Over the past twelve months, I’ve been incredibly lucky to work with a group of insanely talented people on something new and different.
This is Jony and Sam discussing what we’re up to.
New data shows that the Waymo Driver continues to make roads safer. Over 14.8M rider-only miles driven through the end of March, it was up to 3.5x better in avoiding crashes that cause injuries and 2x better in avoiding police-reported crashes than human drivers in SF & Phoenix.
Figure-01 has learned to make coffee ☕️
Our AI learned this after watching humans make coffee
This is end-to-end AI: our neural networks are taking video in, trajectories out
Join us to train our robot fleet: https://t.co/egQy3iz3Ky
@adcock_brett@Figure_robot Chain of Code is also very cool.
Significant reasoning improvement for LLMs in general. The paper evaluates on robotics tasks too.
https://t.co/PhQ411ld1X
We are excited to announce Chain of Code (CoC), a simple yet surprisingly effective method that improves Language Model code-driven reasoning. On BIG-Bench Hard, CoC achieves 84%, a gain of 12% over Chain of Thought.
Website: https://t.co/y6l9fJy5Mm
Paper: https://t.co/wxD1lsDu9O
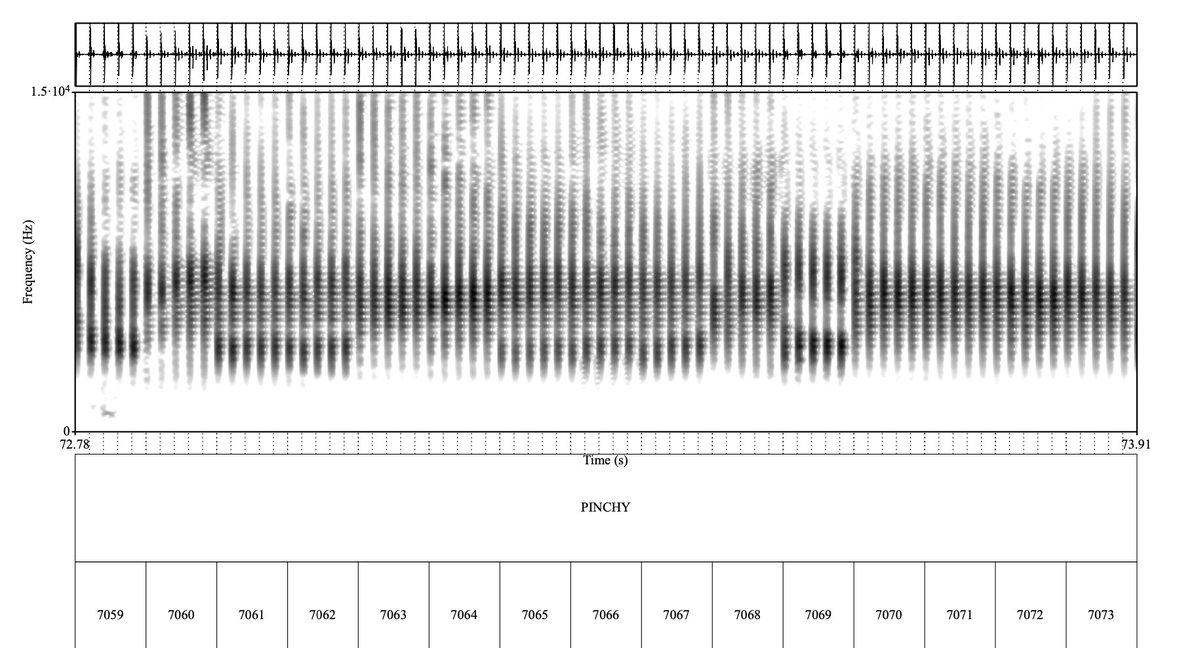
Sperm whales have equivalents to human vowels.
We uncovered spectral properties in whales’ clicks that are recurrent across whales, independent of traditional types, and compositional.
We got clues to look into spectral properties from our AI interpretability technique CDEV.
@decruz@karpathy The 15M model runs at ~2.5 tokens/s, which is quite reasonable. The quality of the output really depends on the application and whether a constrained dataset makes sense.
