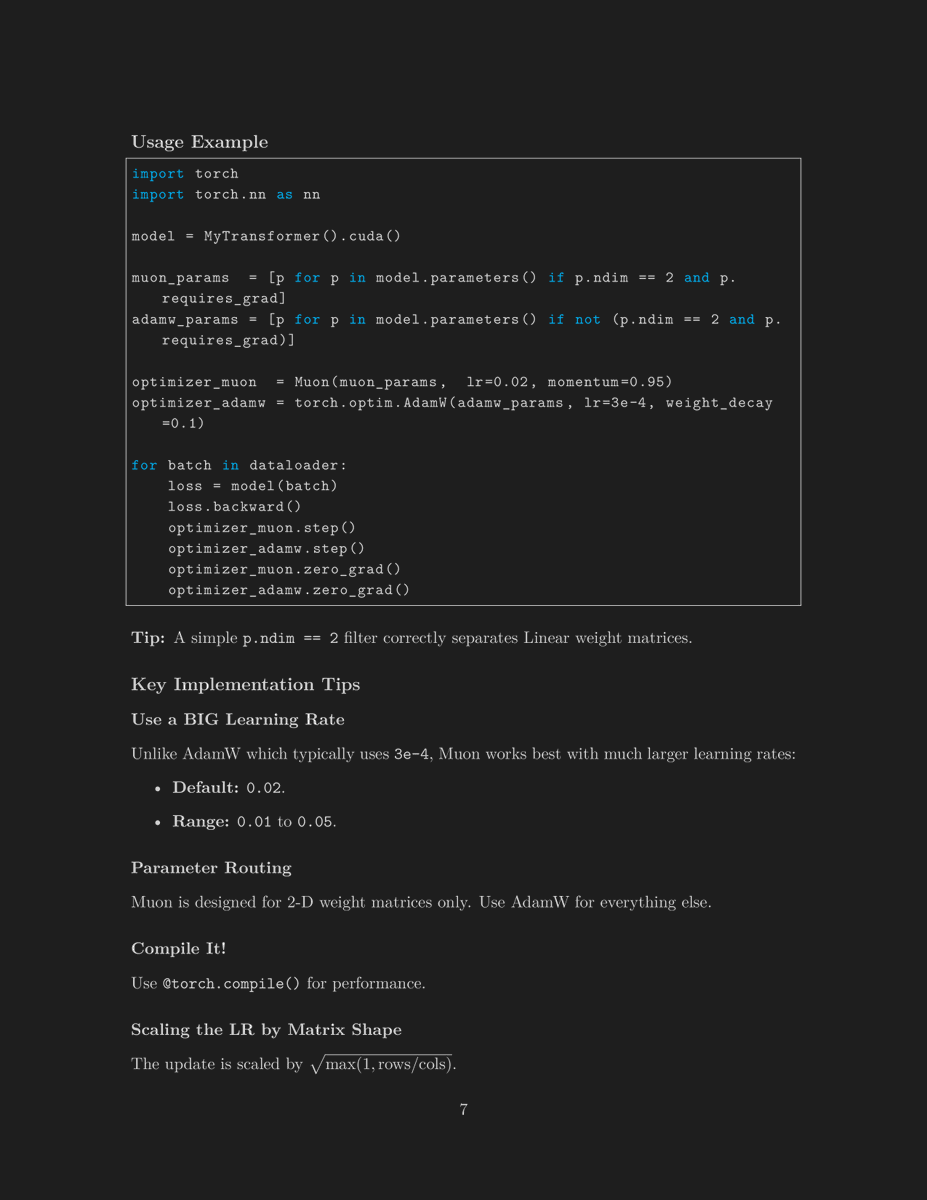
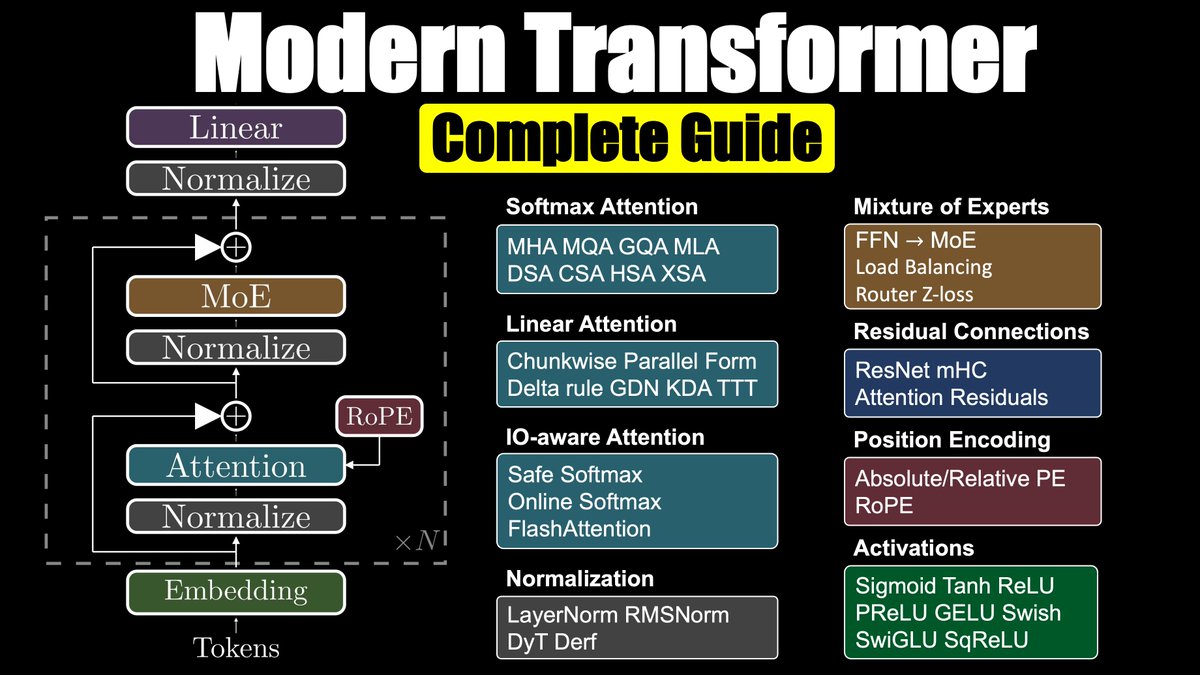
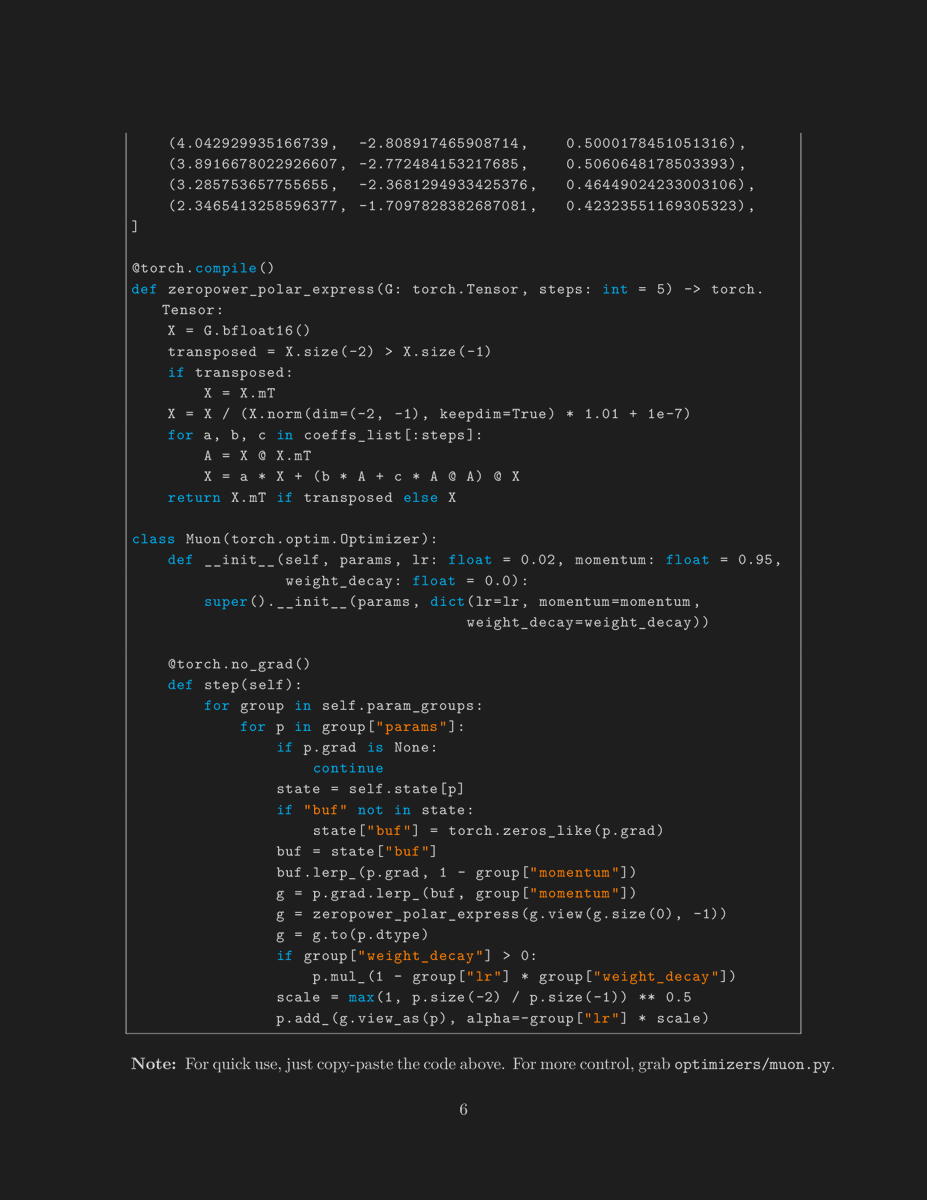
Modern Transformer - Complete Guide
Interested in learning the recent advances in transformers?
