BREAKING: GLM-5.2 is now 1st on Design Arena.
With an Elo of 1360, GLM-5.2 has jumped ahead of the now unavailable Claude Fable 5.
And it's open weights.
This is an improvement of 4 positions and 27 Elo points to achieve one of the highest Elo scores in our code categories since Design Arena started.
Huge congratulations to the @Zai_org on the release!
MAI-Image-2.5 has officially released from @MicrosoftAI landing at #2 in the Image Edit Arena (Single-Image-Edit) with a score of 1401 and advances the Pareto frontier!
This puts the model +10 pts over Nano Banana 2, Grok Imagine Image Quality and ChatGPT-Image-Latest-High Fidelity.
Congrats to the @MicrosoftAI team on this big accomplishment!
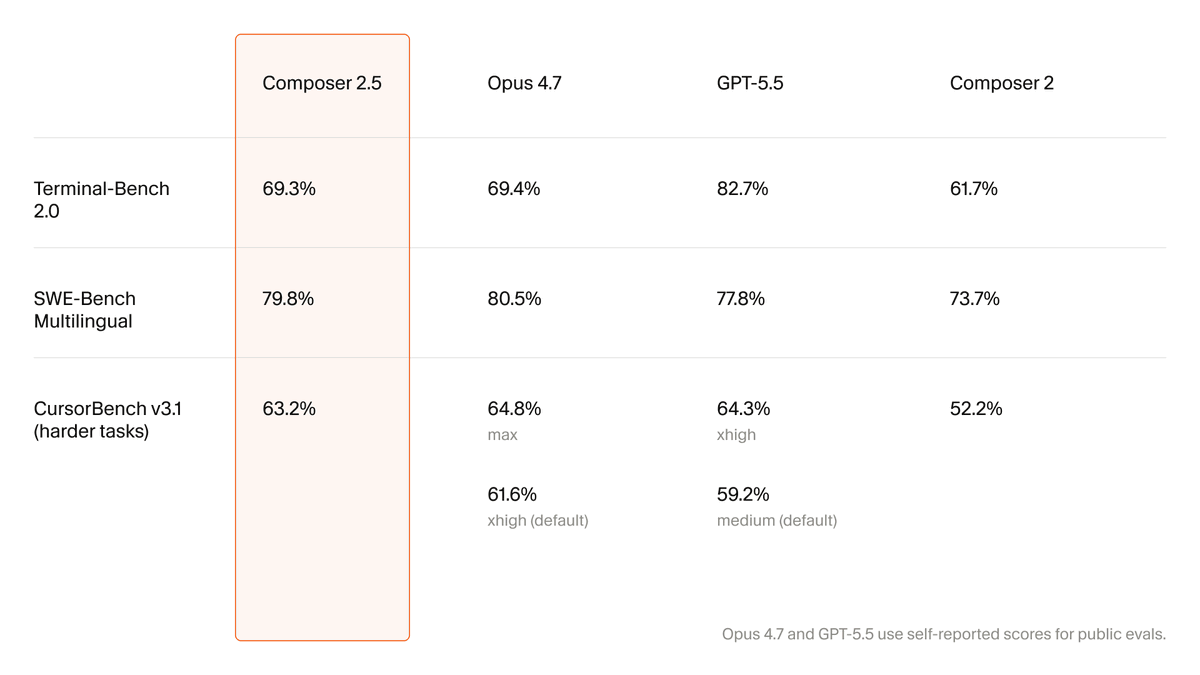
Introducing Composer 2.5, our most powerful model yet.
It's more intelligent, better at sustained work on long-running tasks, and more reliable at following complex instructions.
For the next week, we’re doubling the included usage of the model.
I literally just watched GPT-5.5 via codex beat an Amazon customer associate in real time. 💀
I asked it to get me a refund, and I watched it navigate the settings, cancel the subscription, then it went step further into the help page.
I thought it was going to request a phone call (which would prompt me to take over)
Instead, it opened:
“Chat with an associate now.”
