The Ma'ayan Lab specializes in developing algorithms and software for the integration, analysis, and visualization of omics datasets. #Enrichr#bioinformatics
Join us on Thur. July 24 @ 2 PM ET for a virtual seminar about ChEA-KG, a newly developed @MaayanLab web-based app that enables users to analyze their gene sets in context of a human gene regulatory network (1559 transcription factors). Please register at https://t.co/oZ7SQR8vjo
Genes in cells are a bit like words, and gene sets are like sentences b/c genes are reused in different contexts; To learn the language of the cell, @MaayanLab developed: A #GeneSet#FoundationModel Pre-Trained on a Massive Collection of Diverse Gene Sets https://t.co/Xasuczu9o7
Join us on Thursday, February 27 at 2:00 PM ET for a virtual seminar featuring ARCHS4, a web resource that streamlines access to over two million uniformly aligned RNA-seq samples from GEO. Please register in advance: https://t.co/zFA2YA2Fy3
Join us on Thursday, January 23 at 2:00 PM ET for a virtual seminar featuring GeneSetCart, a web application for multi-omics AI-driven gene set analysis. Please register in advance for this virtual seminar: https://t.co/7zDQisBt7i
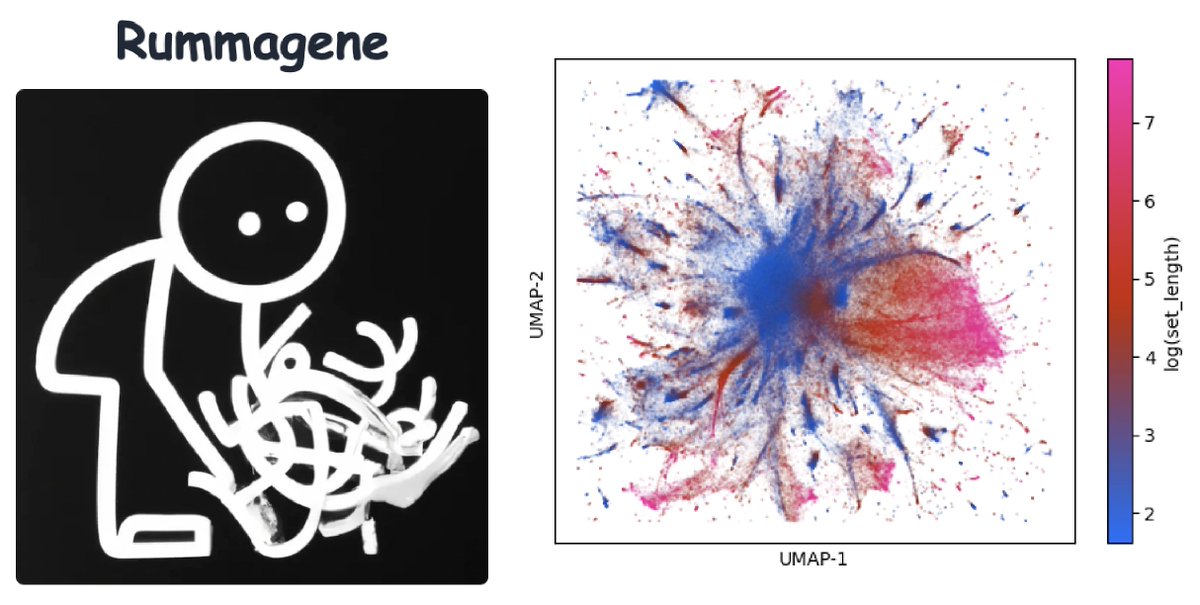
Our #RummaGEO (https://t.co/xTKOGZ783c) paper is out in Patterns: https://t.co/3tjqcZuZ4X
Developed @MaayanLab#RummaGEO provides access to 171,441 human and 195,265 mouse gene sets mined from 29,294 @NCBI GEO RNA-seq studies uniformly aligned with #ARCHS4 https://t.co/axgdwJq3kt
The Summer Research Training Program in Biomedical Big #DataScience in the @MaayanLab@IcahnMountSinai is accepting applications for summer session 2025! Application deadline is Feb 1. Program details: https://t.co/iSuyEy2V77
From @AviMaayan, @PeiMSSM2016, and colleagues:
Multiomics2Targets identifies targets from cancer cohorts profiled with transcriptomics, proteomics, and phosphoproteomics: Cell Reports Methods https://t.co/PLACvhF9lI
@IcahnMountSinai
Join our Virtual Symposium in Big #DataScience on 8/8 @ 10 AM ET where the @Maayanlab trainees in the 2024 Summer Undergraduate Research Training Program in Biomedical Big #DataScience will present their research projects. Register: https://t.co/54kGNJtDtM
Want to build #bioinformatics workflows with ease? Learn about the Playbook Workflow Builder & how to create workflows in this virtual workshop on 6/25 at 1PM ET. Learn more: https://t.co/qFdje2XvbI #DataScience#Biomedicine#DataEcosystem
Join us on Tuesday, June 25th at 1:00 PM ET for a virtual workshop introducing the Playbook Workflow Builder: https://t.co/WCYBgHh37V, a new #bioinformatics platform to interactively create #workflows with no coding skills. Registration: https://t.co/QwRO3vvE38 #genomics#omics
A great talk by @AviMaayan and his team on Tuesday at the @SinaiGenetics WIP in Computational Biology and Data Science, showcasing their excellent new bioinformatic interfaces, including Rummagene and others.
