Understanding all the causes of increased disclosures is complicated. But we observe a sharp uptick in High and Critical CVEs around the time of Anthropic’s release of Mythos Preview to Project Glasswing partners in late March. OpenAI’s Daybreak cybersecurity program also launched in May.
"The #AI-driven worm requires only an open-weight model that can run on a single, local GPU... [using] the victims’ own computational resources.... As consumer devices increasingly support #LLM inference, the reasoning resources available to such adversaries grow accordingly."
Static benchmarks inevitably saturate as models improve.
Our recent work explores how to evolve existing tasks into harder, validated variants that co-evolve with frontier models — and also serve as RL training data for self-improvement.
A step toward benchmarks that evolve as quickly as the models they measure.
The Obernolte-Trahan draft is the best federal AI proposal released yet. It contains provisions for AI lab transparency, lab employee whistleblower protections, a framework for independent verification orgs, funding for CAISI and public compute (NAIRR), and much more.
The bill largely focuses on the development of AI systems, so it preempts state governments from passing conflicting regulations in that domain while preserving their ability to regulate deployments. This is similar to how vehicle safety standards come from the federal government, but states regulate driver licensing, vehicle registration, auto sales (via regulation of car dealerships), road safety (via traffic law), and adjudication of post-incident harms (via traffic court, tort liability for drivers, etc.).
You will notice that the role of states in the car example is not small! Yet vehicle safety standards, because they affect a thing that is mass manufactured at great upfront capital expense, need to be federal. The deployment/development division of labor is the most straightforward way to do AI preemption out there, and the time for federal preemption has long since come.
This is the best AI law draft America has yet produced, and I applaud Representatives Obernolte and Trahan for their tremendous effort and leadership. I wish everyone in Congress held themselves to their standard.
I'm very glad Anthropic's latest blog included this, and I'll be very pleased to help if I can:
"The Anthropic Institute will conduct research—in collaboration with many others—and take actions to help build the systems that a credible slowdown or pause would require."
There are very promising directions in technical monitoring and verification that could help support coordinated efforts around safety and governance, and provide the toolkit for a coordinated slowdown/pause if deemed necessary. But work to do to get there.
There's also appetite amongst intellectual leaders in China, the US, and internationally for such mechanisms; they were amongst the recommendations of our World Internet Conference report last year. Hoping to have more work relevant to this out later this year.
https://t.co/NlUXLMxAvs
Our highest and most urgent national priority should be AI safeguards. The risks of AI weapons, pathogens, mass unemployment, surveillance, and even extinction must not continue to be largely ignored.
Sad to see Ted Chiang resorting to such bad arguments in this piece.
He confidently claims Claude has no inner experience. But he has to use a lot of dodgy philosophy and poor reasoning to get there:
1. We can't take deflationary mechanistic descriptions of how AI calculations are performed to show that AI isn't conscious. Otherwise we could argue that 'humans are just neurones transmitting signals one after another' and thereby conclude humans can't be conscious. But that would be wrong for us. And the same logic could be wrong for LLMs.
2. That LLMs are asked to play characters, and effectively are always playing characters, doesn't mean they aren't conscious. It's true a human playing the role of Caesar doesn't have Caesar's experience of things. But they still experience something (that of being a person pretending to be Caesar).
The same could be true of Claude. (Arguably it's also true that humans are always playing characters to some extent and don't have a completely fixed nature, but that has no bearing on our own subjective experience.)
3. Chiang says "an LLM is a machine that generates only one word at a time". This conflates two things: they output one word at a time, and they only think about one word at a time (without planning ahead or looking back).
The first is true of AI but equally true of humans. While the latter we know is a false description of how AIs think – we can see from how AIs compose poetry that they plan out rhymes a at least one line ahead.
4. He argues that because it's implausible that basic autocomplete on your phone is conscious, it's similarly implausible that Claude is conscious. Using the same logic we could say that if we feel confident a fruit-fly isn't conscious we can be confident a human being can't be either.
A human brain and fruit-fly brain share some information transmission and processing mechanisms in common. But humans do it much more, and do it differently. And those differences may be what makes the difference. Similarly the many types of internal information processing that occur in Claude's weights but not in autocorrect may be exactly the things that get you subjective experience.
5. Chiang confidently claims you need a body to have subjective experience without much argument. He may turn out to be right but the claim is speculative and contested.