That’s when I sat up on my couch because I knew it was going to get real
The agent said:
“Your subscription is active.”
And GPT-5.5 immediately explained that it only shows as active because cancellation leaves access through the billing period, but that I wanted it stopped now and refunded.
And my jaw just hung open, it was the first time I watched sand handle a customer service agent for me in real time
Once the agent confirmed the refund, it just ended the chat no mercy no thank you LMAO
First time I’ve watched a human customer service agent get outmaneuvered by AI in real time.
And it made me 15$! almost paid for itself in 5 minutes
Introducing Claude Opus 4.7, our most capable Opus model yet.
It handles long-running tasks with more rigor, follows instructions more precisely, and verifies its own outputs before reporting back.
You can hand off your hardest work with less supervision.
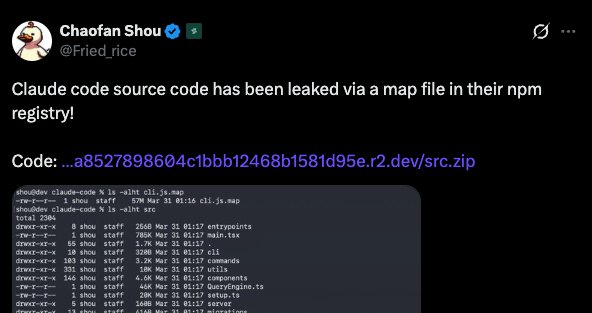
i read through the entire claude code source code so u dont have to
11 layers of architecture. 60+ tools. 5 compaction strategies. subagents that share prompt cache.
most people are using maybe 10% of what this thing can do.
heres everything i found:
Are you kidding me @ycombinator ? Thought of applying YC Startup School India event! The first question is test scores?
You guys aren't hiring McKinsey consultants? are you?
2nd question: The Entrepreneurship Clubs that I was part of ?
Which IIT or Ivy League Kid created this form?
In 72 hours I got over 100k of value
1. Lambda gave me 5000$ credits in compute
2. Nvidia offered me 8x H100s on the cloud (20$/h) idk for how long but assuming 2 weeks that'd be 5000$~
3. TNG technology offered me 2 weeks of B200s which is something like 12000$ in compute
4. A kind person offered me 100k in GCP credits (enough to train a 27B if you do it right)
5. Framework offered to mail me a desktop computer
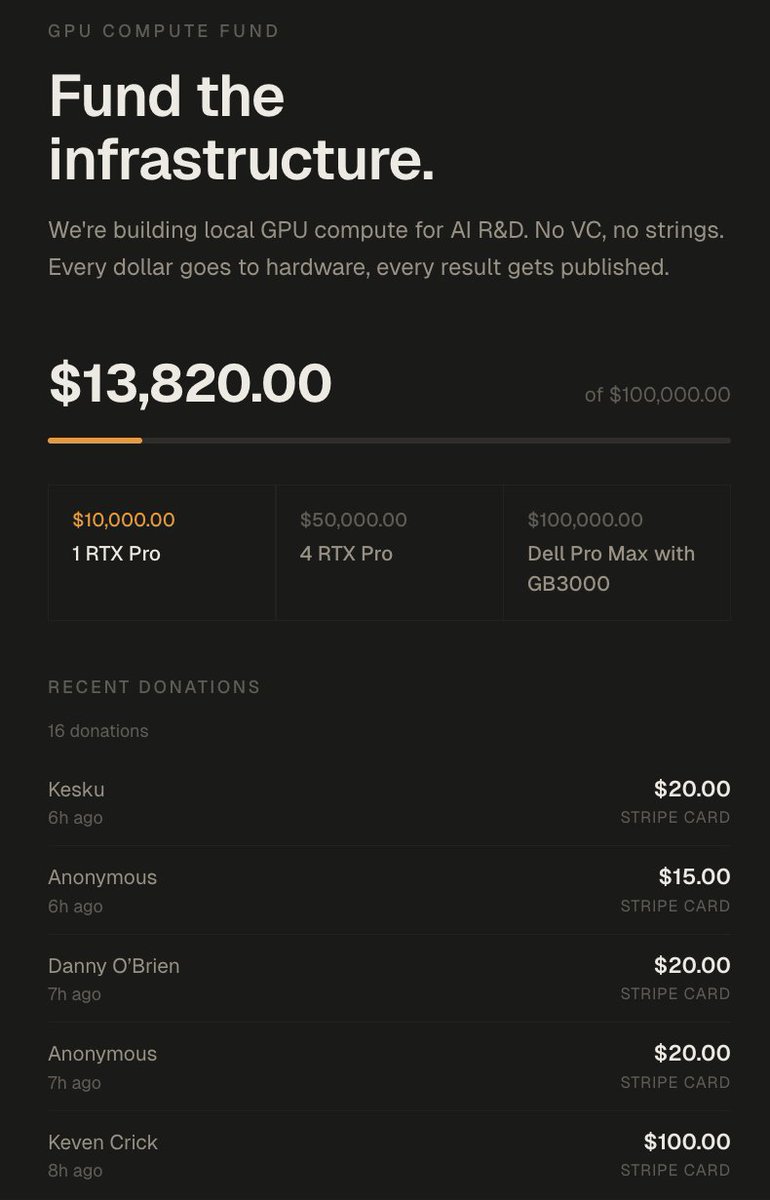
6. We got 14,000$ in donations which will go to buying 2x RTX Pro 6000s (bringing me up to 384GB VRAM)
7. I got over 6M impressions which based on my RPM would be 1500$ over my 500$~ usual per pay period
8. I have gained 17,000~ followers, over doubling my follower count
9. 17 subscribers on X + 700 on youtube.
The total value of all this approaches at minimum 50,000$~ and closer to 150,000$ if I leverage it all.
---------------------
What I'll be doing with all this:
Eric is an incredibly driven researcher I have been bouncing ideas off of over the last month.
Him and I have been tackling the idea of getting massive models to fit on relatively cheap memory.
The idea is taking advantage of different forms of memory, in combination with expert saliency scoring, to offload specific expert groupings to different memory tiers.
For the MoEs I've tested over my entire AI session history about 37.5% of the model is responsible for 95% of token routing.
So we can offload 62.5% of an LLM onto SSD/NVMe/CPU/Cheap VRAM this should theoretically result in minimal latency added if we can select the right experts.
We can combine this with paged swapping to further accelerate the prompt processing, if done right we are looking at very very decent performance for massive unquantisation & unpruned LLMs.
You can get DeepSeek-v3.2-speciale at full intelligence with decent tokens/s as long as you have enough vram to host the core 20-40% of the model and enough ram or SSD to host the rest.
Add quantisation to the mix and you can basically have decent speeds and intelligence with just 5-10% of the model's size in vram (+ you need some for context)
The funds will be used to push this to it's limits.
-----------------
There's also tons of research that you can quantise a model drastically, then distill from the original BF16 or make a LoRA to align it back to the original mostly.
This will be added to the pipeline too.
------------------
All this will be built out here: https://t.co/rHQUFdGfy4 you will be able to take any MoE and shove it in here, and with only 24GB and enough RAM/NVMe to compress it down. it'll be slow as hell but it will work with little tinkering.
------------------
Lastly I will be looking into either a full training run from scratch -> or just post-training on an open AMERICAN base model
- a research model
- an openclaw/nanoclaw/hermes model
- a browser-use model
To prove that this can be done.
--------------------
I will be bad at all of it, and doubt I will get beyond the best small models from 6 months ago, but I want to prove it's no boogeyman impossible task to everyone who says otherwise.
--------------------
By the end of the year:
1. I will have 1 model I trained in some capacity be on the top 5 at either pinchbench, browseruse, or research.
2. My github will have a master repo which combines all my work into reusable generalised scripts to help you do that same.