After 13 videos, I've finally completed this series!
🥳🥳🥳
Check out the course here:
https://t.co/CsujxlWigC
Flow-LLM Blogpost :D https://t.co/0HiyNPJHsk
In the last few weeks, a bunch of work on flows for language came out 🌊
That is exciting, because it makes truly parallel text generation feel real: generation where models can keep refining the whole response during inference, instead of committing token by token.
I wrote an intuitive and animated introduction to the area — why autoregression has a structural ceiling, why discrete diffusion only partly escapes it, and why flows may be the first genuinely parallel alternative.
Here's an overview of the key parts of the blog - and let's chat at #ICLR2026 :)
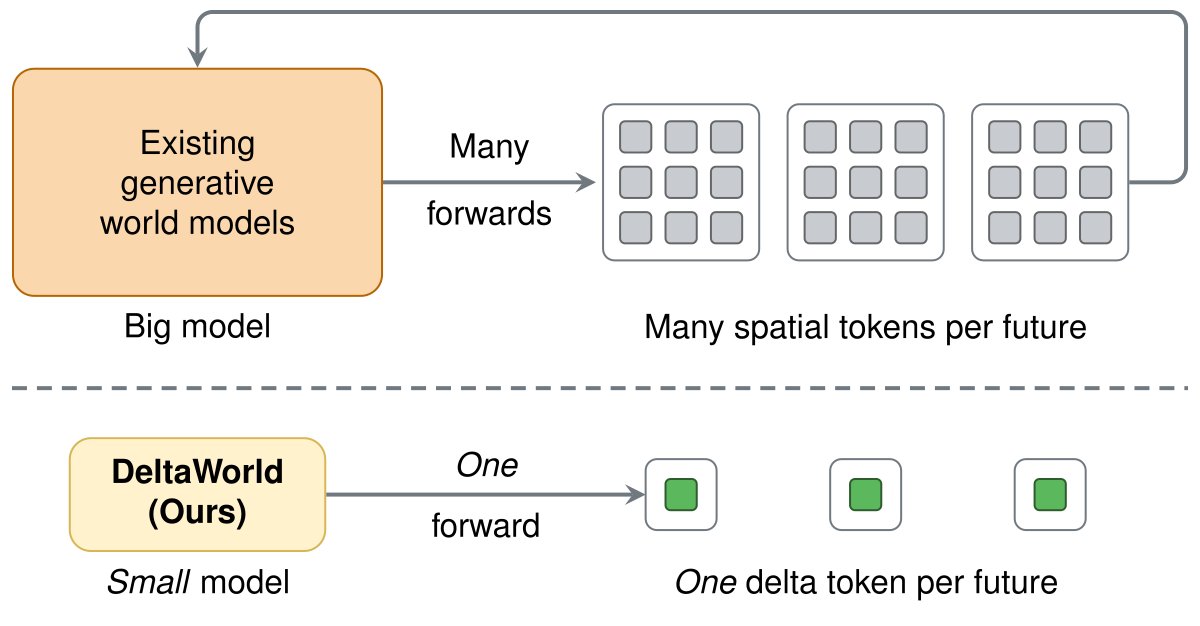
World models are heavy. They don't need to be.
Each frame is encoded as 1024 spatial tokens. What if it were just 1?
In our #CVPR2026 Highlight from Amazon FAR, we compress frames into "delta" tokens for efficient generative world modeling.
Paper, code & models below ↓
(1/7)
Pretrained ViTs like DINOv2 or CLIP are great, but they produce fixed, generic representations that encode the most salient visual concepts (e.g., "cat").
In human vision, prior priming with language changes how people parse an image. We believe visual encoders should do the same
🚨 Introducing Steerable Visual Representations, a new family of visual features you can steer with text towards specific visual concepts.
"Diffusability" is all about the spectrum.
https://t.co/nb4i8tDJl3
If you enjoyed my blog post about diffusion as spectral autoregression, and are wondering how this relates to latent diffusion, give this paper a read!
Humans can see in high-res, high-FPS in real-time. Why can't VLMs?