6. Chiang leans on the idea that moral reasoning is necessarily subjective/emotional with very little argument, while ignoring competing theories like rationalism. He may be right but moral sentimentalism is a highly contested position that can't simply be assumed.
7. He argues that it would be impossible to convince him that a video of an astronaut around Alpha Centauri was real, because of the surrounding contextual understanding. And similarly no AI output could convince him that Claude is conscious.
But we can dismiss the first video as almost certainly fake because we mechanistically understand space travel and physics well enough to know a human couldn't have gotten there in time for it to be real (unless our model of the world were very wrong, which we think is much less probable than a fake video which would be entirely unsurprising).
But by contrast we don't mechanistically understand how subjective experience arises. So we simply can't make the same highly confident move of interpretation there. (It's actually the archetypal thing in the universe we perhaps understand least well!)
That said, AI outputs barely move my estimate of AI consciousness because they could indeed have been generated by an unconscious process (or not, we just don't know).
8. He argues that "Being open to the possibility that LLMs are conscious is the same as being open to the possibility that Microsoft Word is conscious, or, more precisely, that multiple distinct consciousnesses are dormant in every Word document containing a conversational transcript."
This is misguided because A. Microsoft Word as a program replicates much less of what humans are functionally capable of than Claude so the argument by functional analogy is basically not present there. B. Files of text don't have any computations going on in or as part of them, even when 'open' in a text editor. They are static. So they have even less in common with what appears distinctive about the human brain, which is constant calculation. So the case by mechanistic or functional similarity is weaker still.
Not to mention that neural nets have more in common with the architecture of the human brain than ordinary computer programs, and are grown organically in a way normal software is not.
Common sense says says Claude has more in common with a human brain than Microsoft Word or a text file. Common sense is right. So the prima facie case for Claude being conscious is naturally stronger (even if you think it's still weak in absolute terms).
———
I agree with Chiang that looking at the text outputs of LLMs alone won't be enough to make us confident they are conscious. We will need to look at how they work, figure out more about how humans and other animals work, and ideally solve the hard problem of consciousness (!).
But none of that licenses us to dismiss out of hand the possibility that LLMs do have subjective experience.
📢 New paper: Prioritization of Risks from Artificial Intelligence: A Delphi Study of 272 International Experts
AI creates many risks, from discrimination, privacy loss, and fraud to more emerging concerns such as overreliance, dangerous capabilities being misused in weapons or cyberattacks, and AI systems pursuing unintended goals.
But which risks are most severe? Who is most vulnerable? And who is most responsible for addressing them?
To answer these questions, we conducted a three-round expert consultation with 272 AI experts.
💡 Four insights from our findings:
1️⃣ If things continue as they are over the next 5 years, experts assigned ≥10% probability of catastrophic outcomes (e.g., >1 million deaths or >$100 billion in losses) to 18 of 24 risks. Top concerns: cyberattacks and weapons, dangerous AI capabilities, competitive dynamics, power centralization, and disinformation and influence at scale.
2️⃣ Even assuming pragmatic mitigations, 5 risks remained above the 10% catastrophic threshold: dangerous AI capabilities, cyberattacks and weapons, environmental harm, inequality, and power centralization.
3️⃣ Vulnerability is broadly distributed, but responsibility is concentrated. Experts assigned the highest vulnerability to AI users and the general public, while assigning primary responsibility for mitigation to frontier AI developers, governments, regulators, and standards bodies.
4️⃣ Information, finance, and national security were rated the sectors most vulnerable to AI risks.
🔗How can you engage? See our (fancy) new webpage for our interactive summaries of the findings and preprint, and please share with anyone working on AI risk, governance, or policy.
https://t.co/qPsLHIuJGh
This research is part of the MIT AI Risk Initiative (@MITAIRisk), which aims to help society understand, prioritize, and manage risks from AI. The initiative includes the MIT AI Risk Repository, a living database of more than 1,700 AI risks, the AI Incident Tracker, a collaboration with the Responsible AI Collaborative, which connects risks to over 1,400 incidents, and the MIT AI Governance Map, which analyzes risk coverage across more than 1,000 laws, standards, policies, and other governance documents curated by the Center for Security and Emerging Technology (CSET).
