In my latest blog post, I tackle @karpathy's 'Let's build GPT' to construct a transformer 🤖 model from scratch, leveraging the foundational knowledge I gained from the fantastic @fastdotai courses by @jeremyphoward.
Curious about how transformers work?
https://t.co/1COGUreolz
Building AI products is hard. But it's getting increasingly popular!
I'm really excited to share that my friends and I are putting together (the best) lecture series on AI Product Engineering this summer!! We've got an awesome lineup of talks spanning data, evals, and UX. With more to come.
The lecture series is completely free! And ~2k people have signed up already even though we haven't posted on social media yet! I can't wait. Join us and sign up: https://t.co/5DWcm4va5m
Sharing the full deployment dialog and some thoughts.
I wanted to see how quickly I could deploy a cool model I saw on twitter (image to 3D model) using solveit & aai libs. Very pleased with the result!
I used:
- fastspec: https://t.co/TcJ4qBi6WG - bgtmux: https://t.co/en56332x7D
Deployed to a google cloud platform GPU.
The whole process transfers very nicely to other cloud providers or models.
Fastspec turns an OpenAPI file into a python sdk.
Bgtmux lets solveit drive a terminal (tmux) session that you can connect to and is super conveninet to let connect to the remote VM and iron out deployment issues directly. You can also use it to connect to your own machine for local stuff.
The dialog works also as guide to GCP including enabling, services, requesting quotas etc... (which is notoriously annoying) through the API
Bgtmux is amazing for these cases. I spun up a GPU, let solveit connect to it and then watched it iron out all the annoying deployment bits (like version pinning, incompatible, missing libs, and all that stuff). Quite token hungry though
If someone reads it and finds it confusing or has any improvement advice (for readibility / sharing) please lmk!!
https://t.co/8gZtftwRoG
We just released Omnigent 0.2 with a ton of improvements from the past 5 days! Here's what's new according to Omnigent. Major additions are @cursor_ai CLI and @antigravity harnesses, lots of new sandbox providers, and secret-free sandboxing via API proxy. https://t.co/4OeQTV863E
Incredible how Z. ai literally has their RL infrastructure open source.
The entire OPD post-training of GLM-5.2 took on this slime platform took ~2 days.
https://t.co/XVjW6rGcbg
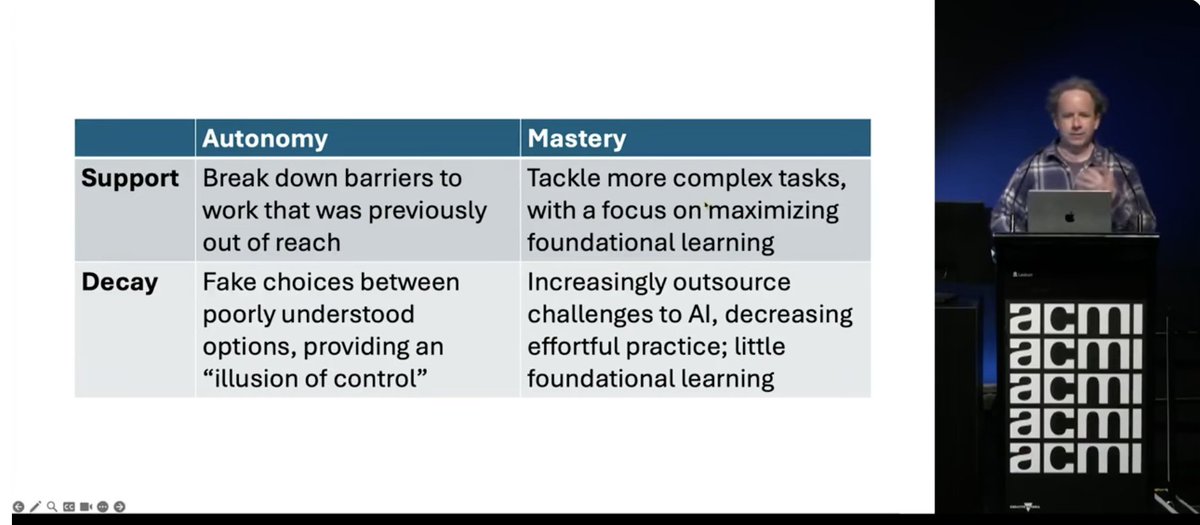
"Mastery is not about creating more outputs or products. It is about building genuine ability. AI can either decay or support human mastery.
The people selling you AI models & your bosses at work don’t care about your mastery. They will put you in the decay world every time."
It seems like LLMs could optimize coding style by exploring ways of structuring code so weaker and weaker models can still successfully perform tasks in a codebase.
There are surely stylistic quirks that are peculiarly impactful to transformers, but I bet there would be a lot of overlap with human capabilities.
Optimizing for understanding should help even the top frontier models, allowing them to understand things “at a glance” without having to explicitly explore. There will remain “better” and “worse” ways to code.
For over a decade, we’ve accepted that end-to-end backprop is the only way to train deep networks. But holding the entire network in memory all at once is why AI training is hitting a resource wall.
We found a new way to break the network into blocks and train them independently. The trick? Treating the network’s forward pass like a diffusion model denoising a signal.