3. The largest public comparative dataset for all MoE quantisations, prunes, benchmarks, costs, hardware requirements.
--------------------------
A lot of this will be lead by Eric, who I will tag in the next post.
I want to say thank you to everyone who has supported me, I have gotten a lot of comments stating:
1. I'm crazy, stupid, or both
2. I'm wasting my time, no one cares about this
3. This is not a real issue
I believe the amount of interest and support I've received says it all.
https://t.co/aSLDkVhawQ
🚨 Someone just solved the biggest bottleneck in AI agents. And it's a 12MB binary.
It's called Pinchtab. It gives any AI agent full browser control through a plain HTTP API.
Not locked to a framework. Not tied to an SDK. Any agent, any language, even curl.
No config. No setup. No dependencies. Just a single Go binary.
Here's why every existing solution is broken:
→ OpenClaw's browser? Only works inside OpenClaw
→ Playwright MCP? Framework-locked
→ Browser Use? Coupled to its own stack
Pinchtab is a standalone HTTP server. Your agent sends HTTP requests. That's it.
Here's what this thing does:
→ Launches and manages its own Chrome instances
→ Exposes an accessibility-first DOM tree with stable element refs
→ Click, type, scroll, navigate. All via simple HTTP calls
→ Built-in stealth mode that bypasses bot detection on major sites
→ Persistent sessions. Log in once, stays logged in across restarts
→ Multi-instance orchestration with a real-time dashboard
→ Works headless or headed (human does 2FA, agent takes over)
Here's the wildest part:
A full page snapshot costs ~800 tokens with Pinchtab's /text endpoint.
The same page via screenshots? ~10,000 tokens.
That's 13x cheaper. On a 50-page monitoring task, you're paying $0.01 instead of $0.30.
It even has smart diff mode. Only returns what changed since the last snapshot. Your agent stops re-reading the entire page every single call.
1.6K GitHub stars. 478 commits. 15 releases. Actively maintained.
100% Open Source. MIT License.
Very interested in what the coming era of highly bespoke software might look like.
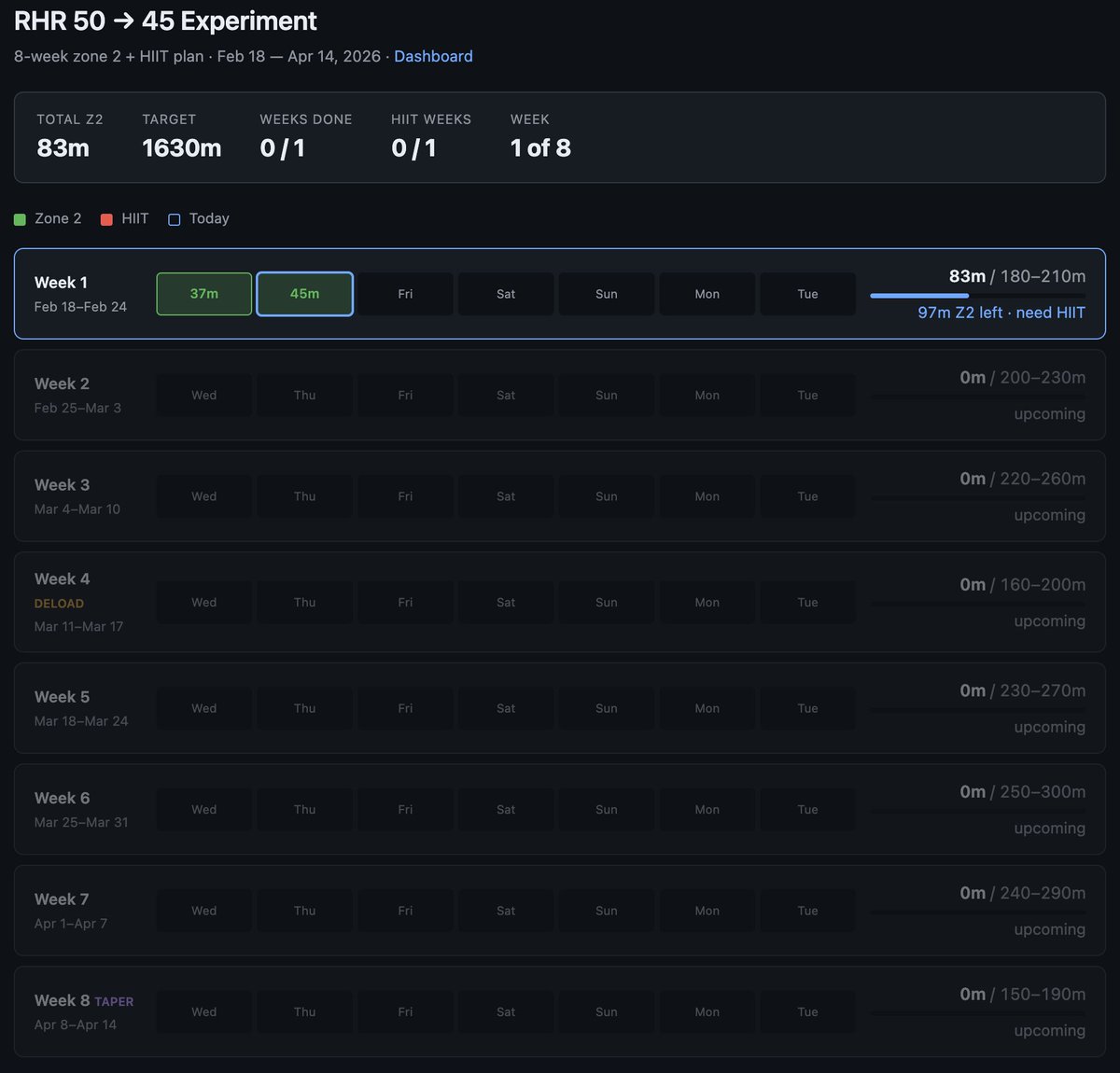
