Congrats to the recipients of the @Wikimedia Research Award of The Year!!
🎉"WIT: Wikipedia-based Image Text Dataset for Multimodal Multilingual Machine Learning" Srinivasan et al
🎉"Assessing the quality of sources in @Wikidata across languages: a hybrid approach" Amaral et al
Superintelligence will be built on Self Improvement.
Today @hexoai, we’re excited to release ‘SIA’ - an open-source Self-Improving AI, to achieve any goal through recursive self improvement.
While trying to solve a problem, SIA doesn't just improve it's abilities by updating it's harness, it updates it's own weights as well.
Doing a startup and organizing taxes ... couldn't help but contemplate between AGI [1] and AGI [2].
AGI [1] = Artificial General Intelligence
AGI [2] = Adjusted Gross Income
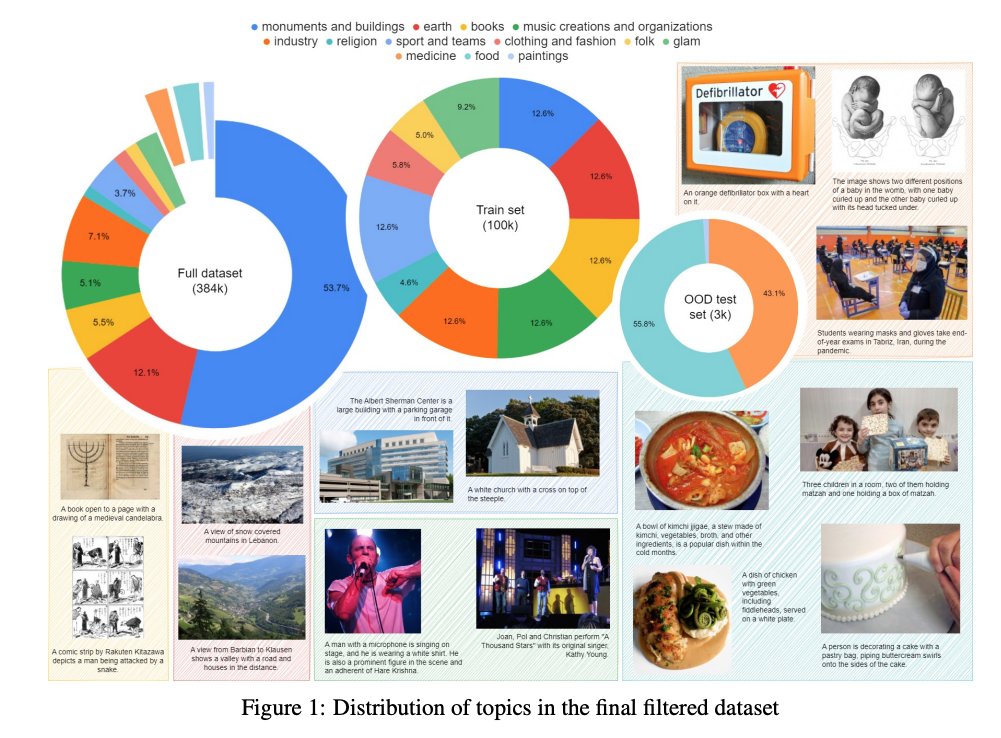
"WikiDO: A New Benchmark Evaluating Cross-Modal Retrieval for Vision-Language Models", consisting of 384K image-text pairs from Wikipedia with domain labels, along with human-verified in/out distribution test sets.
(Kalyan et al, 2024)
https://t.co/ys7gU3eGO9
@karpathy Eureka we have a lab, Eureka Labs, where we can learn AI the way it is meant to be taught. Fantastic news and couldn't think of a better person to do this. Looking forward to learning. Congratulations and best wishes!
@rasbt Thanks so much for this great work. I am having lots of run reading this and the ML Q&A books. Paraphrasing a popular quote, "What one can't build, do and teach, one doesn't truly understand".
@YiTayML Deep respect for you @YiTayML ! Reminded of Nietzsche's “He who has a why to live for can bear almost any how.”. Stay sane and best wishes my good friend!
For more information the full guidelines are available https://t.co/PLUFIqtwaC and organisers will be more than happy to help with any problem / answer any question (just tweet or send an email to [email protected])
The final test topics will be released soon, but there’s a lot of material to start playing with" such: embeddings of openCLIP models + dev topics with human judgements over the baselines (https://t.co/ha75jGzmFJ).
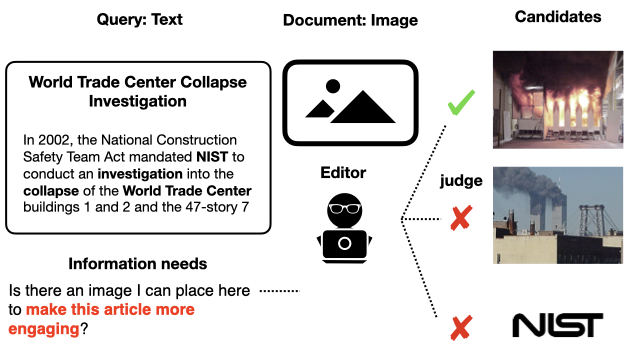
Interested in Cross-Modal retrieval? Feel that evaluation on caption datasets is limited and noisy?
The @TREC_AToMiC task is here: a real, large scale problem (retrieve illustration for @Wikipedia sections), with human judgements. Deadline in 45 days!
@krishna2@lintool