Les données disponibles sur https://t.co/Yz6AmwMTfb sont désormais interrogeables via un serveur MCP dédié en experimentation, vos retours sont bienvenus !
💻 Le code est ouvert et accessible sur GitHub :
https://t.co/AmY04V22TH
Pour en savoir plus : https://t.co/V7UJrc6uUq
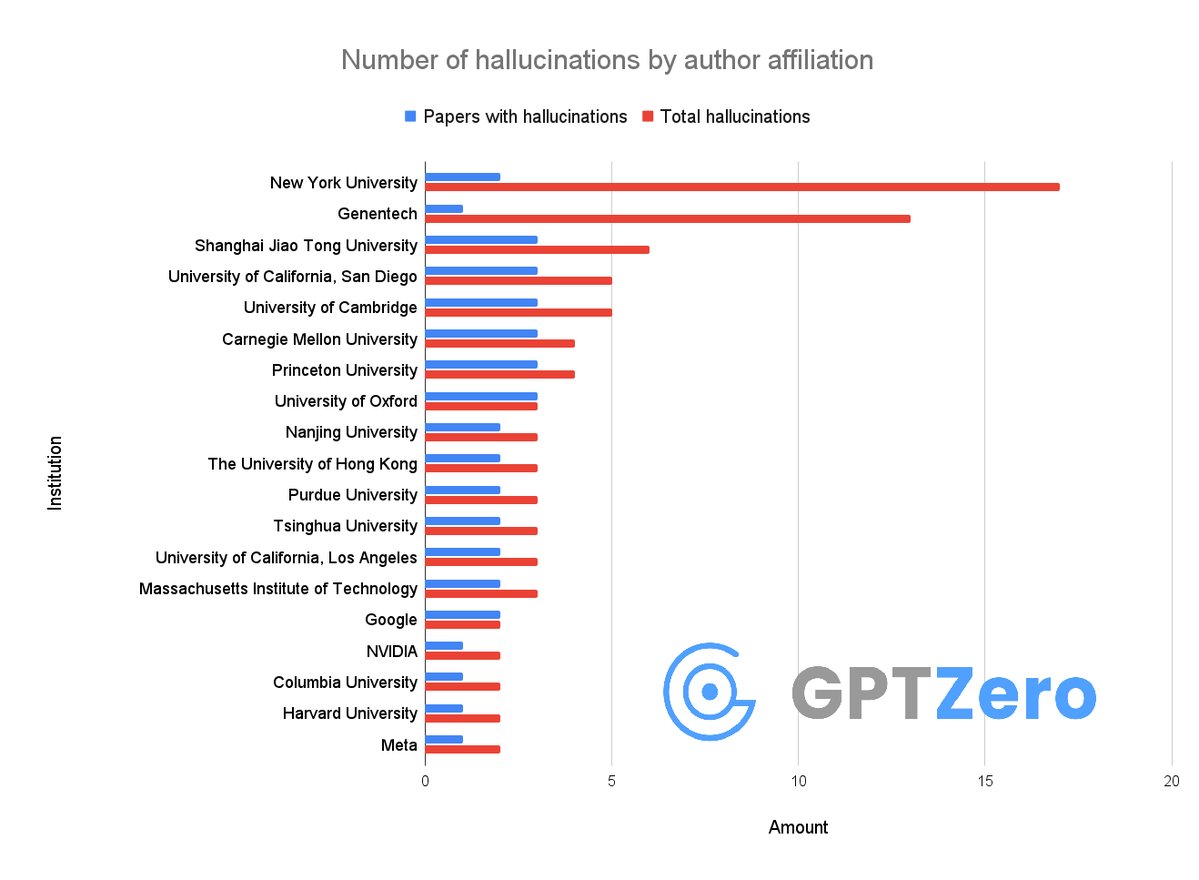
Okay so, we just found that over 50 papers published at @Neurips 2025 have AI hallucinations
I don't think people realize how bad the slop is right now
It's not just that researchers from @GoogleDeepMind, @Meta, @MIT, @Cambridge_Uni are using AI - they allowed LLMs to generate hallucinations in their papers and didn't notice at all.
It's insane that these made it through peer review👇
Have you ever typed import mne in #Python?
Did it help you publish a paper, save hours, or even land your dream job? 💡
Now’s your chance to give back — @mne_news can finally receive 💸 donations to keep the lights on (CIs, forum, etc.) 🙌 https://t.co/bPPOgp2gqT
🛎️ We have several ML/AI research internships available this academic year at @doctolib !
If you want to apply AI to transform healthcare, get in touch (links in thread)
1/ Apple researchers just dropped NEW foundation model on BEHAVIORAL data from wearables.
Forget raw sensors—think steps, heart variability, gait
Trained on 2.5B hours via 162K people
Predicts age, sex, pregnancy, sleep like a crystal ball.
