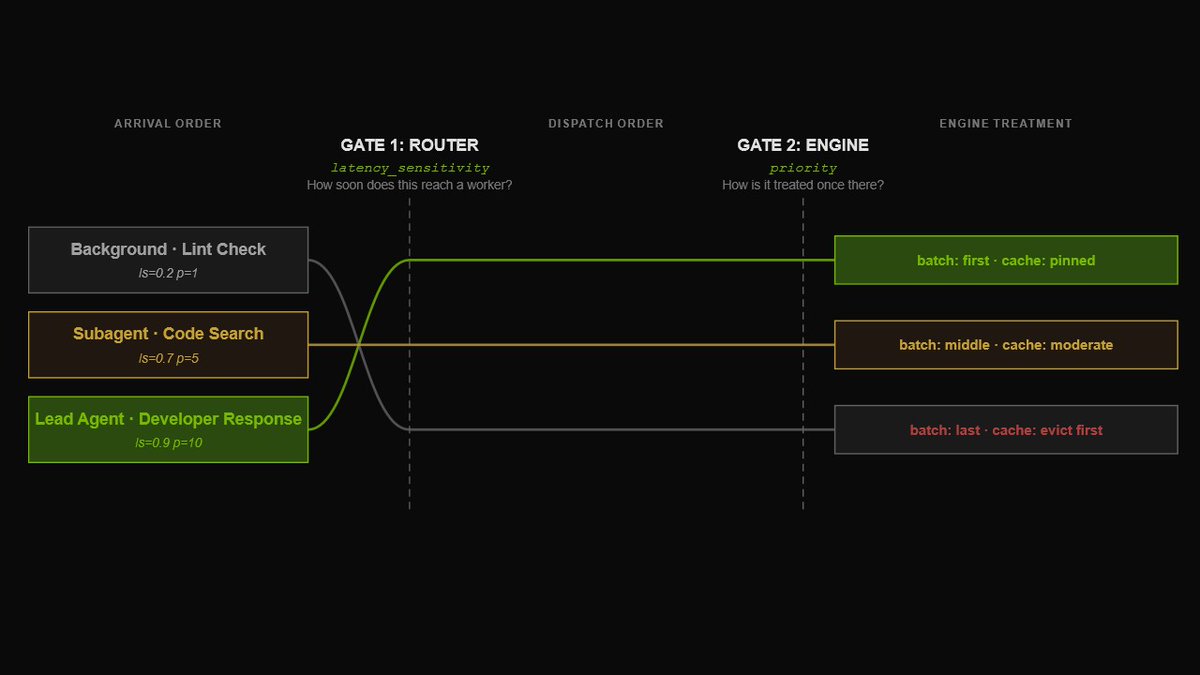
Traditional inference wasn’t built for agentic coding.
Agentic tools make hundreds of API calls per coding session, often with recomputed context, creating bottlenecks that drive up cost per token.
NVIDIA Dynamo rebuilds the stack for agents with:
→ KV-aware routing
→ Agent-aware scheduling
→ Multi-tier caching
→ Unified orchestration
The result: higher cache hit rates, lower latency, and up to 7× more throughput: https://t.co/E9tRgiLmar
In @kxsystems recent blog, they detail how native GPU acceleration speeds up analytic and AI workloads for multimodal data by up to 25x.
Acceleration is now built into KDB-X through NVIDIA cuVS and cuDF, enabling faster time series analytics, vector, and AI workloads in a single platform.
https://t.co/Dq5MtQvYtI
NVIDIA cuDF and cuVS libraries are being adopted by leading data platforms to fuel modern enterprise data processing.
Across industries, cuDF and cuVS use is surging:
✅ @Nestle: Achieved 5x faster processing on @IBM https://t.co/PSFMiyZDzF.
✅ @Snap: Cut data processing costs by 76% on @GoogleCloud.
✅ @Dell AI Data Platform: 12x higher throughput for vector indexing.
✅ @Oracle: AI-ready data in minutes, not hours.
Read the #NVIDIAGTC announcement: https://t.co/UnoQ9V1B9t
Thank you to our partners: @ApacheSpark@PrestoDB, @duckdb, @DataPolars, FAISS, @OpenSearchProj, @milvusio, @EDBPostgres, @NetApp, @Snowflake, @starburstdata, @VAST_Data
Scale up and supercharge financial portfolio optimization workflows using our NVIDIA CUDA-X libraries to reduce re-optimization from hours to seconds.⏱️
✅ Accelerate scenario generation up to 100x using cuML for KDE on 100k scenarios.
✅ Boost Mean-CVaR optimization cycles with cuOpt open-source solvers for up to 160x faster than state-of-the-art open-source CPU solvers at scale.
Get started -- enroll in NVIDIA’s new DLI Accelerating Portfolio Optimization hands-on course: https://t.co/EcvtkJyDS2
📝 Master the full optimization workflow: data curation to backtesting.
📝 Delve into accelerated optimization on NVIDIA GPUs in our learning environment.
📝 Explore downstream applications that benefit from significant computational speedups.
Data Scientists: Snowflake now natively integrates NVIDIA #CUDA-X data science libraries for game changing acceleration.