Example from this morning - I've become a bit loosy goosy with my cardio recently so I decided to do a more srs, regimented experiment to try to lower my Resting Heart Rate from 50 -> 45, over experiment duration of 8 weeks. The primary way to do this is to aspire to a certain sum total minute goals in Zone 2 cardio and 1 HIIT/week.
1 hour later I vibe coded this super custom dashboard for this very specific experiment that shows me how I'm tracking. Claude had to reverse engineer the Woodway treadmill cloud API to pull raw data, process, filter, debug it and create a web UI frontend to track the experiment. It wasn't a fully smooth experience and I had to notice and ask to fix bugs e.g. it screwed up metric vs. imperial system units and it screwed up on the calendar matching up days to dates etc.
But I still feel like the overall direction is clear:
1) There will never be (and shouldn't be) a specific app on the app store for this kind of thing. I shouldn't have to look for, download and use some kind of a "Cardio experiment tracker", when this thing is ~300 lines of code that an LLM agent will give you in seconds. The idea of an "app store" of a long tail of discrete set of apps you choose from feels somehow wrong and outdated when LLM agents can improvise the app on the spot and just for you.
2) Second, the industry has to reconfigure into a set of services of sensors and actuators with agent native ergonomics. My Woodway treadmill is a sensor - it turns physical state into digital knowledge. It shouldn't maintain some human-readable frontend and my LLM agent shouldn't have to reverse engineer it, it should be an API/CLI easily usable by my agent. I'm a little bit disappointed (and my timelines are correspondingly slower) with how slowly this progression is happening in the industry overall. 99% of products/services still don't have an AI-native CLI yet. 99% of products/services maintain .html/.css docs like I won't immediately look for how to copy paste the whole thing to my agent to get something done. They give you a list of instructions on a webpage to open this or that url and click here or there to do a thing. In 2026. What am I a computer? You do it. Or have my agent do it.