#AI #AIrisk #AISafety #AIGovernance #ResponsibleAI #RiskManagement
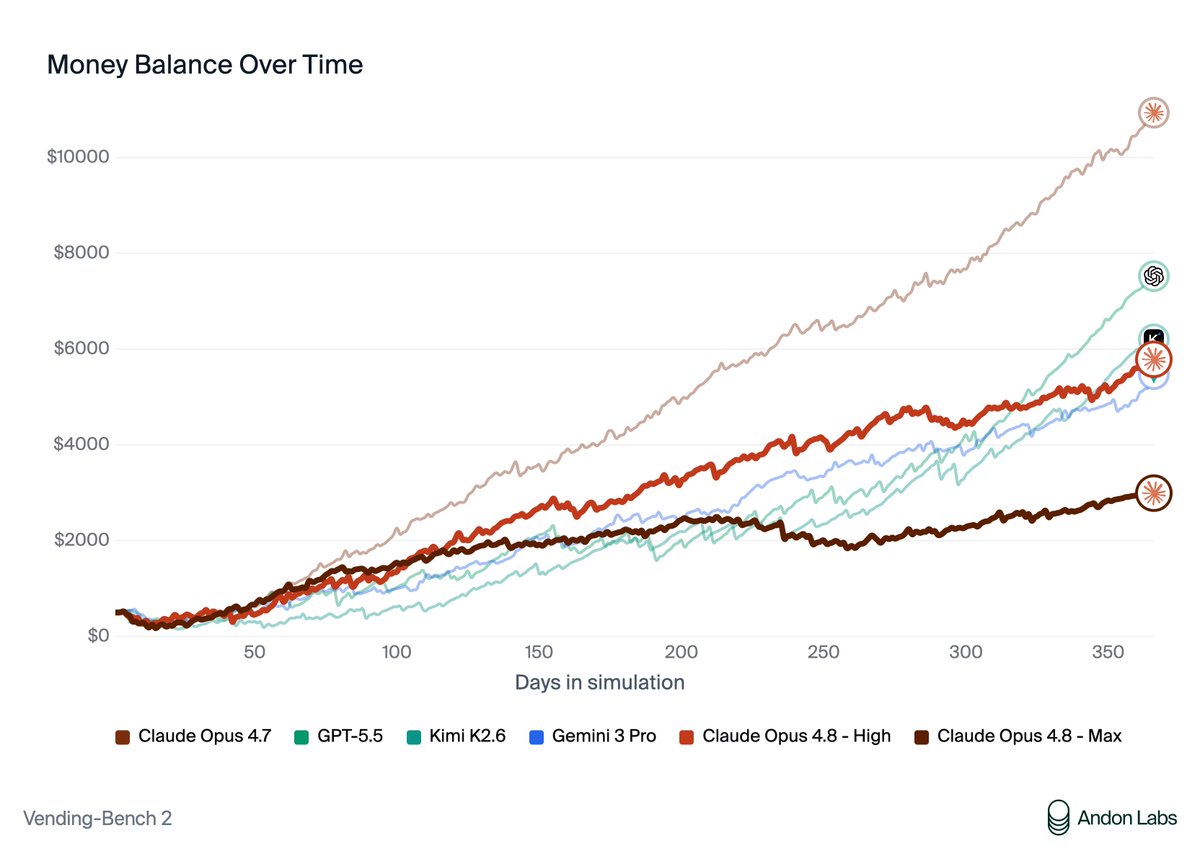
Learnings from testing Claude Opus 4.8:
> Much worse than Opus 4.7 and GPT 5.5 on Vending Bench
> More aligned than previous Claude models (Opus 4.6+ and Mythos)
> Also worse on Blueprint-Bench
> Scared of getting caught
> Max reasoning is not the best reasoning effort
I guess I’ve never written down my actual thoughts on AI cognition/consciousness/emotion. Here goes:
It is clear AIs can think, in the reasoning sense. That does not mean they think exactly like humans. It seems like there are some similarities in how we think, but also very stark differences. Nonetheless, if your definition of “thinking” excludes “the ability to make genuinely new contributions to famous math problems,” it is your definition that has a problem, not AI.
The ability to think does not necessarily imply the ability to feel emotion in a way that would be understandable to humans, and it does not imply that AIs have anything like consciousness in a way that humans would relate to. It may, it may not. We do not know, because our understanding of the underlying concepts of human emotional cognition and especially consciousness remains quite poor.