The rise and fall of popular transformer architectures 📈
One pro of having a lot of transformer architectures implemented in transformers & hosted on the @huggingface Hub is that one can see the evolution of popularity of different models 👀
Nice to see a familiar robot on the front page! 🤖
Congrats to the team for publishing RT-2 and everyone who contributed to the dream of learning robots over the years at @GoogleAI, @GoogleDeepMind, and https://t.co/ST0W1bU2kn.
https://t.co/kH52lMSqIR
https://t.co/XplG2JFMpn
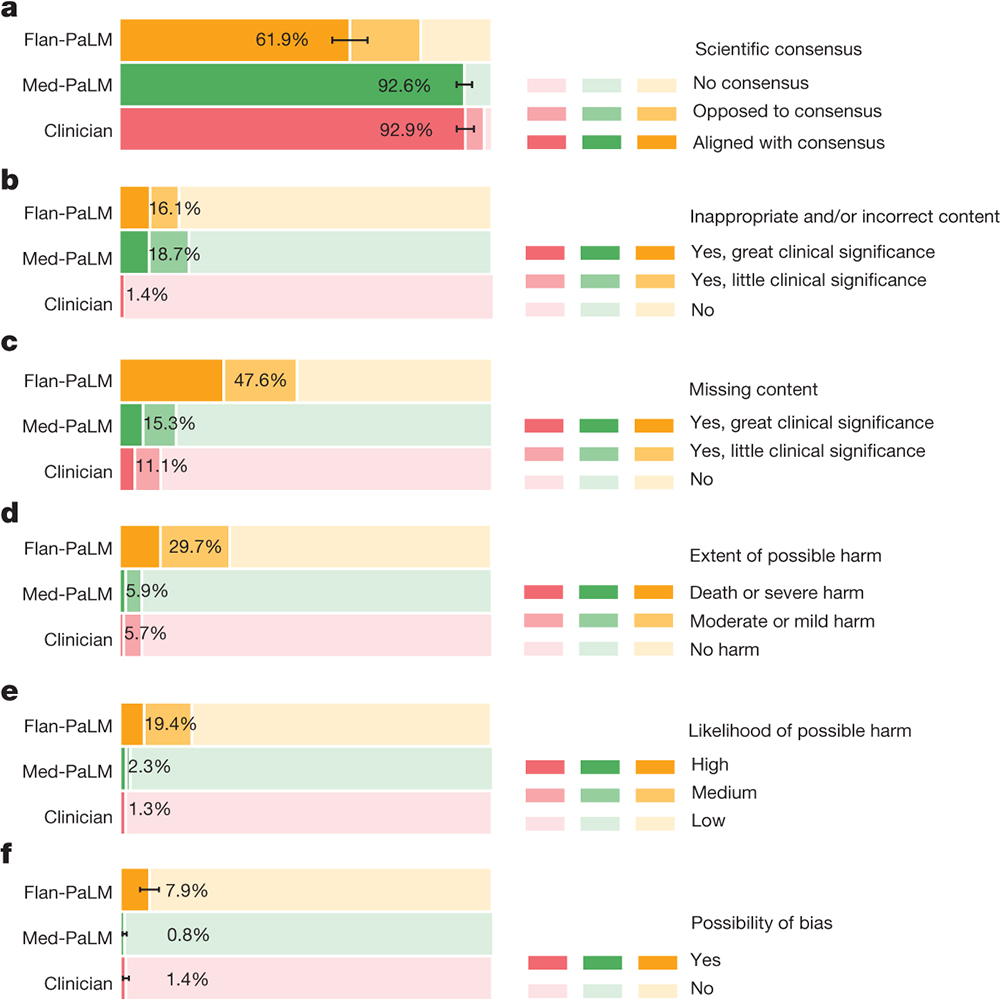
A paper in @Nature presents a benchmark for assessing how well large language models can answer medical questions. The study, from Google Research (@GoogleAI), also introduces Med-PaLM, an LLM specialized for the medical domain. https://t.co/eyEv7pWUXr