⚡ Up to 200x faster: see massive performance gains for ML algorithms like TSNE, HDBSCAN and UMAP using NVIDIA cuML
🔢 No code changes: access GPU-power using your existing pandas and scikit-learn code in Snowflake Notebooks
🏗️ Efficiency + scale: use NVIDIA cuDF and cuML to speed up model development cycles with large data
Read the blog by @Snowflake and NVIDIA PM’s and learn how easy it is to supercharge your ML workflows: https://t.co/I9UjBGHkxf
See Snowflake’s developer guide to get started: https://t.co/UKZrT39Cgy
Building GPU-Accelerated Data Science Agents -- Special tutorial with @kaggle and @googledevs
⏰Today from 11-12:00 PDT.
Live tutorial by Jiwei Liu NVIDIA demonstrates how to build LLM-powered data science agents that convert natural language questions into automated, GPU-accelerated data analysis.
The agent can generate, execute, and interpret code to deliver real-time insights from massive datasets.Key innovations include integrating NVIDIA cuDF pandas Accelerator as a tool for Agents, a multi-agent architecture (Planner, Coder, Vision, Writer) for collaborative workflows, dynamic context management, and flexible deployment on free Kaggle GPUs or scalable cloud APIs.
Two demos will be presented: an interactive agent that analyzes 30M-row datasets in about 3 seconds per query and an automated report generator that explores a dataset and produces professional multi-page PDF reports with visualizations in under five minutes.
https://t.co/PWP9aAyccu
Just released a video about Hyperparameter Tuning XGBoost models with Optuna. I show how you can get 5-15x speedups training models using XGBoost 3.0's GPU support....
If that sounds like your cup of tea you can check it out here: https://t.co/MnQee96UFv
@NVIDIAAIDev
Unleash the power of GPUs for omics! 🚀 Join our Hackathon. Learn from NVIDIA & scverse experts and contribute to open-source tools. Applications close Aug 27, 2025. Don't miss out! #Omics#Hackathon#GPUaccelerated#DataScience
LINK: https://t.co/mO7djGwTjz
Single-cell research generates enormous and complex datasets, requiring advanced data tools that can scale up for modern #genomics workflows. RAPIDS-singlecell, developed by @scverse_team makes it easy to access unprecedented speed and scale for massive workloads with NVIDIA GPUs - up to 1034x faster.
Getting started notebooks for RAPIDS-singlecell:
📗 notebook01: build an end-to-end RAPIDS-singlecell workflow - more than 30x faster end-to-end on GPUs
📗 notebook02: build on notebook01 to gain deeper insights from your single-cell data
📗 notebook03: explore results using Pearson residuals and assess your model
🧵 Tour the Blueprint notebooks 👇
🌟 XGBoost 3.0 now has new capabilities for GPUs:
✅ Train up to 1 TB of data on a single Grace Hopper GPU: Up to 8x faster than CPU with External-Memory Quantile DMatrix.
✅ Faster and lighter: GPU hist/approx methods an additional ~2x speed up and reduced memory use.
✅ Full feature support: External memory now supports categorical features, all objectives, and SHAP.
✅ Distributed mode: Experimental support for out-of-core training across a cluster.
Technical deep dive ➡️ https://t.co/Fx68iLlTU5
Transform topic modeling workflows from hours to minutes.
⚡With cuML and cuDF, achieve next-level speed, accuracy, and insights, handling larger datasets and more complex workloads.
🔎 Explore how you can use NVIDIA GPUs to achieve 4x faster workflows end-to-end, with no code changes.
📗 See our demo notebook and dive into topic modeling with BERTopic, pandas, UMAP and more ➡️ https://t.co/KSS6uhXQhQ
Learn more:
cuML 🔗https://t.co/gTtjXY2wIC
cuDF 🔗 https://t.co/DPuGSX9P8d
🎉 News from @Kaggle Playground S5E5 — Congrats to our researcher @ChrisDeotte for again achieving 🏆 1st place.
His winning solution tackled how to predict calorie expenditure for exercise duration. 💡 Solution highlights:
📊 Multiple modeling approaches based on EDA insights
🔁 Fast feature engineering and experimentation using NVIDIA cuDF
🧠 GPU hill climbing using NVIDIA cuML models, GBDT, and NN
⚡ Powered by NVIDIA’s cuDF + cuML for acceleration
Thanks to the Kaggle community for the insights and support. 🙌
➡️ Solution write up: https://t.co/wGjRm7kdb4
➡️ Leaderboard: https://t.co/hYOeVkQJL0
👀 NEW feature: @RAPIDSai cuDF supports up to 2.1B rows of text data.
⚡ Watch #pandas code with large strings get GPU-accelerated up to 30x with zero code changes.
Try the notebook ➡️ https://t.co/8ysziZ1bns
#DataScience, #Python, #RAPIDS
When we launched Gretel 3 years ago, it was to solve a simple problem: people need data and they have a hard time getting it.
Here's a brief thread on what we've learned since then and why we're now building a #developer stack for synthetic data.
Want to learn how to use #synthetic data to help you build models and run tests?
Tune in on July, 29 at 5 pm CEST for an introduction into synthetic data by @masonegger!
https://t.co/oYqJZ4bNp3