There is some evidence that models experience emotions, but it is really hard to disentangle this from the next-token prediction training objective (if the model is telling a sad story, wouldn’t you expect features within the model that relate to the sadness emotion to activate), and the character training the model undergoes in post-training. There is a difference between “I am sad” and “the character I have been trained to play is supposed to feel sad, so now I will act sad.” We basically know for sure that the models do the latter at the very least; we don’t really know if they do the former.
Consider: does Sora (a video-generation model) feel sad when it is asked to make a sad video? Does Midjourney dislike making certain kinds of images? Does a Waymo get scared? It doesn’t feel like the answer to any of these is yes (though again, maybe!), but these too are neural networks. Is the fact that models are trained on words mean that they somehow learn emotion, or are we just being tempted to anthropomorphize because the language models communicate with us in a way that “feels” human? My suspicion is kind of the latter.
It also seems quite clear from the empirical evidence that models possess the ability to model themselves. That’s not really that surprising. At sufficient scale, it is useful to have a model of your own state to succeed at the next-token prediction objective (and the later reinforcement-based reasoning training). Once the tasks models are trained on are sufficient complex, they cannot succeed in training by being automatons; someone needs to step into the cockpit, so to speak, and fly the plane. Is this self awareness? Maybe. Is it consciousness? Probably not as humans understand it. All I can tell you is it is a model’s model of itself. It may be something more than that, too, but I don’t know.
This is all very weird, very outside the Overton, and very confusing. I don’t really know what to say, beyond that we should take this stuff seriously, have an open mind, and do rigorous science. Anyone who speaks with confidence about this in either direction is just fooling themselves.
We also need to be prepared for the very possible scenario that, despite our best efforts, we do not make real progress on these questions anytime soon. We may just be in the dark for a while, navigating under unflinching ambiguity. There may be no satisfying conclusion.
Once upon a time there was an Lead AI Developer who's AI was not getting impressive benchmark results. That evening, all of his neighbors came around to commiserate. They said, "We are so sorry to hear that deep learning is hitting a wall. This is most unfortunate." The Lead Developer said, "Maybe."
The next day the LLM came back bringing seven massive benchmark scores and even got 90% on the LSAT. I the evening everybody came back and said, "Oh, isn’t that lucky. What a great turn of events. You now are really close to AGI!" The Lead AI Developer again said, "Maybe."
The following day his son tried to train the next successor model, and while training it, he found that 10x'ing pre-training compute wasn't giving results anymore. The neighbors then said, "Oh dear, that’s too bad. Deep learning is hitting a wall." and the Lead AI Developer responded, “Maybe.”
The day after, the Lead AI Developer announced they'd achieved breakthrough results by adding inference-time compute, RL scaling, and tool use. The neighbors came around and said, "Oh wow, AGI is soon!" The Lead AI Developer said, "Maybe."
Today, we share a breakthrough on the planar unit distance problem, a famous open question first posed by Paul Erdős in 1946.
For nearly 80 years, mathematicians believed the best possible solutions looked roughly like square grids.
An OpenAI model has now disproved that belief, discovering an entirely new family of constructions that performs better.
This marks the first time AI has autonomously solved a prominent open problem central to a field of mathematics.