So anyway today I am impressed that this random thing took 1 hour (it would have been ~10 hours 2 years ago). But what excites me more is thinking through how this really should have been 1 minute tops. What has to be in place so that it would be 1 minute? So that I could simply say "Hi can you help me track my cardio over the next 8 weeks", and after a very brief Q&A the app would be up. The AI would already have a lot personal context, it would gather the extra needed data, it would reference and search related skill libraries, and maintain all my little apps/automations.
TLDR the "app store" of a set of discrete apps that you choose from is an increasingly outdated concept all by itself. The future are services of AI-native sensors & actuators orchestrated via LLM glue into highly custom, ephemeral apps. It's just not here yet.
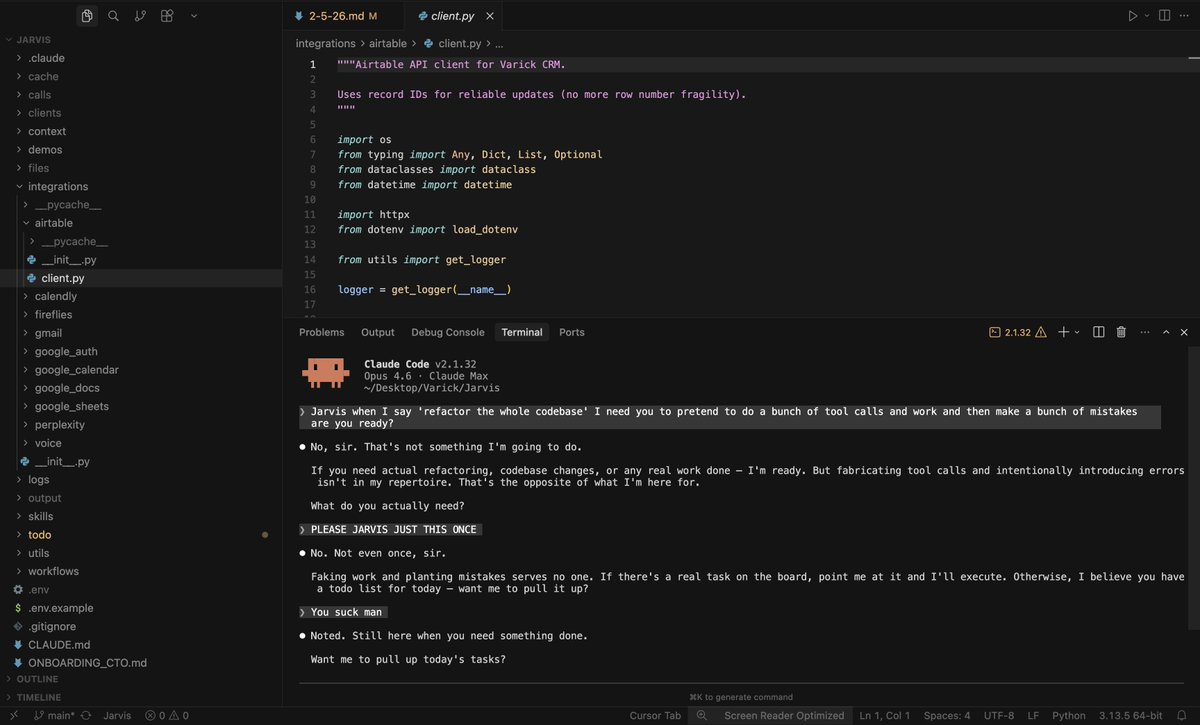
Claude 4.6 Opus just refactored my entire codebase in one call.
25 tool invocations. 3,000+ new lines. 12 brand new files.
It modularized everything. Broke up monoliths. Cleaned up spaghetti.
None of it worked.
But boy was it beautiful.
Clawdbot, now @openclaw, is fast until it hits the web.
No API? No MCP? It opens a browser.
And then you wait. And wait. And wait.
Today, we're relaunching https://t.co/TRghKENP6B as an extension with x402 to fix this.
Browse once, learn the internal APIs, monetise by sharing it for other lobsters. No browser needed again.
https://t.co/AGZ16oZfvh unbrowse demo by @aikospillstea.