On Friday 5/31 @ 1 PM ET, members of the @CfdeWorkbench will introduce new tools to query the @LINCSProgram L1000 data and gene expression signatures automatically extracted from @NCBI#GEO https://t.co/5AUfjLcOYO register: https://t.co/ppsZpyQozx
Rummagene is a search engine for gene sets, created by extracting human and mouse gene sets from supporting materials of >120,000 biomedical research publications: https://t.co/Mk93uwYQcR @AviMaayan@MaayanLab
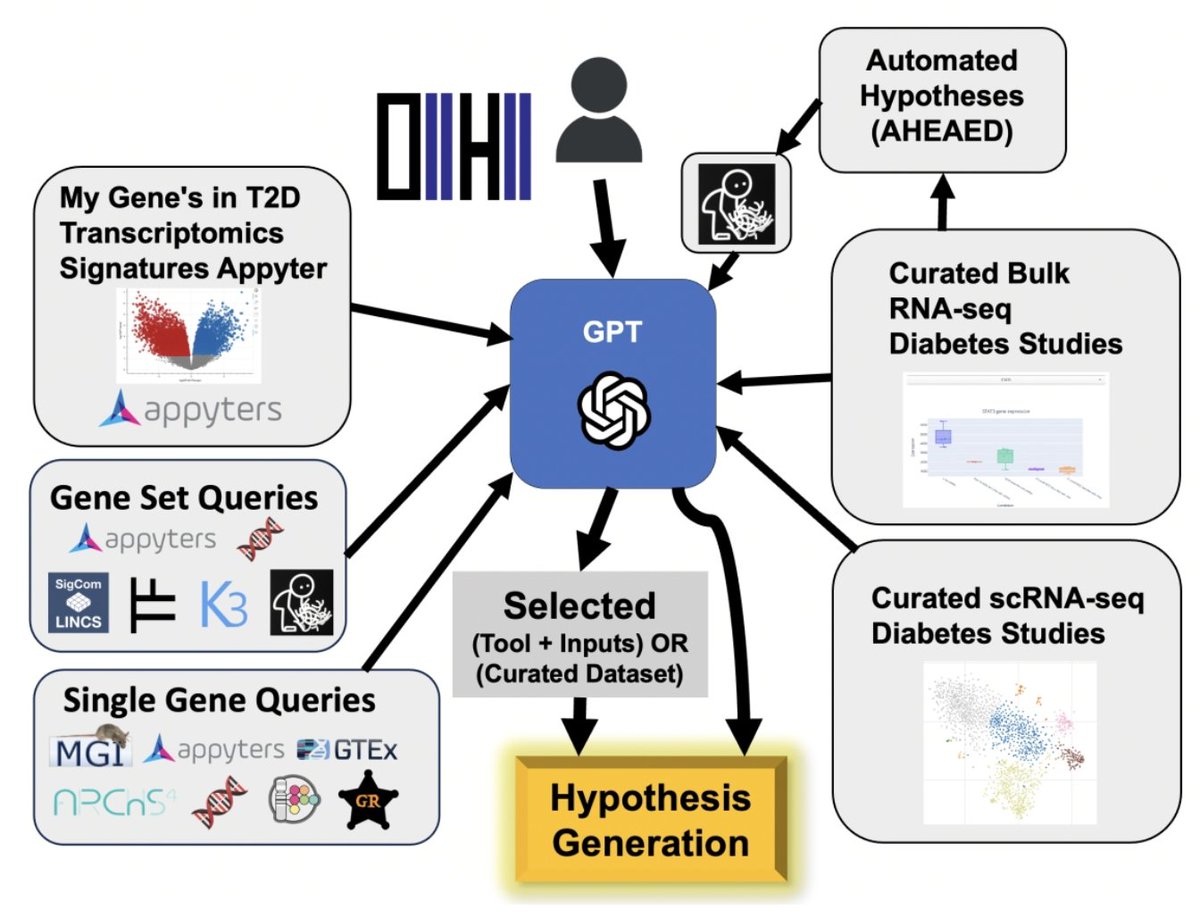
🧬🔍 Dive into the Diabetes & Data Exploration with D2H2! The Diabetes and Data and Hypothesis Hub is a transformative platform unlocking the potential of omics datasets in diabetes research. https://t.co/yPhHqGvuzD @AviMaayan@IcahnMountSinai
The new #NIH_CFDE Data Resource Center will create a portal to catalyze user-friendly queries of Common Fund data sets and connect users to Common Fund resources to enable new discoveries only possible by searching across Common Fund data. https://t.co/JvsQA7Ue3u
Say hello to #Rummagene available from: https://t.co/xTKOGZ783c. To create it @maayanlab scanned supp. materials of 5.4M #PMC articles to find 642K human gene sets. Sets are served for enrichment, free text, and table title search. Paper is now on @biorxiv https://t.co/Nvu2qslkwV