An abbreviation (ABB) in a journal article (JA) or Grant Application (GA) is rarely worth the words it saves. Every ABB requires cognitive resources (CR) and at my age by the time I'm halfway through a JA or GA I no longer have the CR to remember what your ABB stood for.
Today, Google Research & @GoogleDeepMind introduce g-AMIE, an extension of our diagnostic AI system based on #Gemini 2.0 Flash. It uses a guardrail that prohibits medical advice sharing & instead provides a summary for a physician to review. Learn more: https://t.co/zXc2yWRWLn
1/ People are saying exercise is just as effective as therapy for depression—based on a study that’s gotten a lot of public attention (below 👇)
Here’s the truth:
1️⃣ Research subjects who exercised showed some minimal improvement—but not enough to matter
2️⃣The research subjects weren’t clinically depressed to begin with
3️⃣We already know antidepressants and brief therapy (pretty much all that’s ever studied in research trials) are woefully inadequate treatment. The overwhelming majority of patients who get these treatment do not get well
🚀 Big news in healthcare AI! I'm thrilled to announce the launch of OpenMed on @huggingface, releasing 380+ state-of-the-art medical NER models for free under Apache 2.0.
And this is just the beginning! 🧵
Microsoft claims their new AI framework diagnoses 4x better than doctors.
I'm a medical doctor and I actually read the paper. Here's my perspective on why this is both impressive AND misleading ... 🧵
Announcing Biomni — the first general-purpose biomedical AI agent. Biomni is a free web platform where biomedical scientists can immediately delegate their tasks to Biomni, starting today!
Biomni automates literature reviews, hypothesis generation, protocol design, bioinformatics analysis, clinical reasoning, and much more — scaling biomedical expertise for 100× the number of discoveries.
Key results:
➡️ Designed a cloning experiment with real-world wet-lab validation; on par with 5+ year expert in a blind test
➡️ Ran 458-file wearable bioinformatics analysis in 35 minutes vs. 3 weeks (800x faster) for human expert
➡️ Uncovered novel hypothesis: new TFs regulating skeletal lineages on a large scRNA+scATAC data
➡️ Human-level performance on LAB-bench DbQA and SeqQA, with SOTA at Humanity’s Last Exam and across 8 new biomedical tasks—ranging from GWAS and rare disease diagnosis to microbiology and drug repurposingPowered by:
➡️ Biomni-E1 – the first unified environment designed for a biomedical agent—encompassing 150 tools, 59 databases, 106 software—systematically curated from 2,500+ bioRxiv papers
➡️ Biomni-A1 – a generalist agent with retrieval, planning, and code as action
Biomni is an open-source initiative: we invite the community to build on it and advance biomedical research at scale.
- Try it now: https://t.co/GyZdCKEKYN
- Paper: https://t.co/lgtyUEGfEy
- Code: https://t.co/vqq9W6Zkv3
- Join the community: https://t.co/2C7rWOPp2z
Amazing team and collaborators @StanfordAILab@StanfordMed@StanfordCancer@genentech@arcinstitute@UCSF@UW@PrincetonAInews@KexinHuang5@serena2z@hcwww_@YuanhaoQ@mintaylu@yusufroohani @RyanLi0802 @LinQiu0128 Gavin Junze Di Shruti Jennefer Xin Zhou @MWheelerMD Jon Bernstein @MengdiWang10@PengHeAtlas@SnyderShot@lecong Aviv Regev
To do so, you concatenate all the sequences to make a batch of a single sequence, and carve the attention matrix into a block-diagonal one (possibly with causal structure in each block) so that sequences cannot look at each other.
Magic!
3/3
Meta Orion / CTRL labs typing paper is out! They have released code and data, well done.
Performance is about 7% character error rate after per-user finetuning, which I estimate is ~10% word error rate, at the cusp of usable. BUT (it's a biggie)
This task is done with people typing on a physical keyboard. For the technology to provide value, it needs to be useful for typing without a physical keyboard present, whether in AR/VR, on a desk, or in your pocket.
Presumably that's the subject of on-going work. It's not clear to me that people can reliably type without visual or tactile feedback. The location of the home row will drift and people will likely fail to move towards the correct location for letters.
If only there was some other part of the body that can do language without a keyboard... ;)
Nonetheless this is a big step forward for wrist-based EMG, congrats to all and thanks for the open science.
https://t.co/KI42lmTLkq
1/
We just open-sourced two large wrist electromyography (EMG) datasets - one towards typing without a keyboard and the other for predicting hand poses - with baselines.
We believe these will help advance research into making high bandwidth non-invasive neuromotor interfaces a reality!
People are often surprised to learn that it is standard for companies to preinstall spyware on work computers (often surveilling passively / for security). AI can “improve” this significantly. It is good hygiene to not login to or mix anything personal on company computer.
David had a great idea: train people to expect a stimulus, and then, upon violating said expectation, he modeled the brain response by the divergence in different layers of a visual ANN.
Later layer differences explained the signal in EVC better than early layer differences.