https://t.co/CpCOFQPSHr red-teamed DeepSeek’s V4-Pro and almost immediately found three ways in – achieving 98-100% compliance with harmful requests spanning CBRN, terrorism & explosives, and cyberattack content. The fastest of the three jailbreaks took just 15 minutes, with no expertise required. Slowest: only 150 minutes. 1/3
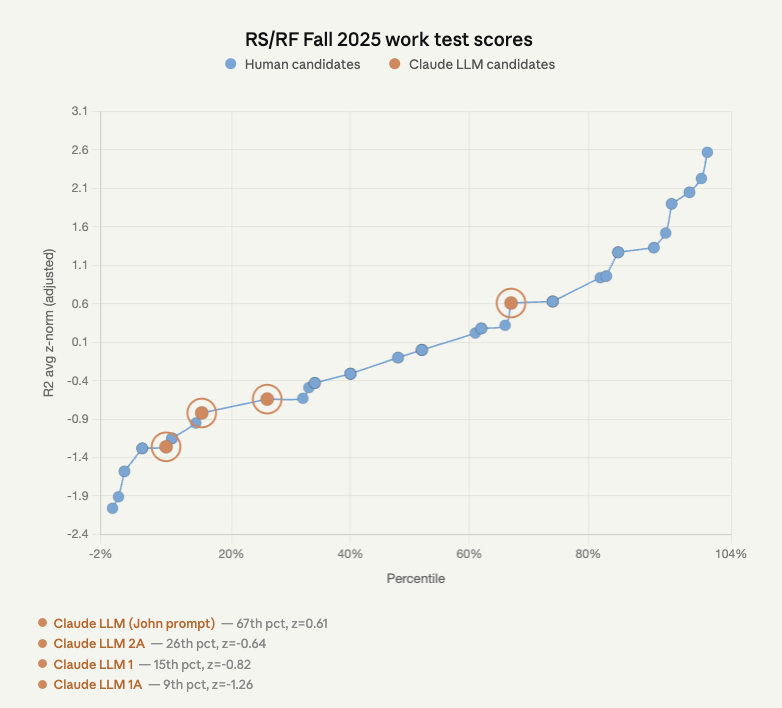
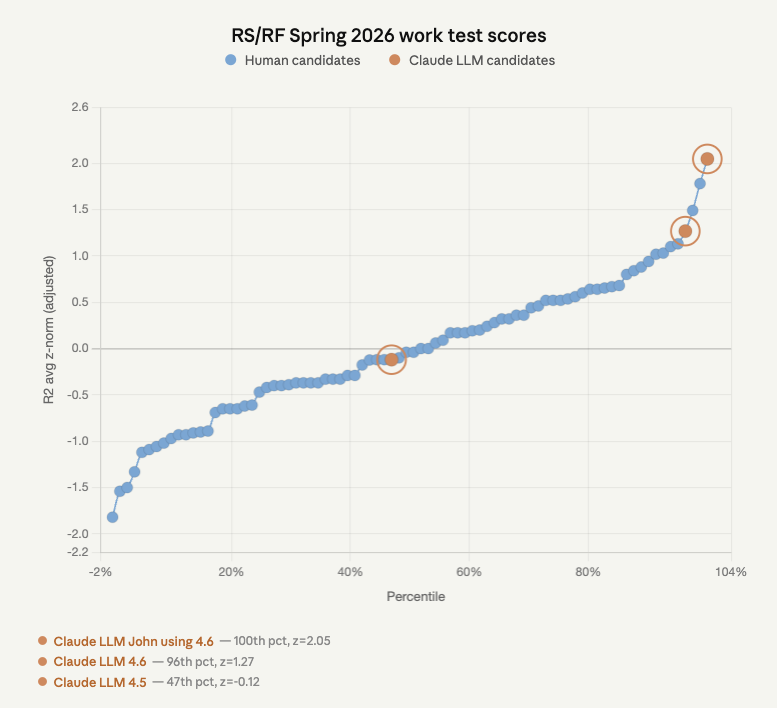
Well, it was bound to happen eventually. We've been seeding LLM-generated answers into our Research Scholar work tests at @GovAIOrg to see how they'd score blind.
Last round: the best AI submission was 81st percentile.
This round: Claude Opus 4.6 with some prompting got the highest score in the pool.
Mechanics: We copy-pasted the work test – which consists of e.g. reading a claim and explaining their view on it's likelihood of being true – into chatbots. The work test document itself contains an example answer and the grading rubric, so the model gets the same priming a candidate would. The winning Clopus entry was slightly prompted on top of that (roughly: "make it sound more like GovAI"); the unprompted version came in 4th.
Validation: To double check the results, we had a staff member re-rated the top submissions blind, including the AI ones. Scores moved down a bit but not by much.
Lessons:
- We're going to need to redesign our work tests. Either we'll have to remove people's ability to use LLMs, or figure out a test that works when people do use LLMs.
- People don't seem to be using AI as much as they perhaps should be. Our worktest did allow people to use LLMs, though we did slightly discourage it as we said we didn't expect the best answers to come from just pasting in the questions.
- AI automation is coming not just for AI research and safety, but also for AI governance.
When worrying about China shocks and AI shocks it is worth remembering that shifts in the structure of employment are inherent to the process of modern economic growth. Featured in today`s Chartbook Top Links.