Introducing AutoGaze: ViTs/VLMs "gaze" only at key video regions! Up to 4-100x token savings, 19x speedup, and enables scaling to 4K-res 1K-frame videos.
📄 https://t.co/GhbWZwMAg7
🌐 https://t.co/mEJ991MAIR
🤗 https://t.co/FOfc2QRThi
(1/n)🧵
Yann LeCun and his team can't stop cooking
"LeWorldModel: Stable End-to-End Joint-Embedding Predictive Architecture from Pixels"
One of the biggest bottlenecks of JEPA is they are hard to train, and this new research changes that.
They propose LeWorldModel, which shows that a small model can learn a usable world model directly from raw pixels end-to-end.
Sitting at 15M parameters, they made it without needing heuristics and avoiding anti-collapse hacks while staying competitive and planning up to 48x faster.
Making JEPA based modeling much more accessible, cheaper, and stabler.
"Exclusive Self Attention"
This paper proposed Exclusive Self-Attention (XSA), which is a tiny two-line change that stops attention from looking at itself.
This forces it to focus on the rest of the sequence, and can make transformers more effective!
This improves the performance at long context at almost no extra cost.
We are also releasing self-contained lecture notes that explain flow matching and diffusion models from scratch. This goes from "zero" to the state-of-the-art in modern Generative AI.
📖 Read the notes here: https://t.co/RULWDgn9pm
Joint work with @EErives40101.
I made a Claude Code skill that generates conference posters 🛠️
Instead of a static PDF, it outputs a single HTML file — drag to resize columns, swap sections, adjust fonts, then give your layout back to Claude. 🔁
🔗 Skill 👉 https://t.co/KhYV8anbxL
Introducing 𝑨𝒕𝒕𝒆𝒏𝒕𝒊𝒐𝒏 𝑹𝒆𝒔𝒊𝒅𝒖𝒂𝒍𝒔: Rethinking depth-wise aggregation.
Residual connections have long relied on fixed, uniform accumulation. Inspired by the duality of time and depth, we introduce Attention Residuals, replacing standard depth-wise recurrence with learned, input-dependent attention over preceding layers.
🔹 Enables networks to selectively retrieve past representations, naturally mitigating dilution and hidden-state growth.
🔹 Introduces Block AttnRes, partitioning layers into compressed blocks to make cross-layer attention practical at scale.
🔹 Serves as an efficient drop-in replacement, demonstrating a 1.25x compute advantage with negligible (<2%) inference latency overhead.
🔹 Validated on the Kimi Linear architecture (48B total, 3B activated parameters), delivering consistent downstream performance gains.
🔗Full report:
https://t.co/u3EHICG05h
Since @karpathy kicked off recursive self-improvement a few days ago, I've been thinking about how we can automate interpretability research.
I asked Claude to train a sparse autoencoder on Gemma3-1B. It recovered 96% of Gemma's behaviors from interpretable features overnight.
We present a research preview of Self-Flow: a scalable approach for training multi-modal generative models.
Multi-modal generation requires end-to-end learning across modalities: image, video, audio, text - without being limited by external models for representation learning. Self-Flow addresses this with self-supervised flow matching that scales efficiently across modalities.
Results:
• Up to 2.8x faster convergence across modalities.
• Improved temporal consistency in video
• Sharper text rendering and typography
This is foundational research for our path towards multimodal visual intelligence.
New paper out! We present a training method for multimodal generative models, called Self-Flow, which combines classic flow matching and representation learning.
Why? Unlike most representation alignment methods, our new approach does not require external, pretrained models and thus scales gracefully to joint multimodal training on images, videos and audio.
How? It combines per-timestep flow matching with dual-timestep representation learning, improving the models' internal representations.
This approach outperforms prior methods and shows promising scaling behavior in multimodal pretraining. It also enables downstream applications such as action prediction for embodied AI.
webpage+paper: https://t.co/qzGQGj8JYk
code: https://t.co/edhfdVEqSf
Credit to @hila_chefer, @pess_r, Dominik, @dustin_podell, Vikash, @Vinh_Suhi and Antonio.
If you enjoy doing open research like this, come and join BFL! We are actively hiring🌲
I've been debugging RoPE recently and kept getting tripped up by details that most explanations gloss over. So I wrote a deep dive.
"Understanding RoPE: From Rotary Embeddings to Context Extension"
https://t.co/yDZqzcqSk5
The blog covers:
• Full RoPE derivation from rotation matrices
• A clean proof of why RoPE's attention decays with distance (and when it breaks)
• The π boundary (RoPE's Nyquist limit)
• NTK-aware scaling derivation
• Dynamic NTK
• YaRN's frequency ramp + attention scaling
• Reference PyTorch code
Hope it helps! Feedback welcome!