This reinterpretation slashes the memory needed to train deep models. In our #ICLR2026 paper (https://t.co/PK5h0mqQSo), we matched end-to-end performance across ViTs, DiTs, and LLMs. We did this while training just one isolated block at a time.
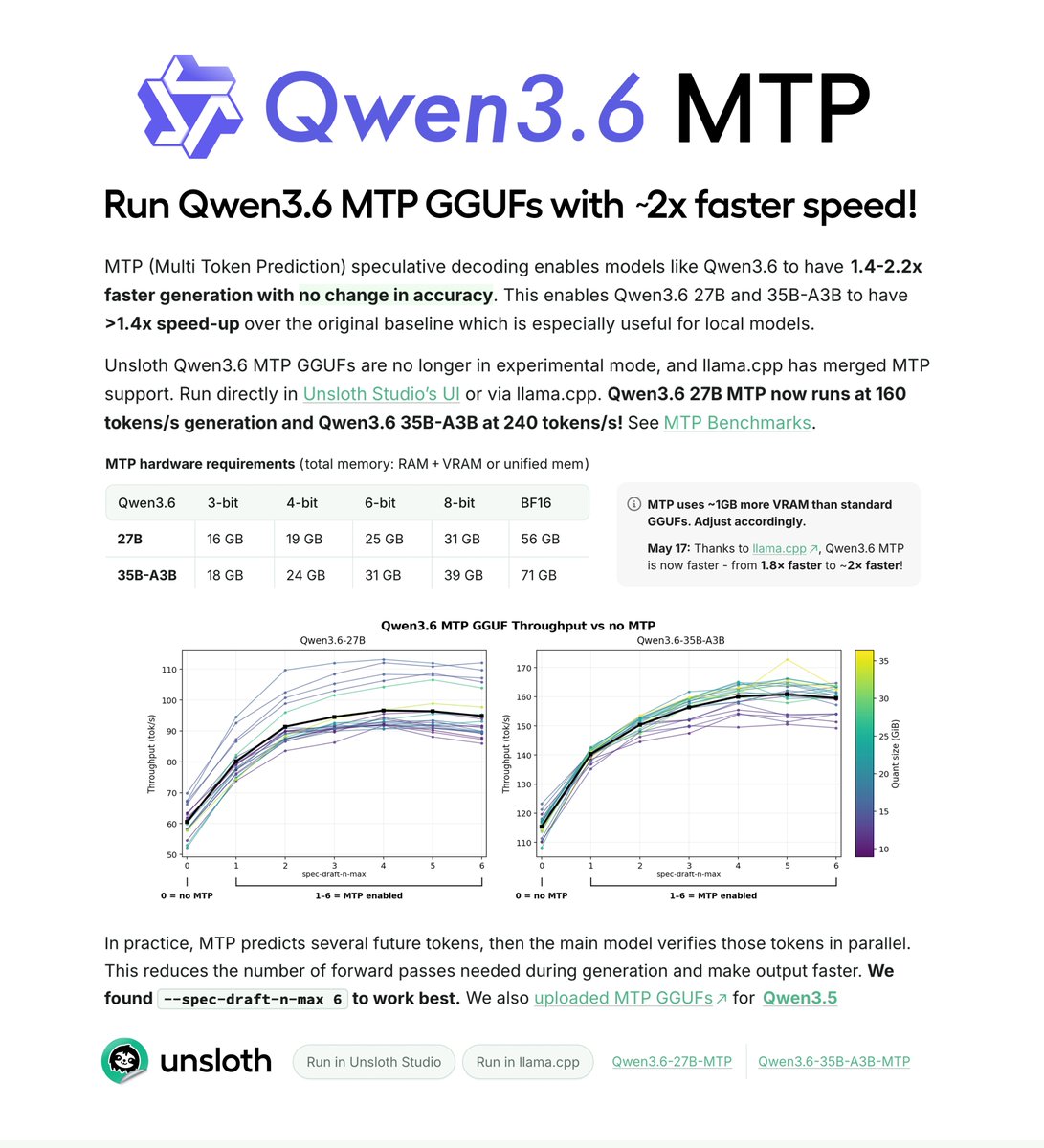
Qwen3.6 now runs 2x faster with MTP GGUFs! Run locally on just 18GB RAM. ⚡️
MTP enables Qwen3.6 to generate ~1.4–2.2× faster with no accuracy change.
Qwen3.6-27B MTP runs at 160 tokens/s. 35B-A3B reaches 240 t/s.
GGUFs: https://t.co/7gWhKnseZo
Guide: https://t.co/7qzk6ypWDQ
Today we release Token Superposition Training (TST), a modification to the standard LLM pretraining loop that produces a 2-3× wall-clock speedup at matched FLOPs without changing the model architecture, optimizer, tokenizer, or training data.
During the first third of training, the model reads and predicts contiguous bags of tokens, averaging their embeddings on the input side and predicting the next bag with a modified cross-entropy on the output side. For the remainder of the run, it trains normally on next-token prediction. The inference-time model is identical to one produced by conventional pretraining.
Validated at 270M, 600M, and 3B dense scales, and at 10B-A1B MoE.
The work on TST was led by @bloc97_, @gigant_theo, and @theemozilla.
People talk, listen, watch, think, and collaborate at the same time, in real time. We've designed an AI that works with people the same way.
We share our approach, early results, and a quick look at our model in action.
https://t.co/AFJZ5kH7Ku